%%{init: {"theme": "white", "themeVariables": {"fontSize": "48px"}, "flowchart":{"htmlLabels":false}}}%%
flowchart TD
N[Number of Users] --> N_active[Number of Active Users]
N_active --> Retention[Retention]
Retention --> Revenue[Revenue]
Cohort Revenue & Retention Analysis: A Bayesian Approach
Machine Learning Week - 2023
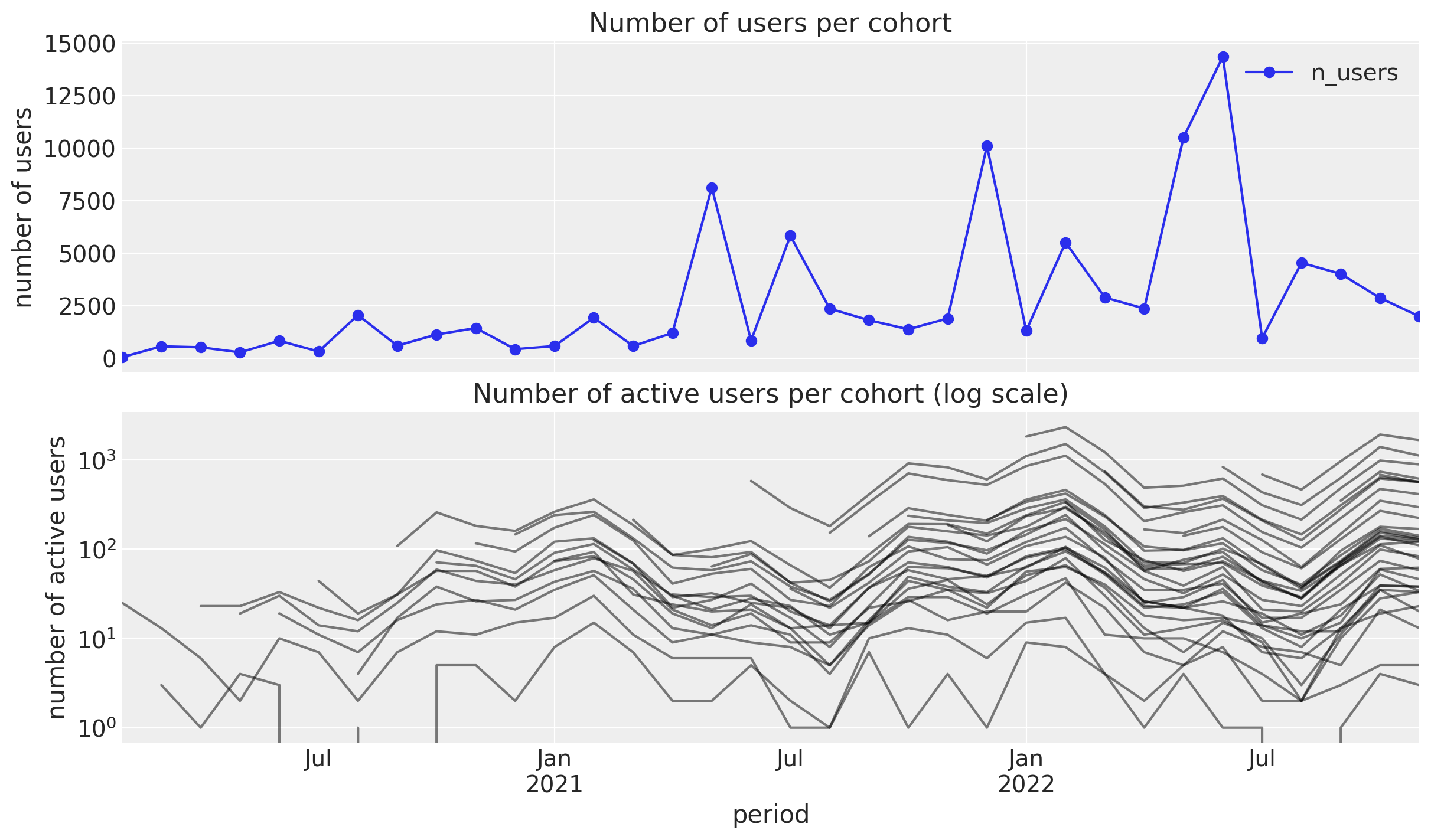
Number of Active Users
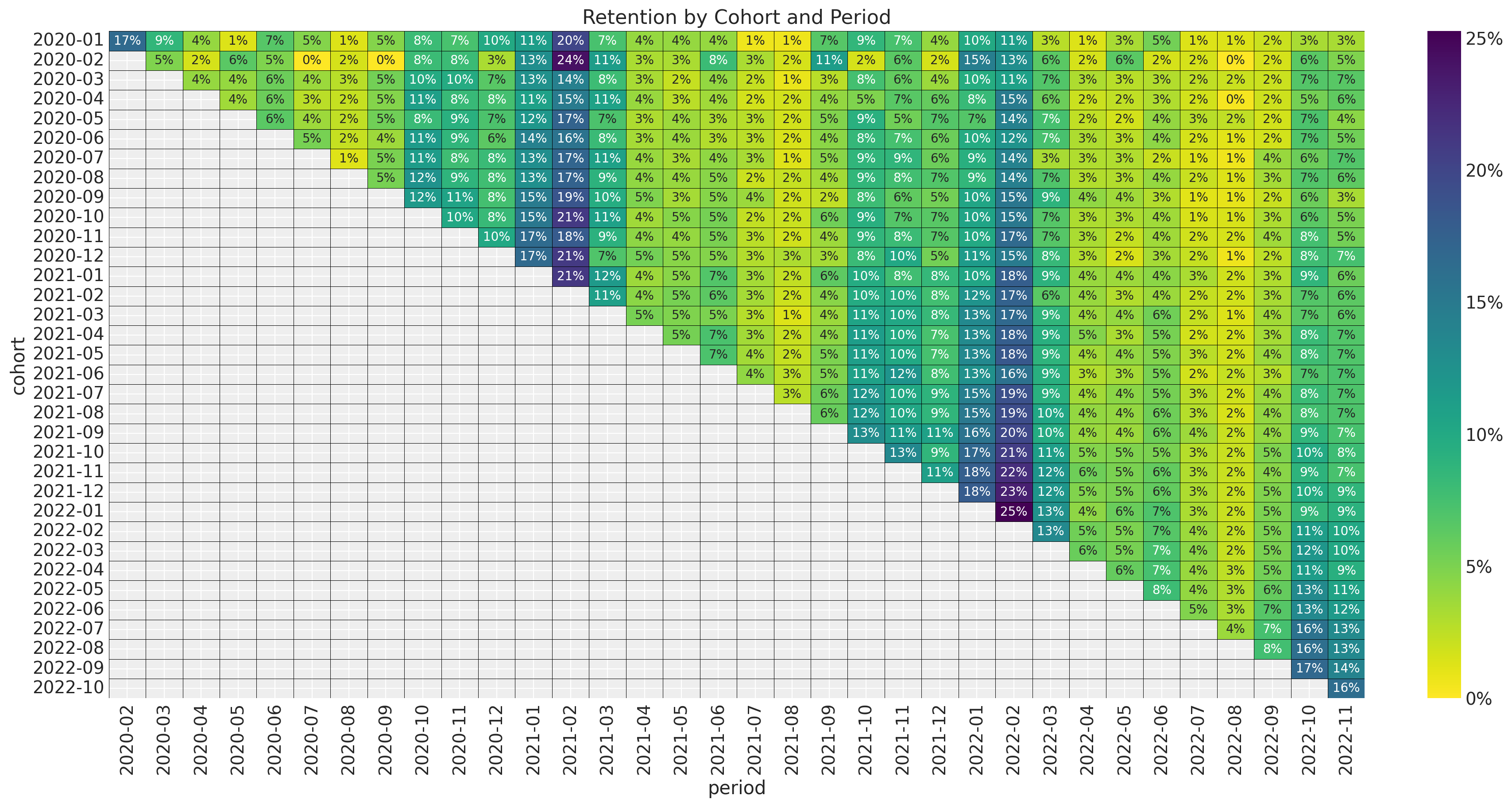
Retention Matrix
Some Bottom-Up Approaches
Shifted Beta Geometric (Contractual)
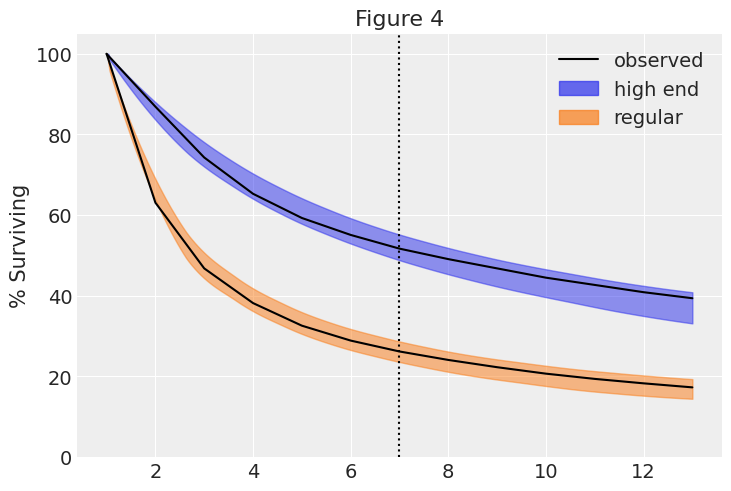
An individual remains a customer of the company with constant retention probability \(1 - \theta\).
Heterogeneity: \(\theta \sim \text{Beta}(a, b)\).
BG/NBD Model (Non-Contractual)
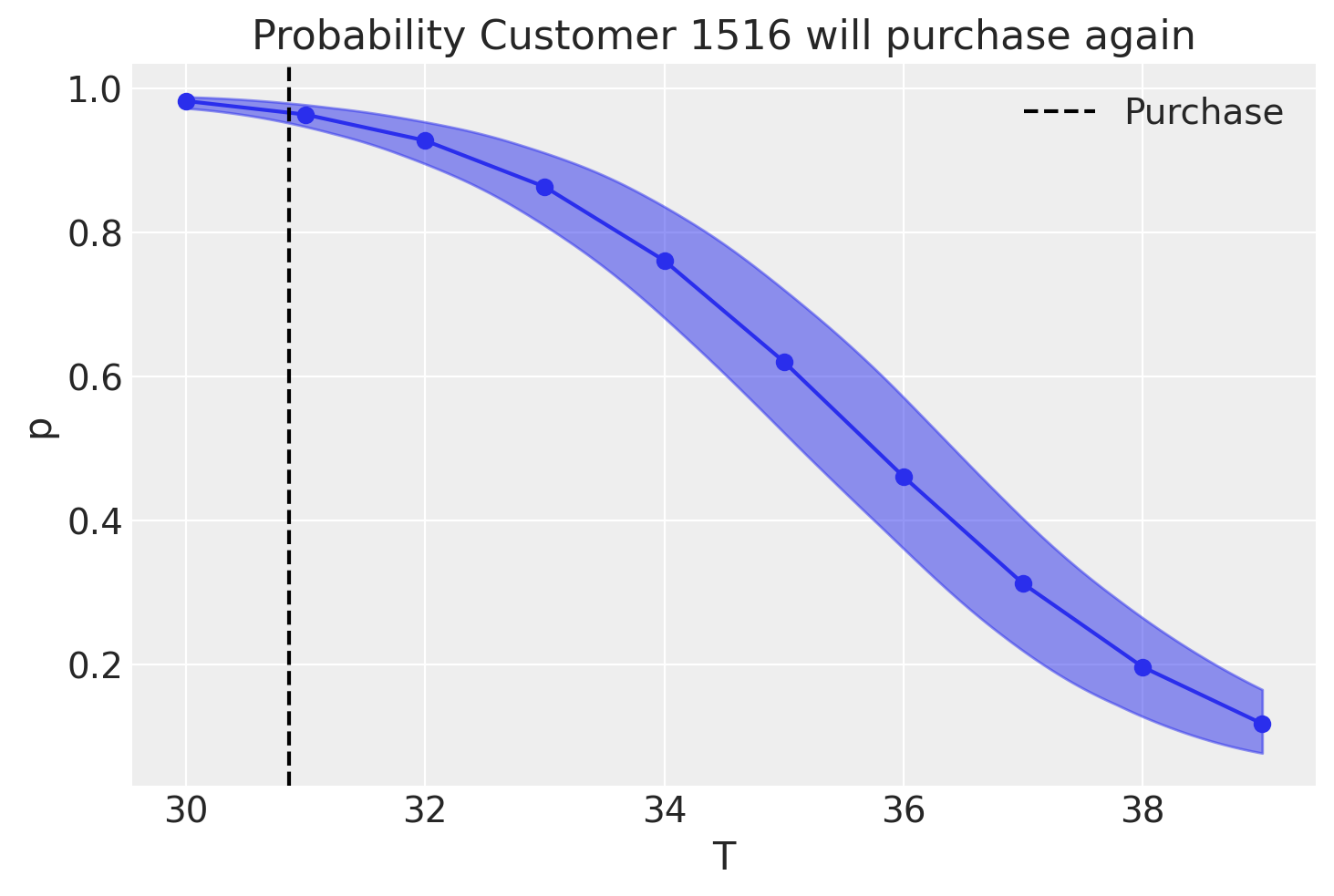
- Transaction process: \(\lambda \sim \text{Gamma}(r, \alpha)\).
- Dropout probability: \(p \sim \text{Beta}(a, b)\).
Model the Retention Matrix 💡
- Cohort Age: Age of the cohort in months.
- Age: Age of the cohort with respect to the observation time.
- Month: Month of the observation time (period).
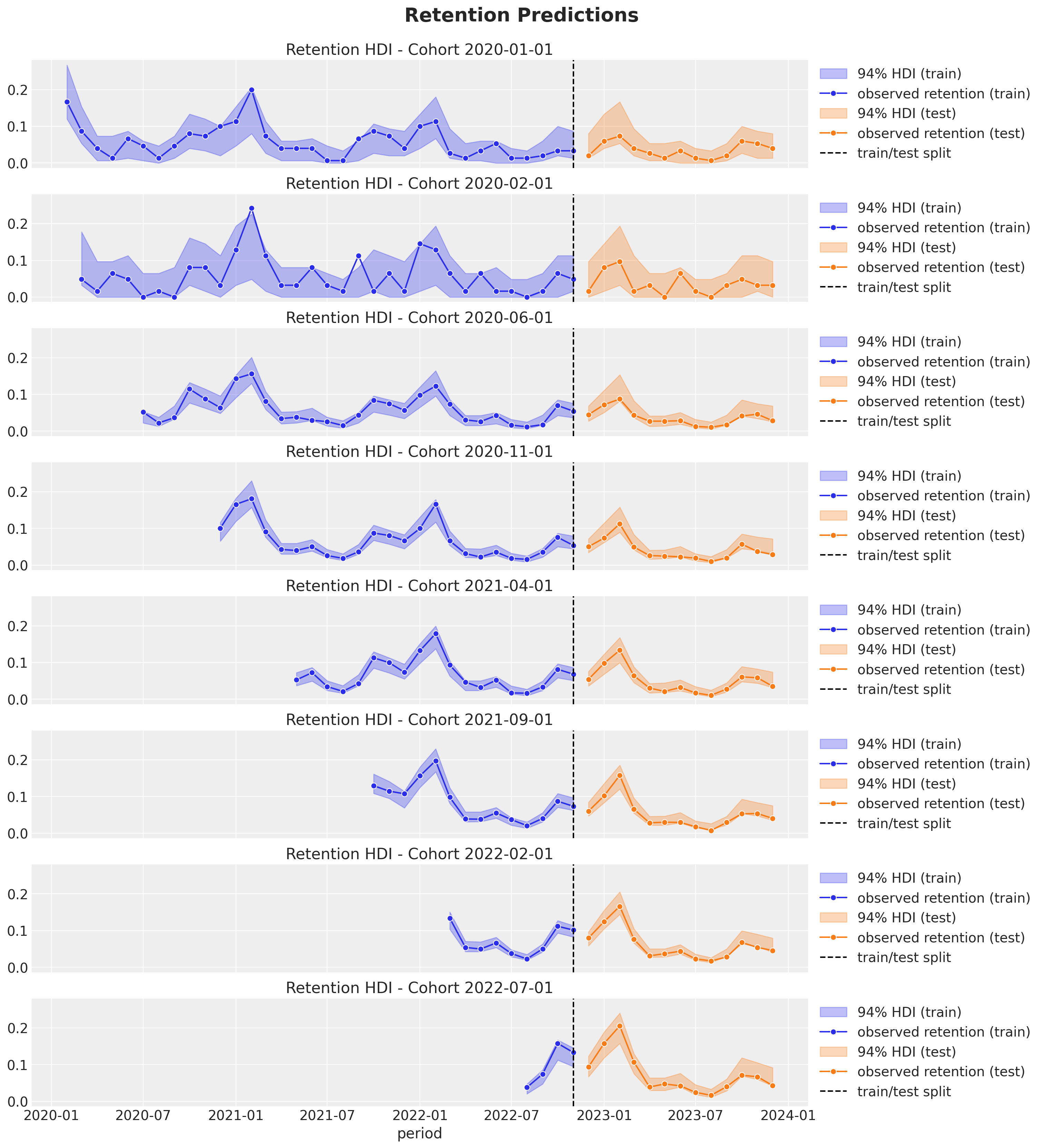
Retention Over Time (period)
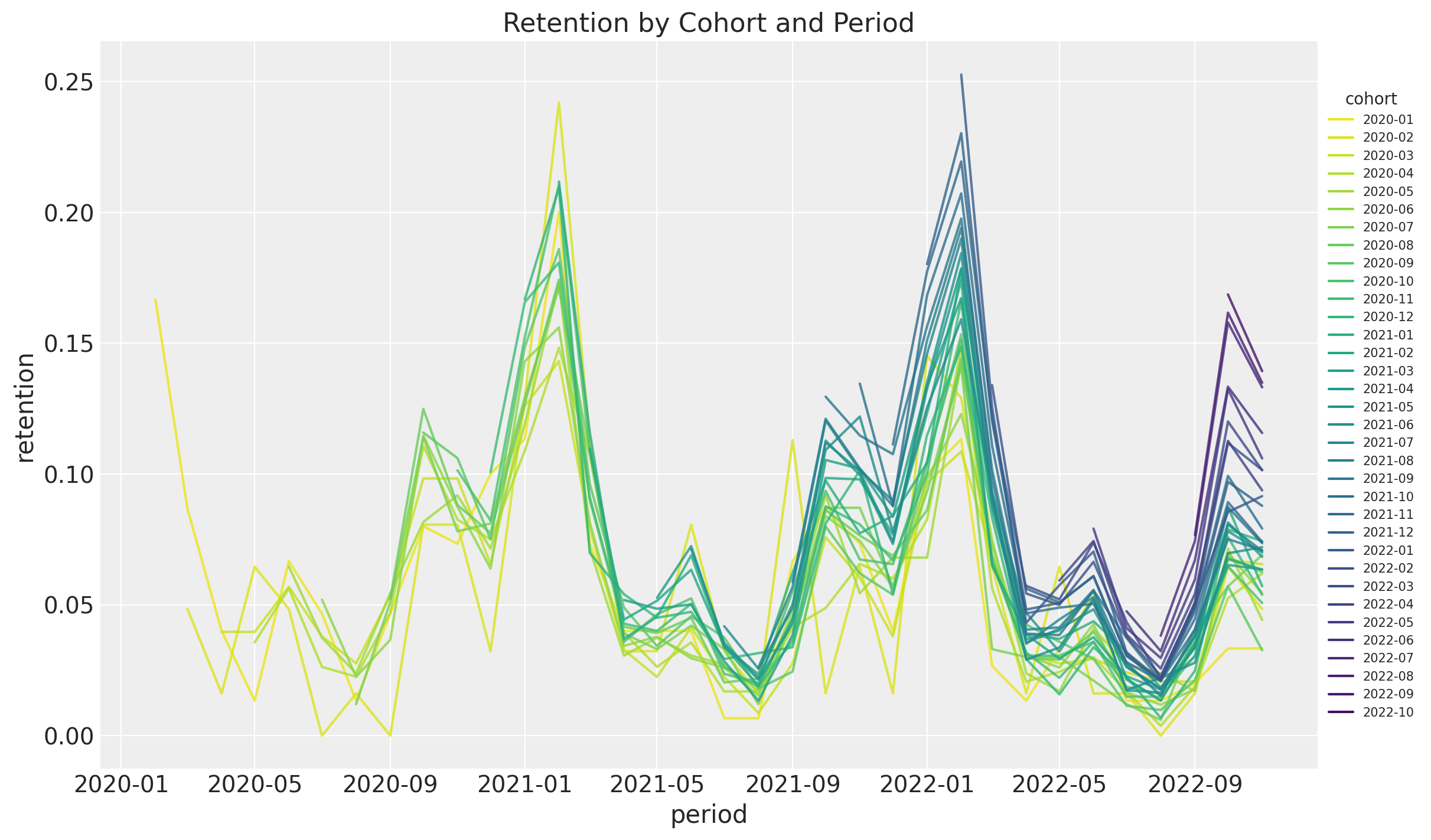
Modeling Strategy: Close cohorts behave similarly.
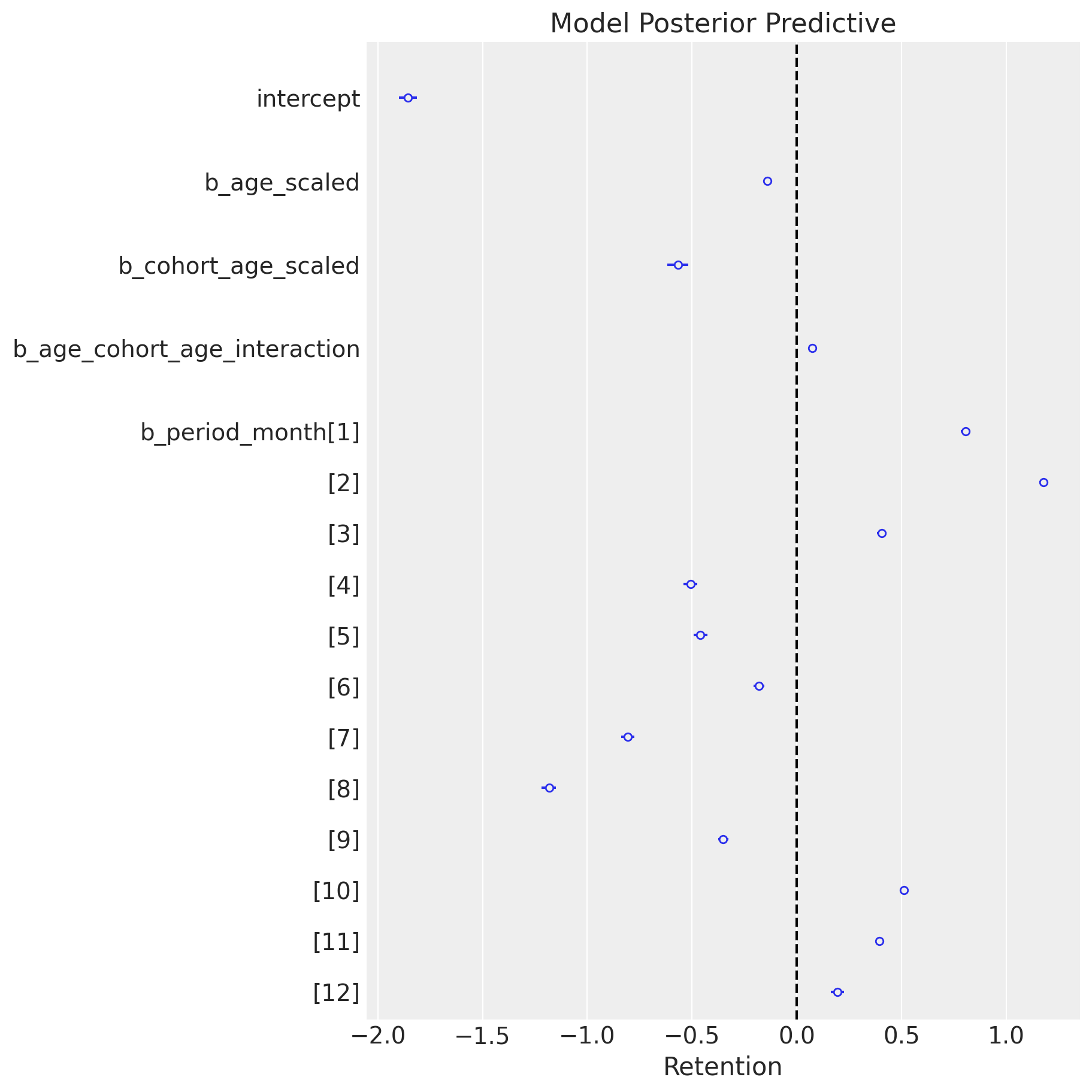
Retention - GLM in PyMC

Posterior Distribution
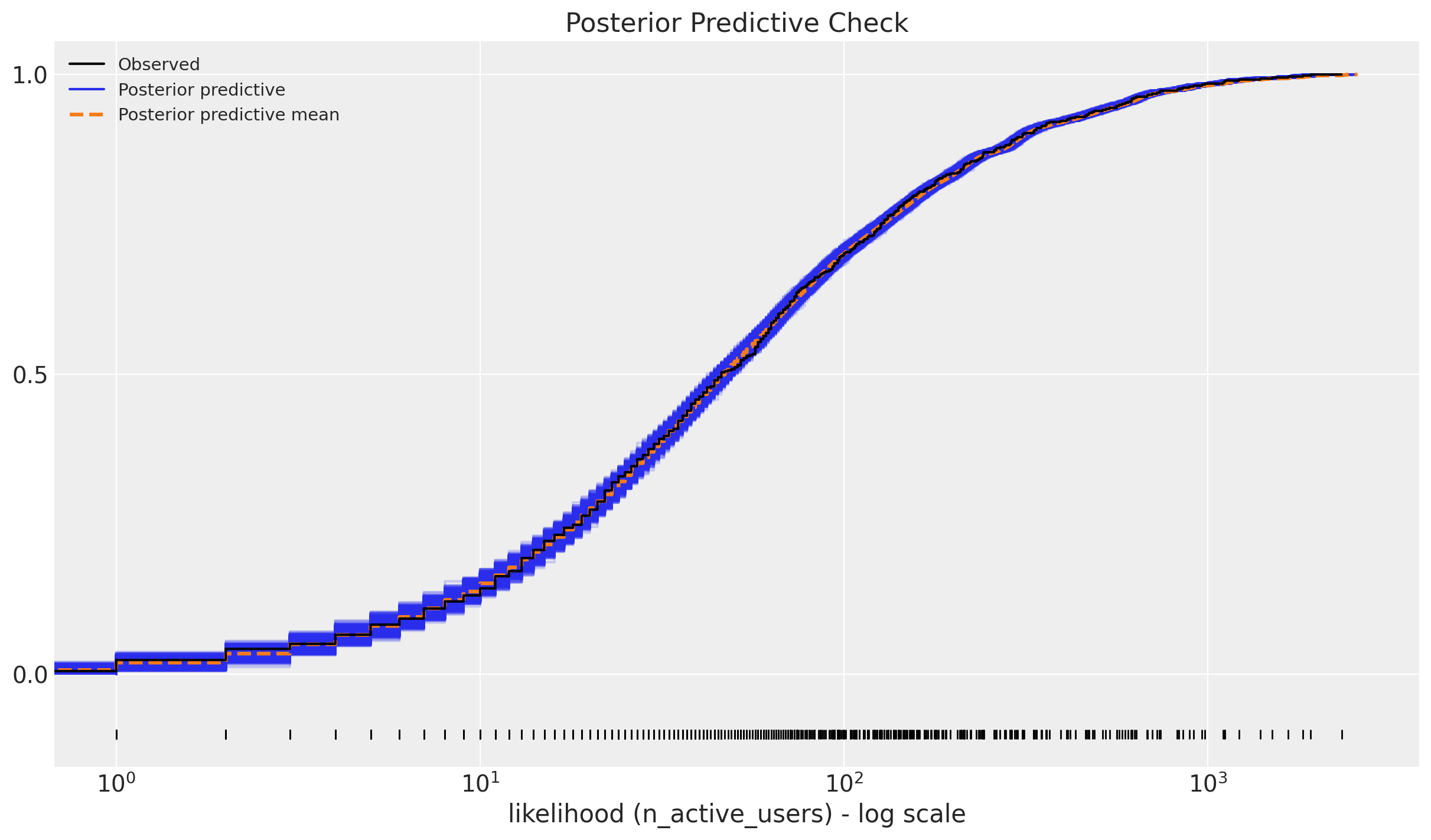
Posterior Predictive Check
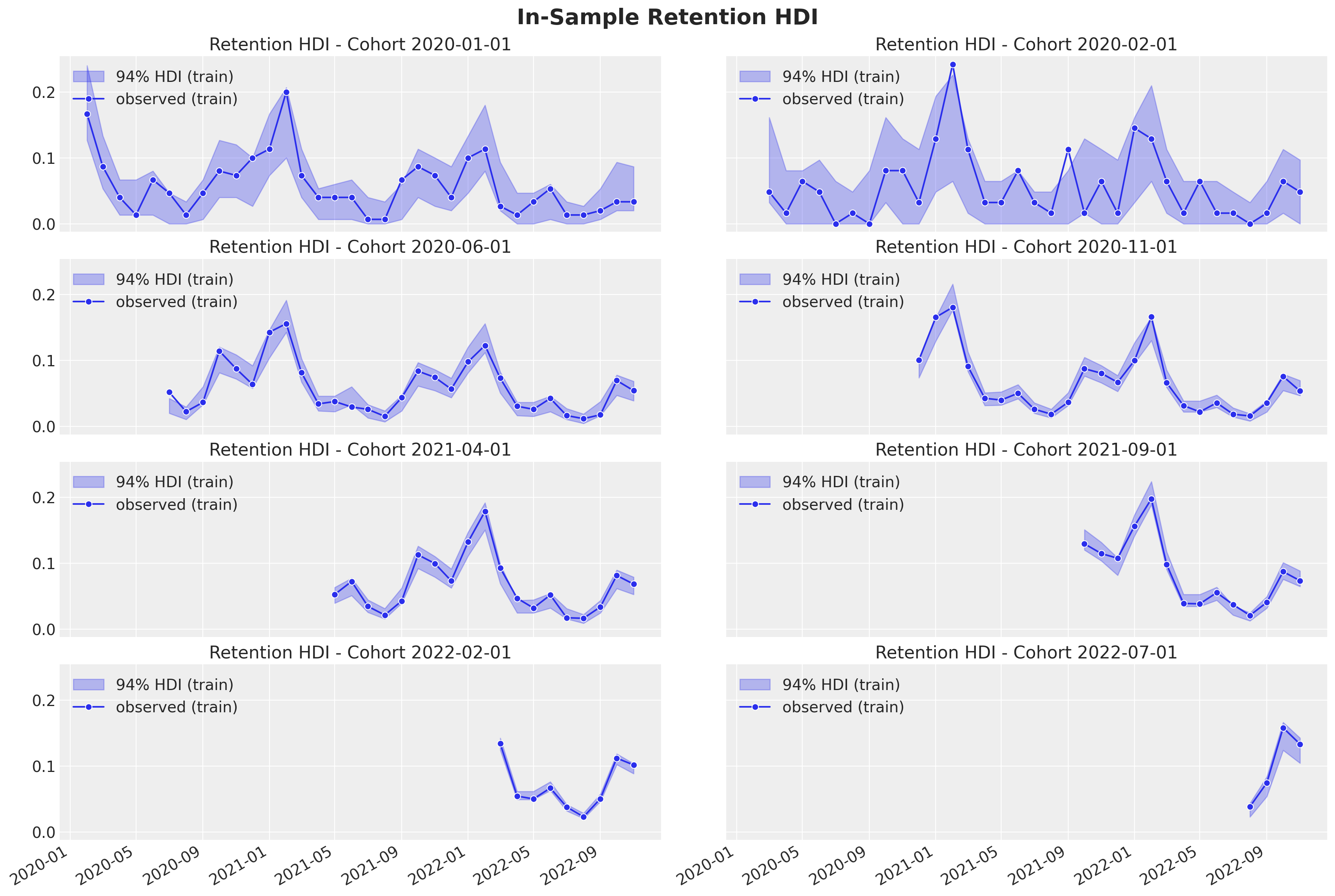
In-Sample Predictions
Out-of-Sample Predictions
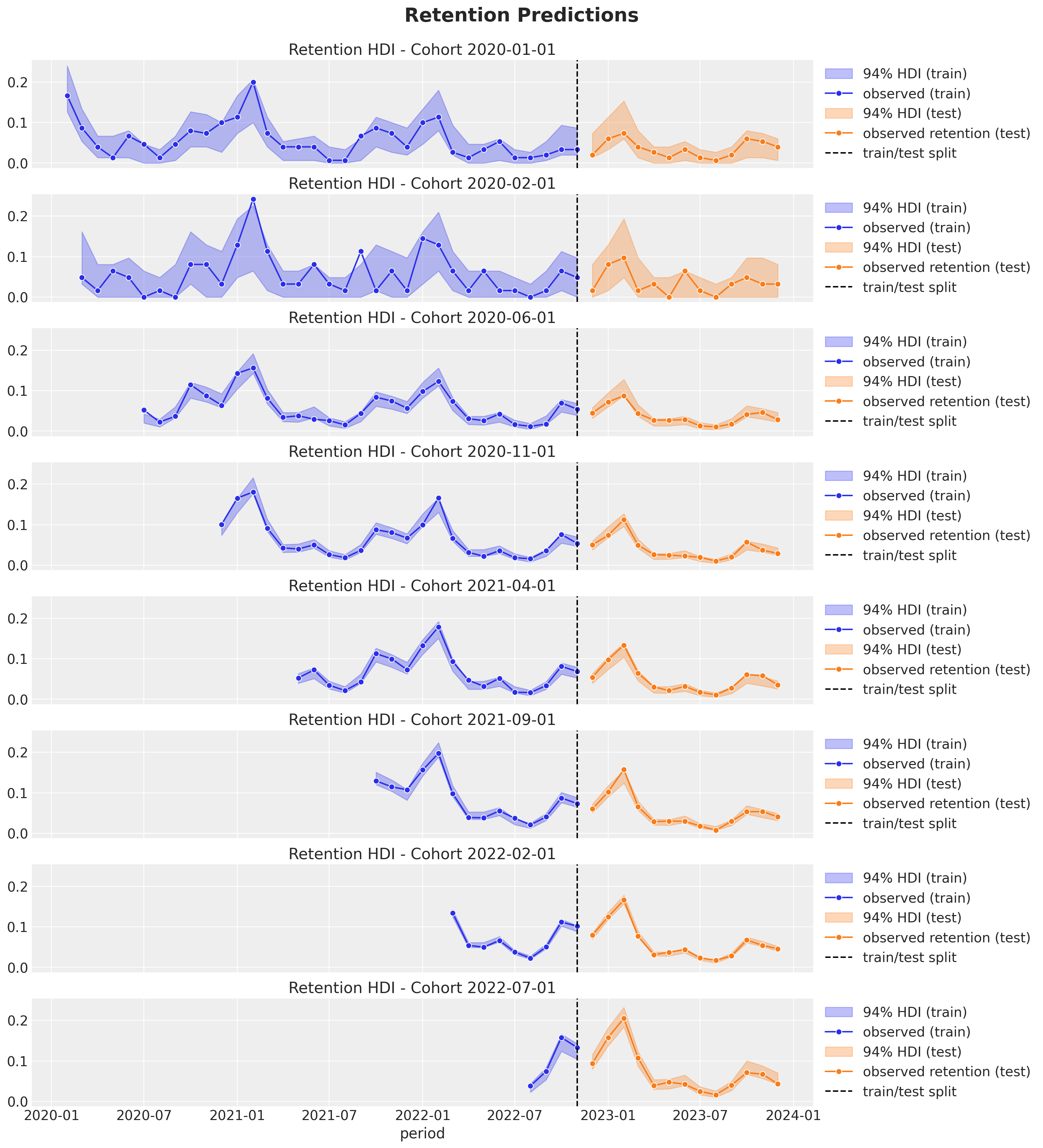
BART Retention Model
\[\begin{align*} N_{\text{active}} & \sim \text{Binomial}(N_{\text{total}}, p) \\ \textrm{logit}(p) & = \text{BART}(\text{cohort age}, \text{age}, \text{month}) \end{align*}\]

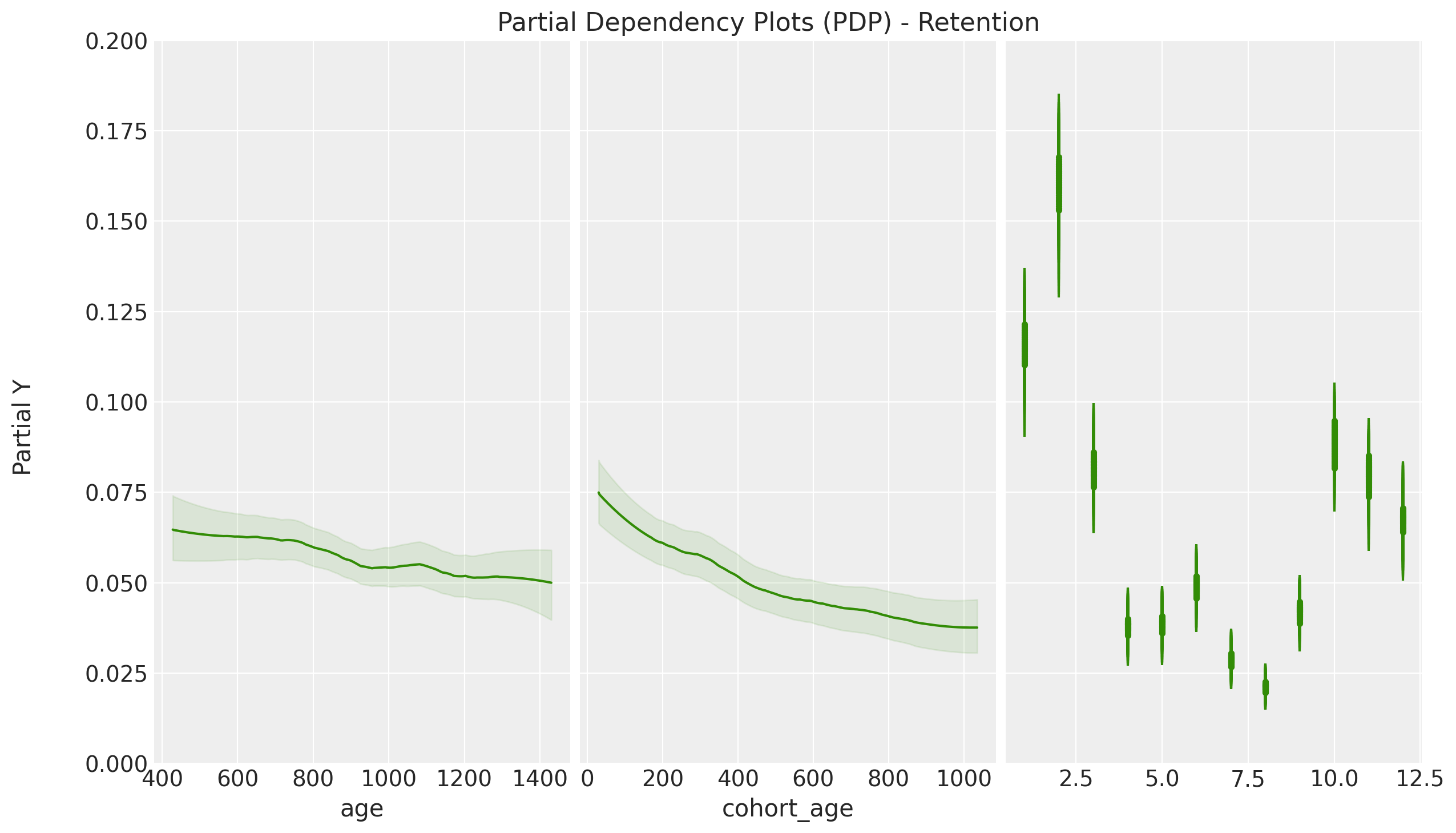
PDP Plot
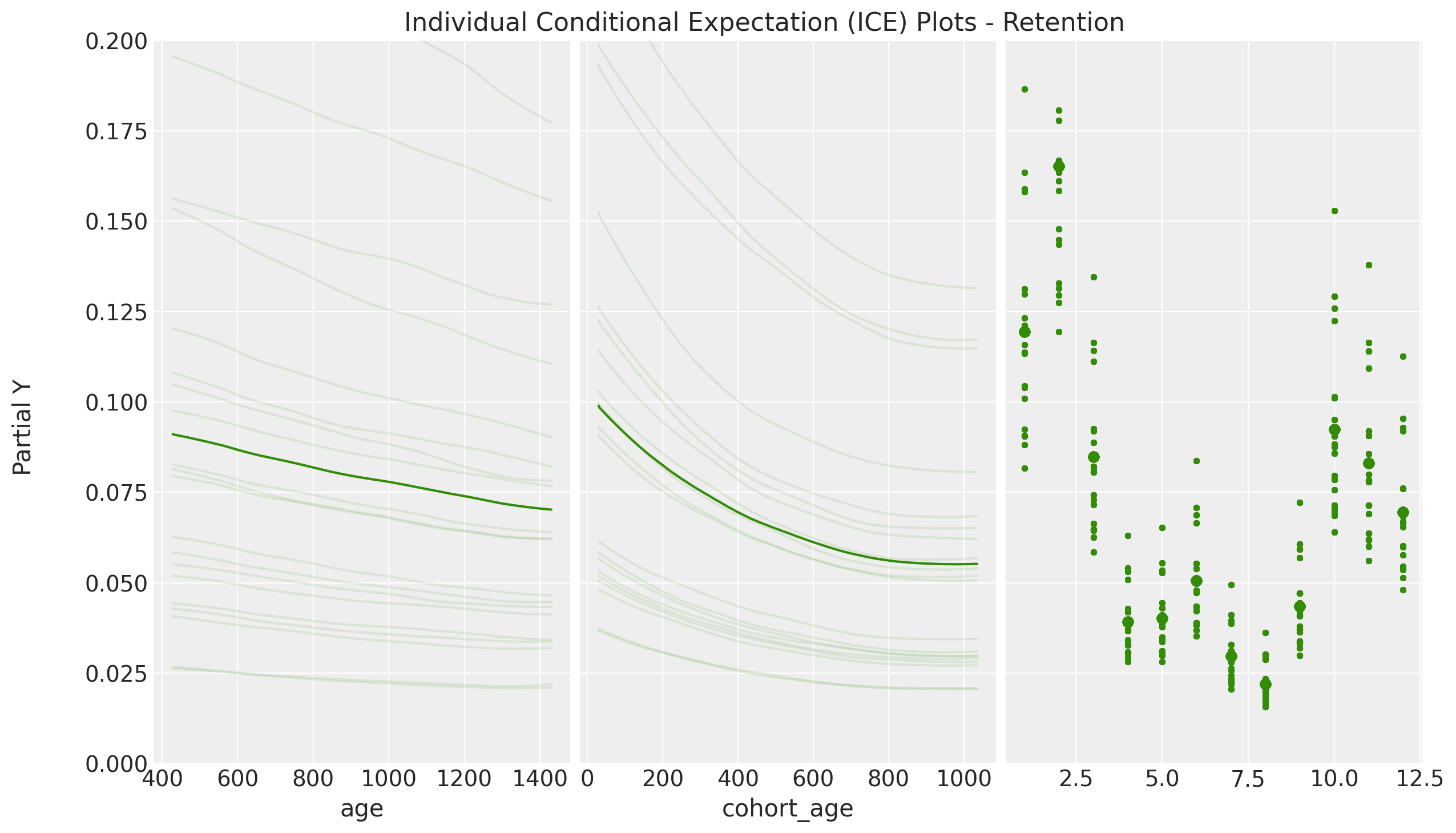
ICE Plot
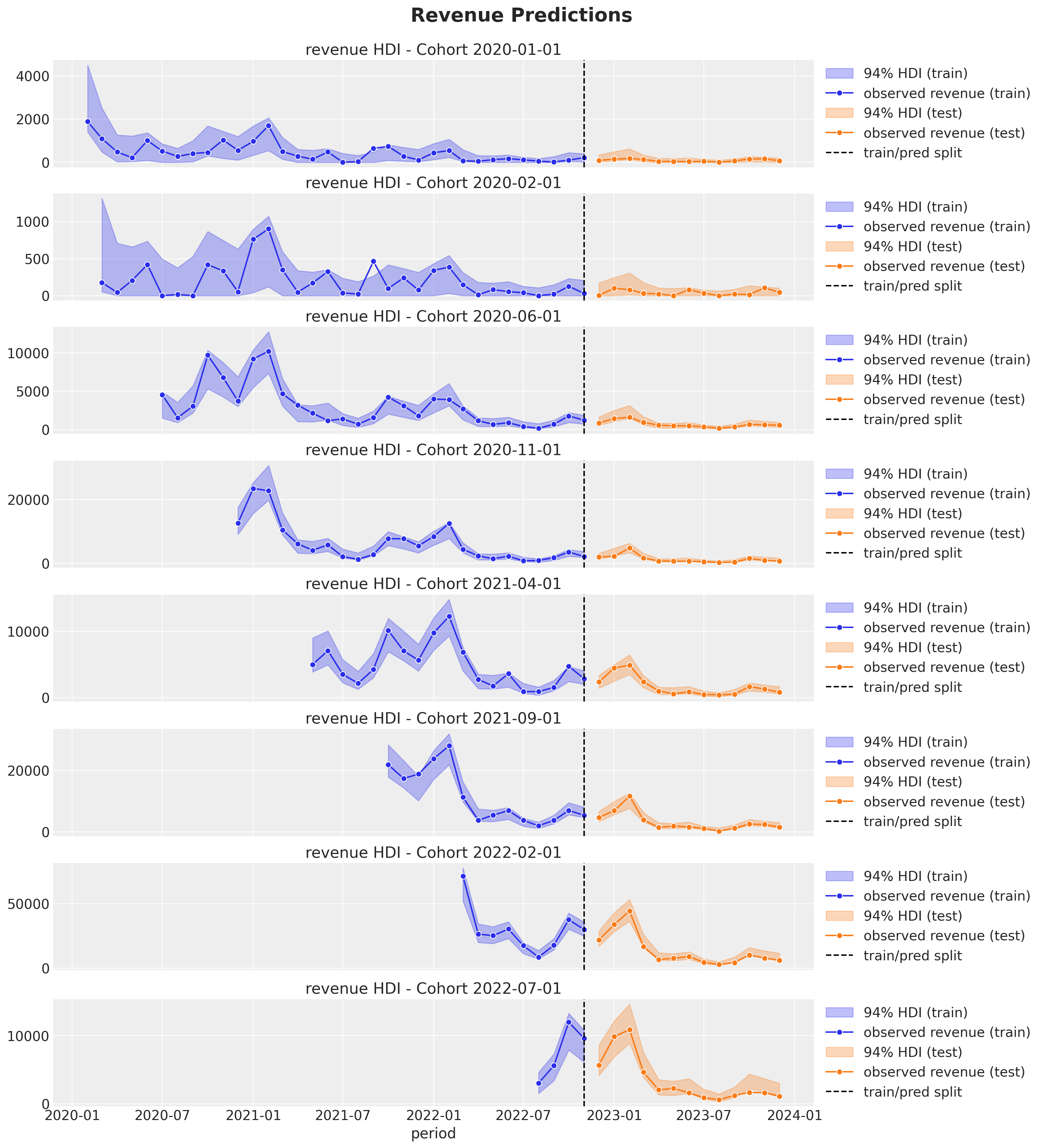
Revenue
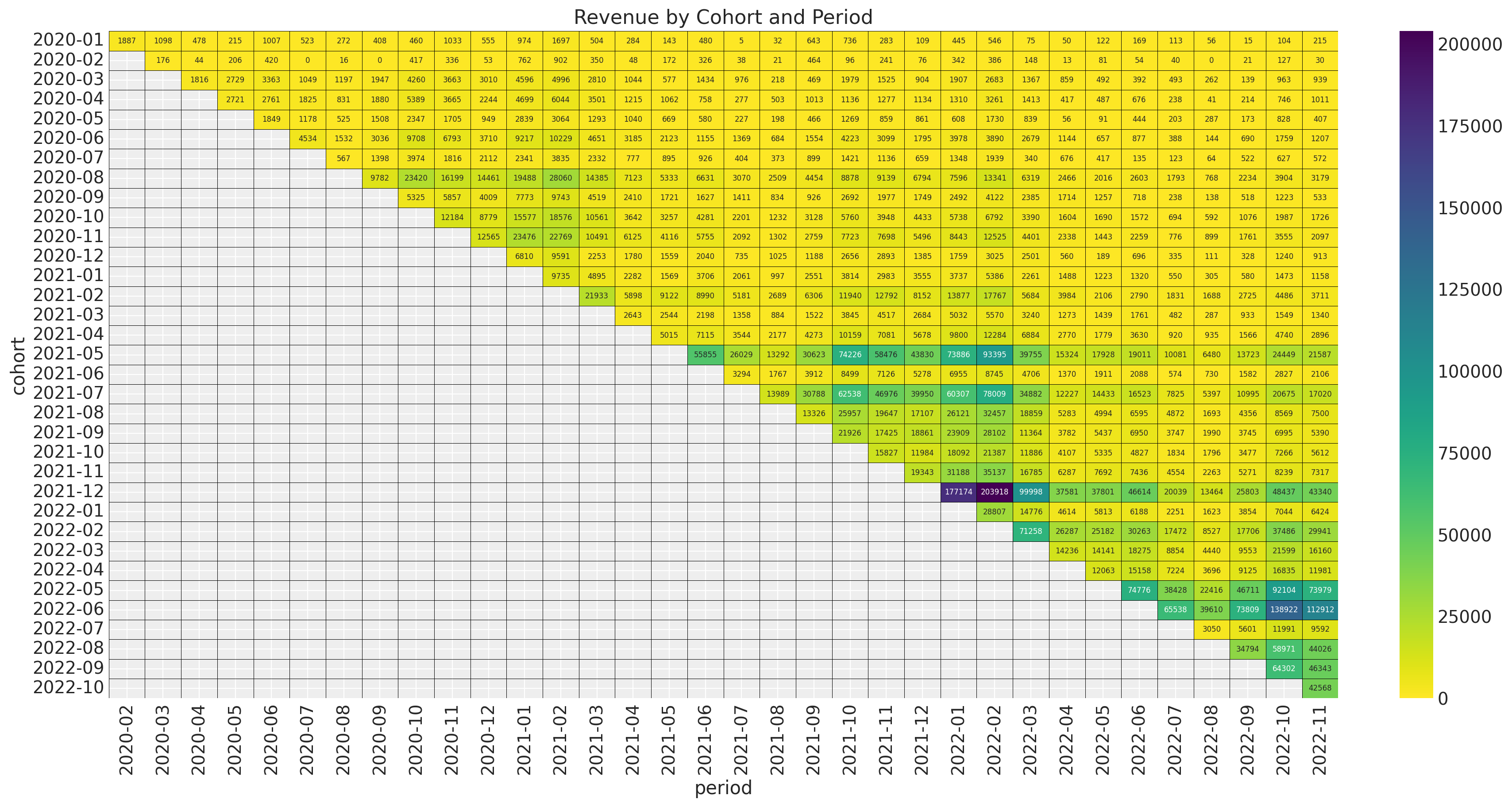
Cohort Revenue-Retention Model

Revenue-Retention - Predictions
Open Source Packages

Thank you!

![]()