In this notebook, we explore the (conceptual) ideas and (practical) implementation details of the Hilbert Space approximation for Gaussian processes introduced in the article “Hilbert space methods for reduced-rank Gaussian process regression” by Arno Solin and Simo Särkkä. We do not go deep into the mathematical details (proofs) but focus on the core ideas to help us understand the main concepts guiding the technical implementation. We provide examples, both in NumPyro and PyMC, so that users can learn from cross-framework comparison so that we abstract the core ideas.
Before jumping into the approximation technique, we recall the notion of Gaussian processes to set up notation and understand the problem the Hilbert Space approximation is trying to solve. For a detailed treatment of the topic, please refer to the classical (free and online available!) book “Gaussian Processes for Machine Learning” by Carl Edward Rasmussen and Christopher K. I. Williams. I have also written some blog posts with code about Gaussian process regression:
Another recommended reference is the online post “Robust Gaussian Process Modeling” by Michael Betancourt
Remark [Slides]: I presented this topic at PyConDE & PyData Berlin 2024. Here you can find the slides.
Here you can find an associated recording presented in the Learning Bayesian Statistics webinar:
Prepare Notebook
from collections.abc import Callable
import arviz as az
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
import numpyro
import numpyro.distributions as dist
import preliz as pz
import pymc as pm
import seaborn as sns
from jax import random, scipy, vmap
from jaxlib.xla_extension import ArrayImpl
from numpyro.handlers import seed, trace
from numpyro.infer import MCMC, NUTS, Predictive
from pydantic import BaseModel, Field
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
numpyro.set_host_device_count(n=4)
rng_key = random.PRNGKey(seed=42)
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"Generate Synthetic Data
For the purpose of this notebook, we generate synthetic data in a one-dimensional space. We use the same functional form as in the blogpost An Introduction to Gaussian Process Regression,
\[ y = f(x) + \varepsilon \]
where
\[f(x) = \sin(4 \pi x) + \sin(7 \pi x)\]
and \(\varepsilon \sim \text{Normal}(0, 0.3)\). We generate \(80\) points in the interval \([0, 1]\) as training set and \(100\) points in the interval \([-0.2, 1.2]\) as test set.
def generate_synthetic_data(
rng_key: ArrayImpl, start: float, stop: float, num: int, scale: float
) -> tuple[ArrayImpl, ArrayImpl, ArrayImpl]:
x = jnp.linspace(start=start, stop=stop, num=num)
y = jnp.sin(4 * jnp.pi * x) + jnp.sin(7 * jnp.pi * x)
y_obs = y + scale * random.normal(rng_key, shape=(num,))
return x, y, y_obs
n_train = 80
n_test = 100
scale = 0.3
rng_key, rng_subkey = random.split(rng_key)
x_train, y_train, y_train_obs = generate_synthetic_data(
rng_key=rng_subkey, start=0, stop=1, num=n_train, scale=scale
)
rng_key, rng_subkey = random.split(rng_key)
x_test, y_test, y_test_obs = generate_synthetic_data(
rng_key=rng_subkey, start=-0.2, stop=1.2, num=n_test, scale=scale
)Let’s visualize the synthetic dataset (training and test set).
fig, ax = plt.subplots()
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
ax.scatter(x_test, y_test_obs, c="C1", label="observed (test)")
ax.plot(x_train, y_train, color="black", linewidth=3, label="mean (latent)")
ax.axvline(x=0, color="C0", alpha=0.3, linestyle="--", linewidth=2)
ax.axvline(
x=1, color="C0", linestyle="--", alpha=0.3, linewidth=2, label="training range"
)
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=4)
ax.set(xlabel="x", ylabel="y")
ax.set_title("Synthetic Data", fontsize=18, fontweight="bold");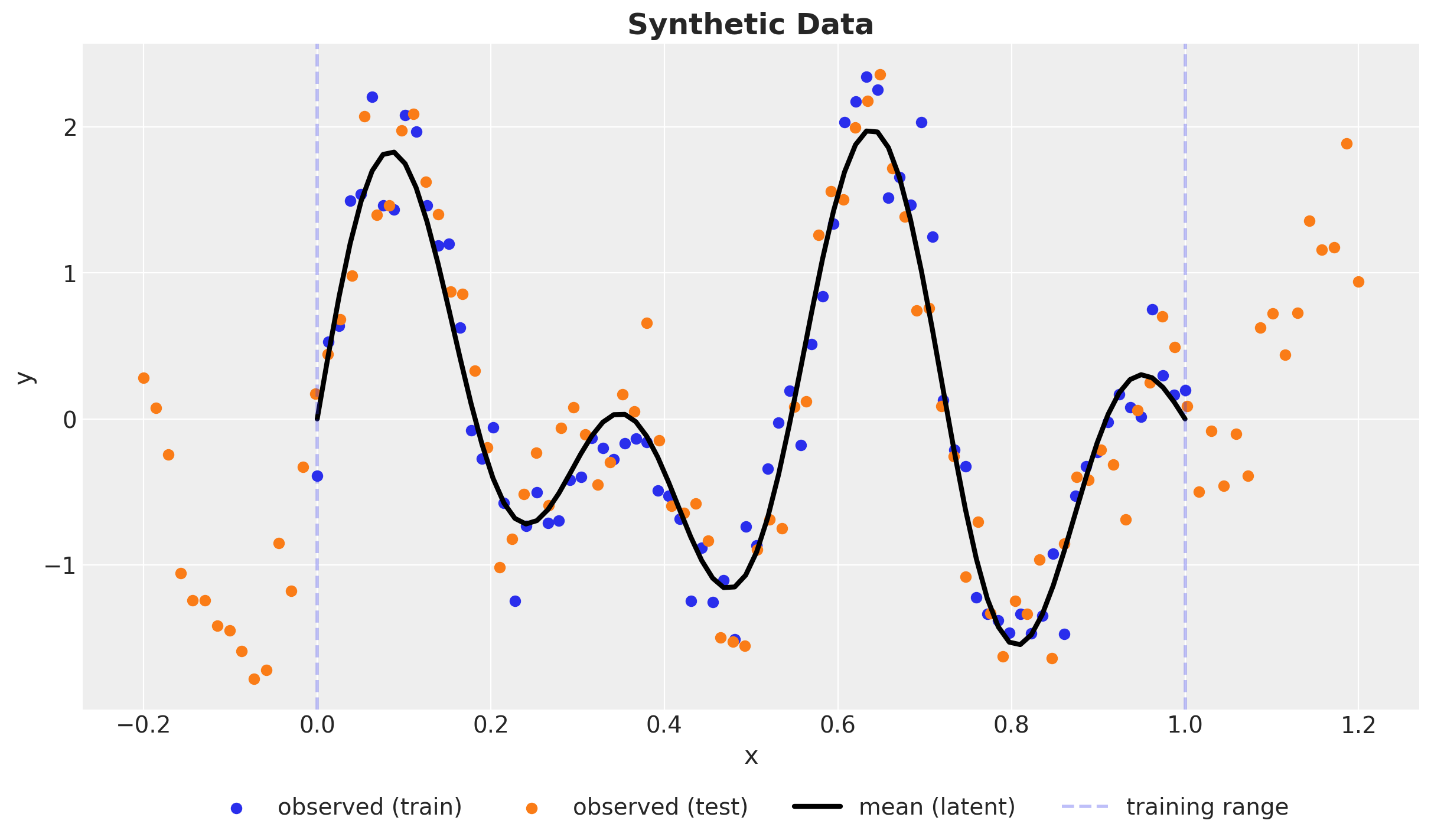
Observe that, intentionally, the test set range is wider than the training set. The reason is because we want to understand the extrapolations capabilities of the Gaussian process of this example.
Part I: Gaussian Processes (GPs)
In this first part we recall the notion of Gaussian processes and the problem of inference in the context of regression. To showcase the main components of a Gaussian process model, we do it “by hand” using JAX and NumPyro. Afterwards, we show how to use the gp module in PyMC to generate the same results.
NumPyro Gaussian Process Model
For the NumPyro implementation, we use the the code from some examples of the tutorial pages:
Kernel Specification
Given the data (and context of the application), we as modelers need to specify a kernel function that captures the structure of the data. The kernel function is a measure of similarity (covariance) between two points in the input space. The most common kernel function is the squared exponential kernel (also known as Gaussian kernel or RBF kernel):
\[ \text{cov}(f_{p}, f_{q}) = k_{a, \ell}(x_p, x_q) = a^{2} \: \exp\left(-\frac{1}{2\ell^2} ||x_p - x_q||^2\right) \]
This kernel, which depends on two parameters \(a\) and \(\ell\), will produce smooth functions. The parameter \(a\) is the amplitude and \(\ell\) is the length-scale. The length-scale controls how wiggly the function is. If \(\ell\) is large, the function will be very flat , and if \(\ell\) is small, the function will be wiggly.
There are many more kernels used in applications. For example:
- We can also use the Matérn kernel, which is a generalization of the squared exponential kernel. The Matérn kernel has an additional parameter \(\nu\) that controls the smoothness of the function. The squared exponential kernel is a special case of the Matérn kernel when \(\nu \to \infty\).
- Periodic kernel, which is useful for modeling periodic functions.
For a great introduction to kernels, I recommend the example notebook “Mean and Covariance Functions” from the PyMC example gallery. If you want to go deeper into the subject then I strongly recommend “Gaussian Processes for Machine Learning - Chapter 4: Covariance Functions”
Remark: The sum of kernels is also a valid kernel. This is useful to model functions that have different scales or periodic components. For example, the kernel \(k(x, x') = k_1(x, x') + k_2(x, x')\) is a valid kernel. Also, the product of kernels is a valid kernel. For example, the kernel \(k(x, x') = k_1(x, x') \cdot k_2(x, x')\) is a valid kernel.
Let’s write the squared exponential kernel in JAX:
# https://num.pyro.ai/en/stable/examples/gp.html
def squared_exponential_kernel(
xp: ArrayImpl, xq: ArrayImpl, amplitude: float, length_scale: float
) -> ArrayImpl:
r = xp[:, None] - xq[None, :]
delta = (r / length_scale) ** 2
return amplitude**2 * jnp.exp(-0.5 * delta)We can compute the associated kernel matrix for the training data and fixed values for the amplitude and length-scale. The kernel matrix is a matrix \(K\) such that \(K_{ij} = k(x_i, x_j)\).
kernel = squared_exponential_kernel(x_train, x_train, amplitude=1.0, length_scale=0.1)One can visualize the kernel matrix as a heatmap to understand the structure of the covariance:
fig, ax = plt.subplots()
sns.heatmap(
data=kernel,
square=True,
cmap="viridis",
cbar=True,
xticklabels=False,
yticklabels=False,
ax=ax,
)
ax.set_title("Squared Exponential Kernel", fontsize=18, fontweight="bold");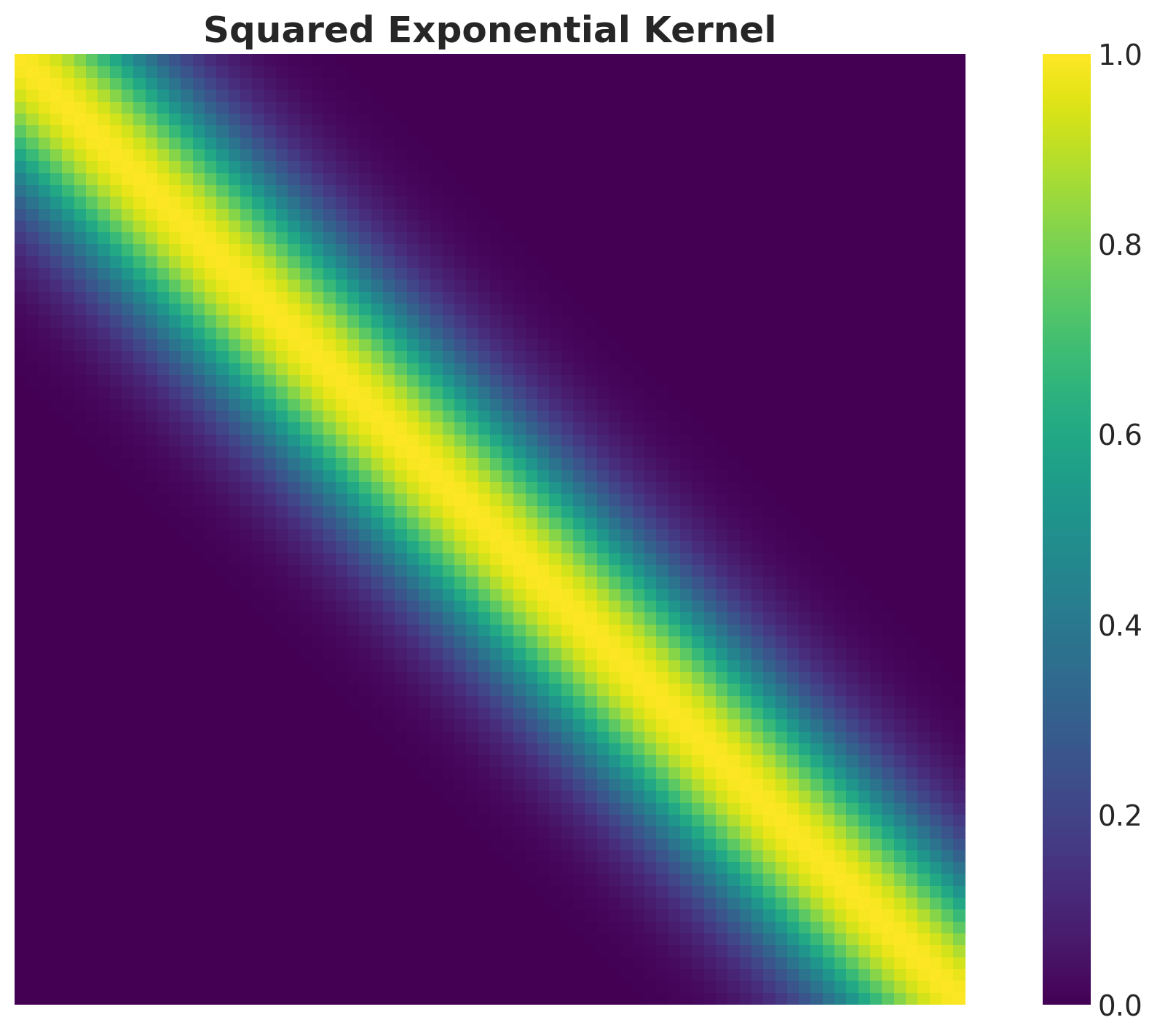
As expected, the kernel matrix is symmetric and the diagonal elements are all equal to \(a^2\).
assert (kernel == kernel.T).all().item()
assert (jnp.diag(kernel) == 1).all().item()The kernel matrices have an additional property: they are positive semi-definite. This means that their eigenvalues are non-negative.
Remark: In this notebook we will be talking a lot about the spectrum (eigenvalues and eigenvector) of a matrix / operator. Recall that given a matrix \(A\) (or a linear operator) the eigenvalues and eigenvectors are the solutions to the equation \(A v = \lambda v\) where \(v \neq \vec{0}\) is the eigenvector and \(\lambda\) is the eigenvalue. The spectrum of a matrix is the set of its eigenvalues. For more details see the blog post “The Spectral Theorem for Matrices”. We will discuss more about eigenvalues and eigenvectors later.
We can verify this for this specific example by computing the eigenvalues of the kernel matrix on the training set:
spectrum_kernel = jnp.linalg.eigh(kernel)
fig, ax = plt.subplots(figsize=(10, 7))
ax.plot(
spectrum_kernel.eigenvalues, marker="o", markersize=5, linestyle="--", color="black"
)
ax.set(xlabel="Eigenvalue Index (sorted)", ylabel="Eigenvalue")
ax.set_title("Training Set")
fig.suptitle(
"Spectrum of the Squared-Exponential Kernel ($a=1$ and $\\ell=0.1$)",
fontsize=18,
fontweight="bold",
);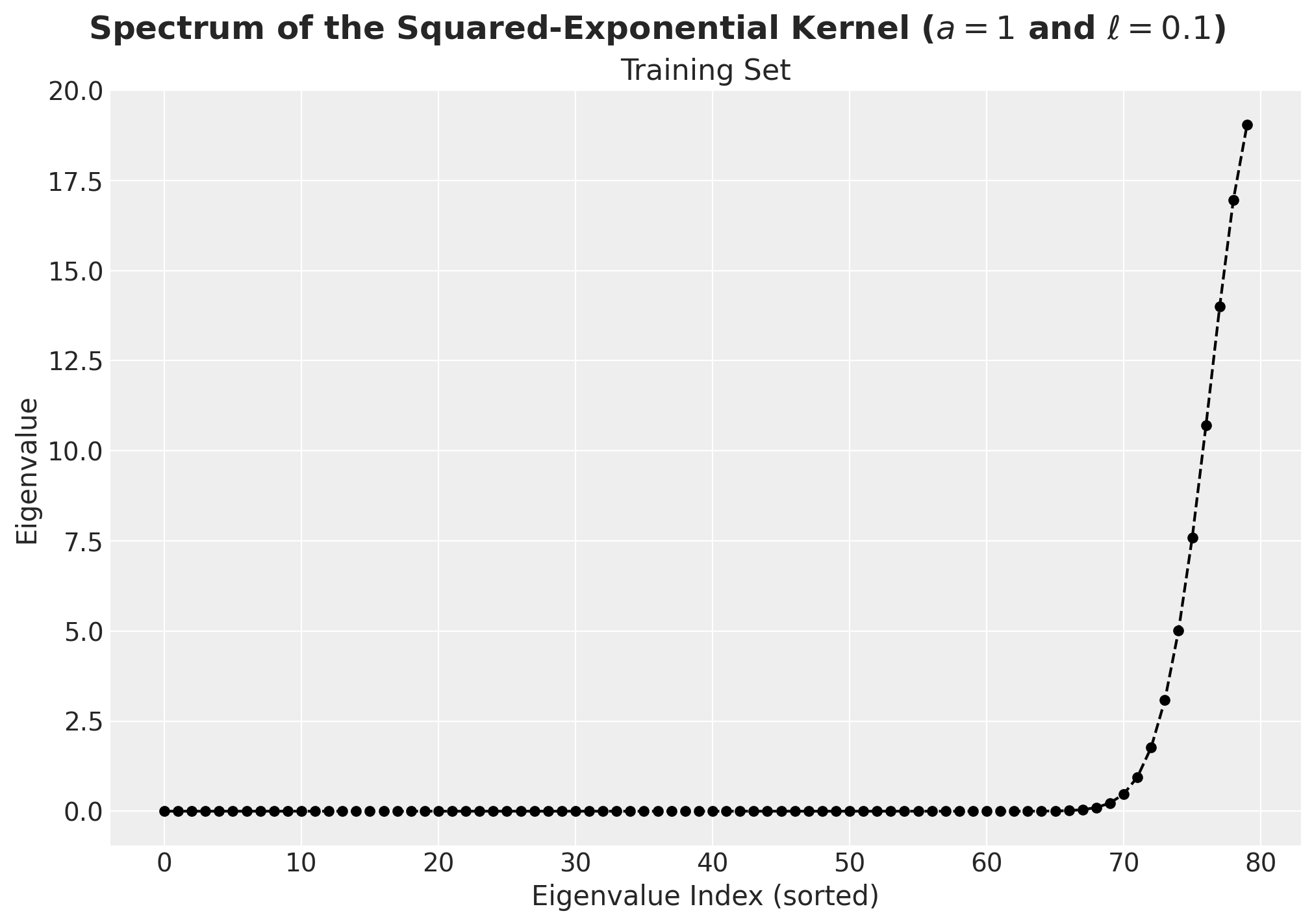
We indeed see that all of the eigenvalues are non-negative (up to some numerical error).
Gaussian Process Model
In this subsection we describe the Gaussian process model. We summarize the main concepts from Gaussian Processes for Machine Learning, Chapter 2: Regression. Recall we used the kernel to construct the kernel matrix \(K := K(X,X)\) from the training data \(X\). We can use this matrix to set a prior distribution over functions. Namely, we can consider a multivariate normal distribution with mean zero and covariance matrix \(K\) so that the sample functions can be realized by sampling from it (in practice we sample a finite number of points and not a function itself). If we denote the test set by \(X_{*}\) and all related quantities regarding this set by lower star, then the joint distribution of \(y\) (observations of the training sets) and \(f_{*}\) (latent GP realization on the test set) is given by (see Equation (2.18) in Gaussian Processes for Machine Learning, Chapter 2: Regression)
\[ \left( \begin{array}{c} y \\ f_* \end{array} \right) \sim \text{MultivariateNormal}(0, \mathcal{K}) \]
where
\[ \mathcal{K} = \left( \begin{array}{cc} K(X, X) + \sigma^2_n I & K(X, X_*) \\ K(X_*, X) & K(X_*, X_*) \end{array} \right) \]
Observe that we need to add the term \(\sigma^2_n I\) to the upper left component to account for noise.
As described in our main reference, to get the posterior distribution over functions we need to restrict this joint prior distribution to contain only those functions which agree with the observed data points, that is, we are interested in computing \(f_*|X, y, X_*\). Using the results of Gaussian Processes for Machine Learning, Appendinx A.2, one can show that (see Equation (2.19) in Gaussian Processes for Machine Learning, Chapter 2: Regression)
\[ f_*|X, y, X_* \sim \text{MultivariateNormal}(\bar{f}_*, \text{cov}(f_*)) \]
where
\[ \bar{f}_* = K(X_*, X)(K(X, X) + \sigma^2_n I)^{-1} y \in \mathbb{R}^{n_*} \]
and
\[ \text{cov}(f_*) = K(X_*, X_*) - K(X_*, X)(K(X, X) + \sigma^2_n I)^{-1} K(X, X_*) \in M_{n_*}(\mathbb{R}) \]
For the NumPyro implementation, we will use these expressions to sample from the posterior distribution over functions on the train and test sets. Note that we are assuming we know the parameters of the kernel function. In practice, we need to infer these parameters from the data. We will discuss this in the next sections.
Parameter Priors
After having a better understanding of the theory behind the Gaussian process model, we can now proceed to the computational aspects. As we are Bayesians (right?), we need to specify priors for the parameters of the kernel function and the noise. This bit itself is a huge topic! (see the great blog post “Priors for the parameters in a Gaussian process” by Dan Simpson). A common choice for the length-scale and amplitude parameters is to use an inverse-gamma distribution as it is positive and drops to zero for values close to zero (this help us to avoid dividing by zero). We expect different ranges for length-scale and amplitude parameters since the former controls the smoothness of the function and the latter the amplitude of the covariance. We can use the function pm.find_constrained_prior to find optimal parameters of the inverse-gamma distribution that align to our believes of the parameters given the data (e.g. plot). In addition, we can use preliz to visualize the resulting prior distributions.
inverse_gamma_params_1 = pm.find_constrained_prior(
distribution=pm.InverseGamma,
lower=0.01,
upper=0.4,
init_guess={"alpha": 5, "beta": 3},
mass=0.94,
)
inverse_gamma_params_2 = pm.find_constrained_prior(
distribution=pm.InverseGamma,
lower=0.5,
upper=1.5,
init_guess={"alpha": 5, "beta": 6},
mass=0.94,
)
fig, ax = plt.subplots()
pz.InverseGamma(**inverse_gamma_params_1).plot_pdf(color="C0", ax=ax)
pz.InverseGamma(**inverse_gamma_params_2).plot_pdf(color="C1", ax=ax)
ax.set(xlim=(0, 2))
ax.set_title("Prior Distributions", fontsize=18, fontweight="bold");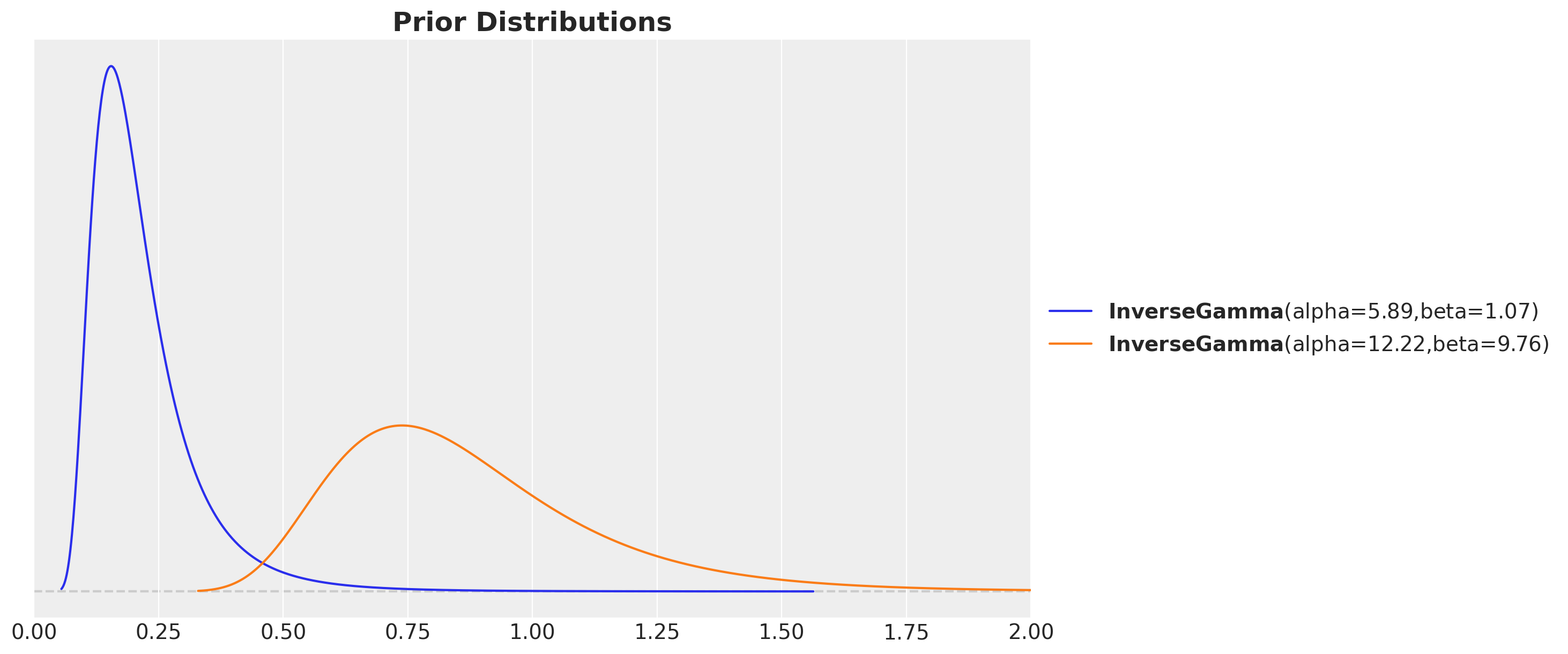
Remark: In this example we use the same priors for the amplitude and noise parameters as it is well suited for the synthetic data. In practice, we would need to use different priors for these parameters.
Model Specification
We now specify the model as described above: we use the kernel function to compute the kernel matrix and then use this matrix to set the prior distribution over functions as a multivariate normal distribution.
def gp_model(x, y=None, jitter=1.0e-6) -> None:
# --- Priors ---
kernel_amplitude = numpyro.sample(
"kernel_amplitude",
dist.InverseGamma(
concentration=inverse_gamma_params_2["alpha"],
rate=inverse_gamma_params_2["beta"],
),
)
kernel_length_scale = numpyro.sample(
"kernel_length_scale",
dist.InverseGamma(
concentration=inverse_gamma_params_1["alpha"],
rate=inverse_gamma_params_1["beta"],
),
)
noise = numpyro.sample(
"noise",
dist.InverseGamma(
concentration=inverse_gamma_params_2["alpha"],
rate=inverse_gamma_params_2["beta"],
),
)
# --- Parametrization ---
mean = jnp.zeros(x.shape[0])
kernel = squared_exponential_kernel(x, x, kernel_amplitude, kernel_length_scale)
covariance_matrix = kernel + (noise + jitter) * jnp.eye(x.shape[0])
# --- Likelihood ---
numpyro.sample(
"likelihood",
dist.MultivariateNormal(loc=mean, covariance_matrix=covariance_matrix),
obs=y,
)We can visualize the model representation in plate notation:
numpyro.render_model(
model=gp_model,
model_args=(x_train, y_train_obs),
render_distributions=True,
render_params=True,
)
Prior Predictive Check
Before fitting the model to the data, we can use the model above to generate samples from the prior distribution over functions. This will help us to understand the behavior of the model before seeing the data.
gp_numpyro_prior_predictive = Predictive(gp_model, num_samples=1_000)
rng_key, rng_subkey = random.split(rng_key)
gp_numpyro_prior_samples = gp_numpyro_prior_predictive(rng_subkey, x_train)
gp_numpyro_prior_idata = az.from_numpyro(prior=gp_numpyro_prior_samples)fig, ax = plt.subplots()
az.plot_hdi(
x_train,
gp_numpyro_prior_idata.prior["likelihood"],
hdi_prob=0.94,
color="C0",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_train,
gp_numpyro_prior_idata.prior["likelihood"],
hdi_prob=0.5,
color="C0",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$50\\%$ HDI"},
ax=ax,
)
ax.plot(
x_train,
gp_numpyro_prior_idata.prior["likelihood"].mean(dim=("chain", "draw")),
color="C0",
linewidth=3,
label="posterior predictive mean",
)
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
for i in range(5):
label = "prior samples" if i == 0 else None
ax.plot(
x_train,
gp_numpyro_prior_idata.prior["likelihood"].sel(chain=0, draw=i),
color="C0",
alpha=0.3,
label=label,
)
ax.plot(x_train, y_train, color="black", linewidth=3, alpha=0.7, label="mean (latent)")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=3)
ax.set(xlabel="x", ylabel="y")
ax.set_title("GP NumPyro Model - Prior Predictive", fontsize=18, fontweight="bold");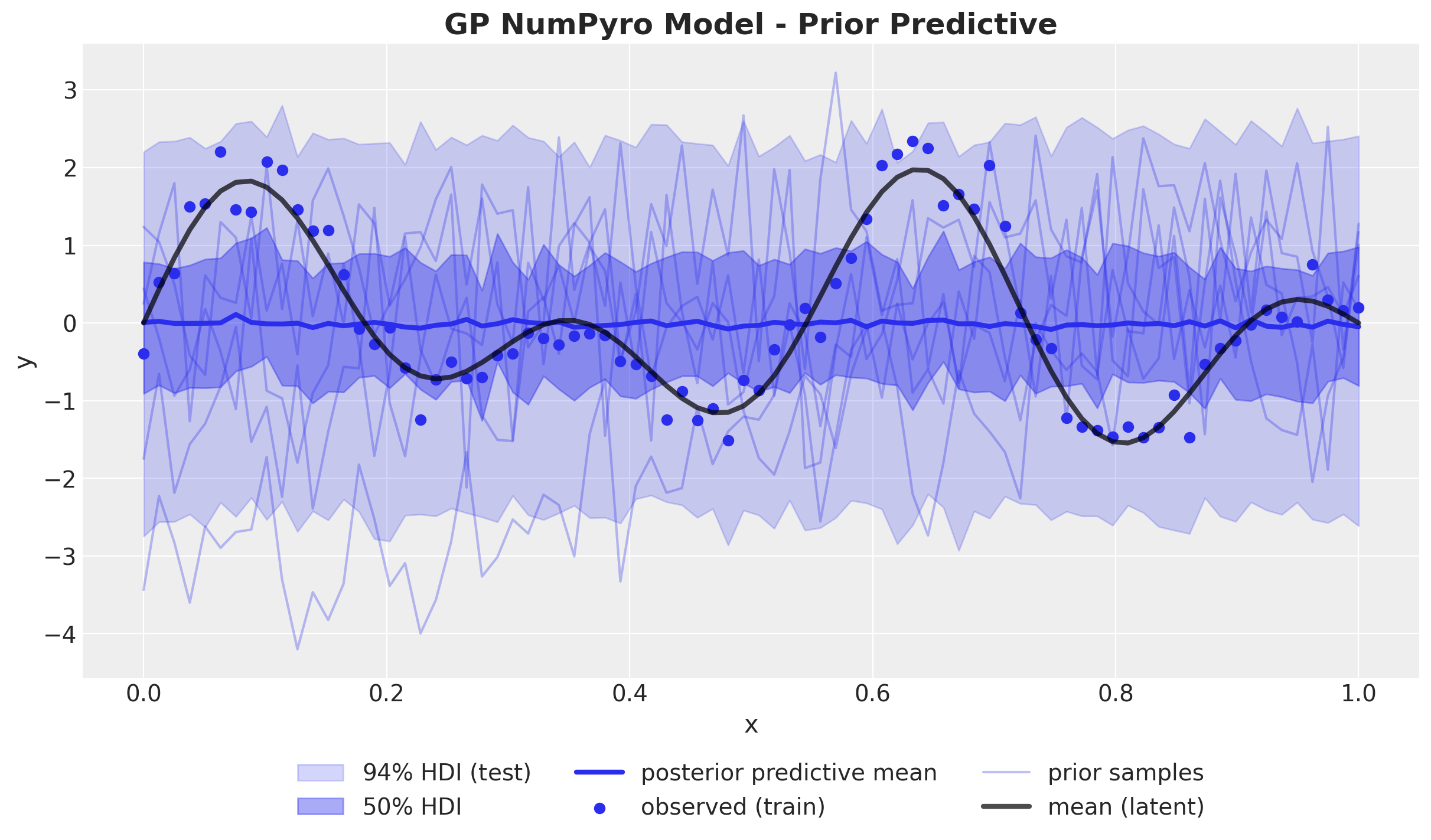
We see that the generated functions (range and smoothness) are reasonable candidates for the true function. Hence, we can proceed to fit the model to the data.
Model Fitting
We define some helper objects to fit the model to the data so that we can reuse them later.
class InferenceParams(BaseModel):
num_warmup: int = Field(2_000, ge=1)
num_samples: int = Field(2_000, ge=1)
num_chains: int = Field(4, ge=1)
def run_inference(
rng_key: ArrayImpl,
model: Callable,
args: InferenceParams,
*model_args,
**nuts_kwargs,
) -> MCMC:
sampler = NUTS(model, **nuts_kwargs)
mcmc = MCMC(
sampler=sampler,
num_warmup=args.num_warmup,
num_samples=args.num_samples,
num_chains=args.num_chains,
)
mcmc.run(rng_key, *model_args)
return mcmc
inference_params = InferenceParams()
rng_key, rng_subkey = random.split(key=rng_key)
gp_mcmc = run_inference(rng_subkey, gp_model, inference_params, x_train, y_train_obs)Model Diagnostics
The model samples quite fast! We can now look into the posterior distributions and model diagnostics:
gp_numpyro_idata = az.from_numpyro(posterior=gp_mcmc)
az.summary(data=gp_numpyro_idata)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| kernel_amplitude | 1.190 | 0.267 | 0.729 | 1.672 | 0.004 | 0.003 | 5426.0 | 4562.0 | 1.0 |
| kernel_length_scale | 0.089 | 0.011 | 0.069 | 0.109 | 0.000 | 0.000 | 5004.0 | 4967.0 | 1.0 |
| noise | 0.278 | 0.043 | 0.204 | 0.359 | 0.001 | 0.000 | 5928.0 | 4826.0 | 1.0 |
axes = az.plot_trace(
data=gp_numpyro_idata,
compact=True,
kind="rank_bars",
backend_kwargs={"figsize": (12, 7), "layout": "constrained"},
)
plt.gcf().suptitle("GP NumPyro - Trace", fontsize=18, fontweight="bold");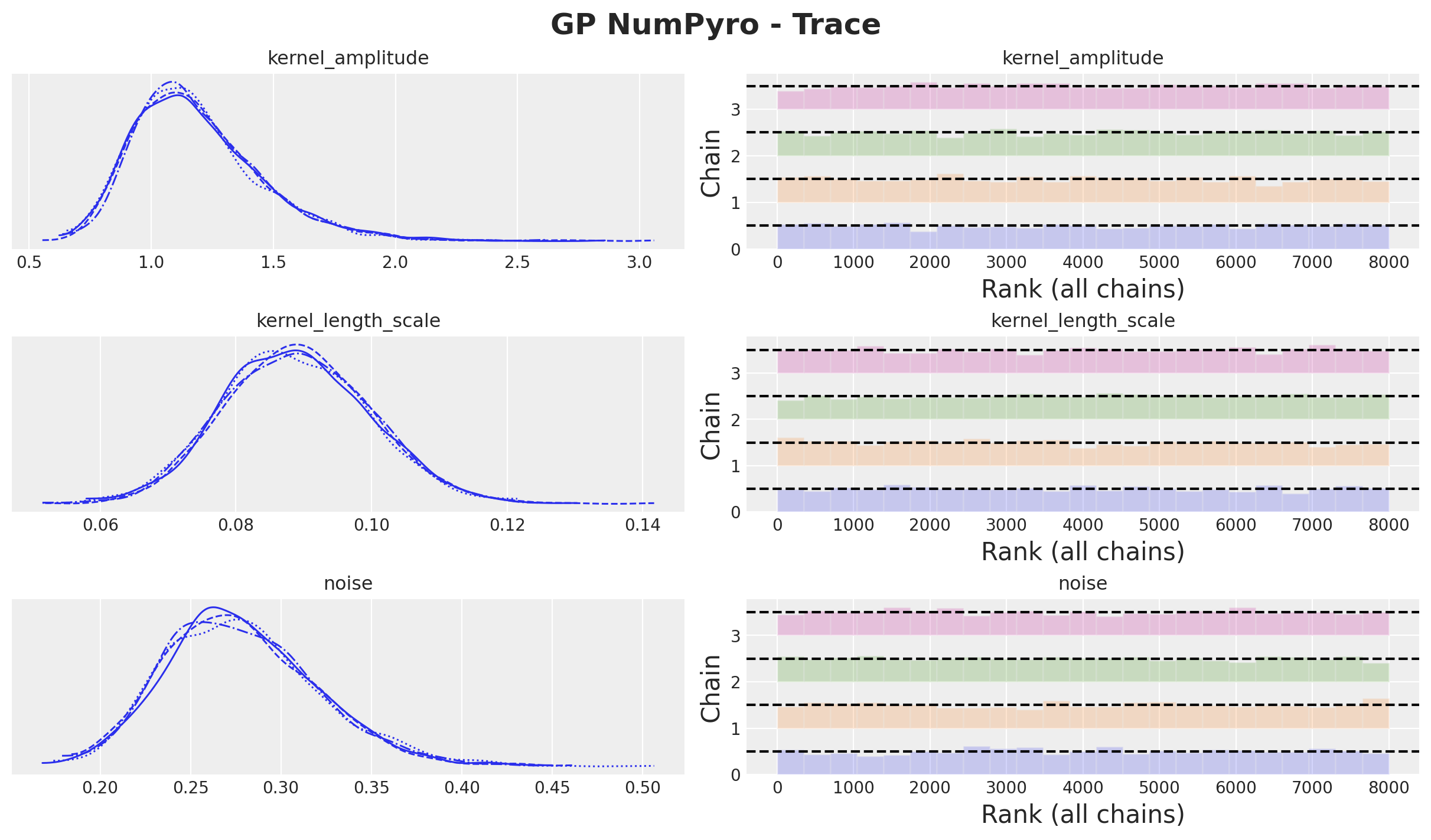
Everything looks good! We are ready to generate predictions for the test set.
Out of Sample Prediction
Recall from the Gaussian model description that we can generate samples on the test set as:
\[ f_*|X, y, X_* \sim \text{MultivariateNormal}(\bar{f}_*, \text{cov}(f_*)) \]
where
\[ \bar{f}_* = K(X_*, X)(K(X, X) + \sigma^2_n I)^{-1} y \]
and
\[ \text{cov}(f_*) = K(X_*, X_*) - K(X_*, X)(K(X, X) + \sigma^2_n I)^{-1} K(X, X_*) \]
We now simply write these expressions in JAX code:
def get_kernel_matrices_train_test(
kernel, x, x_test, noise, jitter=1.0e-6, **kernel_kwargs
) -> tuple[ArrayImpl, ArrayImpl, ArrayImpl]:
k = kernel(x, x, **kernel_kwargs) + (noise + jitter) * jnp.eye(x.shape[0])
k_star = kernel(x_test, x, **kernel_kwargs)
k_star_star = kernel(x_test, x_test, **kernel_kwargs) + (noise + jitter) * jnp.eye(
x_test.shape[0]
)
return k, k_star, k_star_star
def sample_test(rng_key, kernel, x, y, x_test, noise, jitter=1.0e-6, **kernel_kwargs):
k, k_star, k_star_star = get_kernel_matrices_train_test(
kernel, x, x_test, noise, jitter, **kernel_kwargs
)
k_inv = jnp.linalg.inv(k)
mean_star = k_star @ (k_inv @ y)
cov_star = k_star_star - (k_star @ k_inv @ k_star.T)
return random.multivariate_normal(rng_key, mean=mean_star, cov=cov_star)We now vmap (i.e. paralellize) these functions to generate samples from the posterior distribution over functions on the test set.
rng_key, rng_subkey = random.split(rng_key)
vmap_args = (
random.split(
rng_subkey, inference_params.num_samples * inference_params.num_chains
),
gp_mcmc.get_samples()["noise"],
gp_mcmc.get_samples()["kernel_amplitude"],
gp_mcmc.get_samples()["kernel_length_scale"],
)
posterior_predictive_test = vmap(
lambda rng_key, noise, amplitude, length_scale: sample_test(
rng_key,
squared_exponential_kernel,
x_train,
y_train_obs,
x_test,
noise,
amplitude=amplitude,
length_scale=length_scale,
),
)(*vmap_args)
gp_numpyro_idata.extend(
az.from_dict(
posterior_predictive={
"y_pred_test": posterior_predictive_test[None, ...],
},
coords={"x": x_test},
dims={"y_pred_test": ["x"]},
)
)Here is the final result:
fig, ax = plt.subplots()
az.plot_hdi(
x_test,
gp_numpyro_idata.posterior_predictive["y_pred_test"],
hdi_prob=0.94,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
gp_numpyro_idata.posterior_predictive["y_pred_test"],
hdi_prob=0.5,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$50\\%$ HDI (test)"},
ax=ax,
)
ax.plot(
x_test,
gp_numpyro_idata.posterior_predictive["y_pred_test"].mean(dim=("chain", "draw")),
color="C1",
linewidth=3,
label="posterior predictive mean (test)",
)
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
ax.scatter(x_test, y_test_obs, c="C1", label="observed (test)")
ax.plot(x_train, y_train, color="black", linewidth=3, alpha=0.7, label="mean (latent)")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=3)
ax.set(xlabel="x", ylabel="y")
ax.set_title("GP NumPyro Model - Posterior Predictive", fontsize=18, fontweight="bold");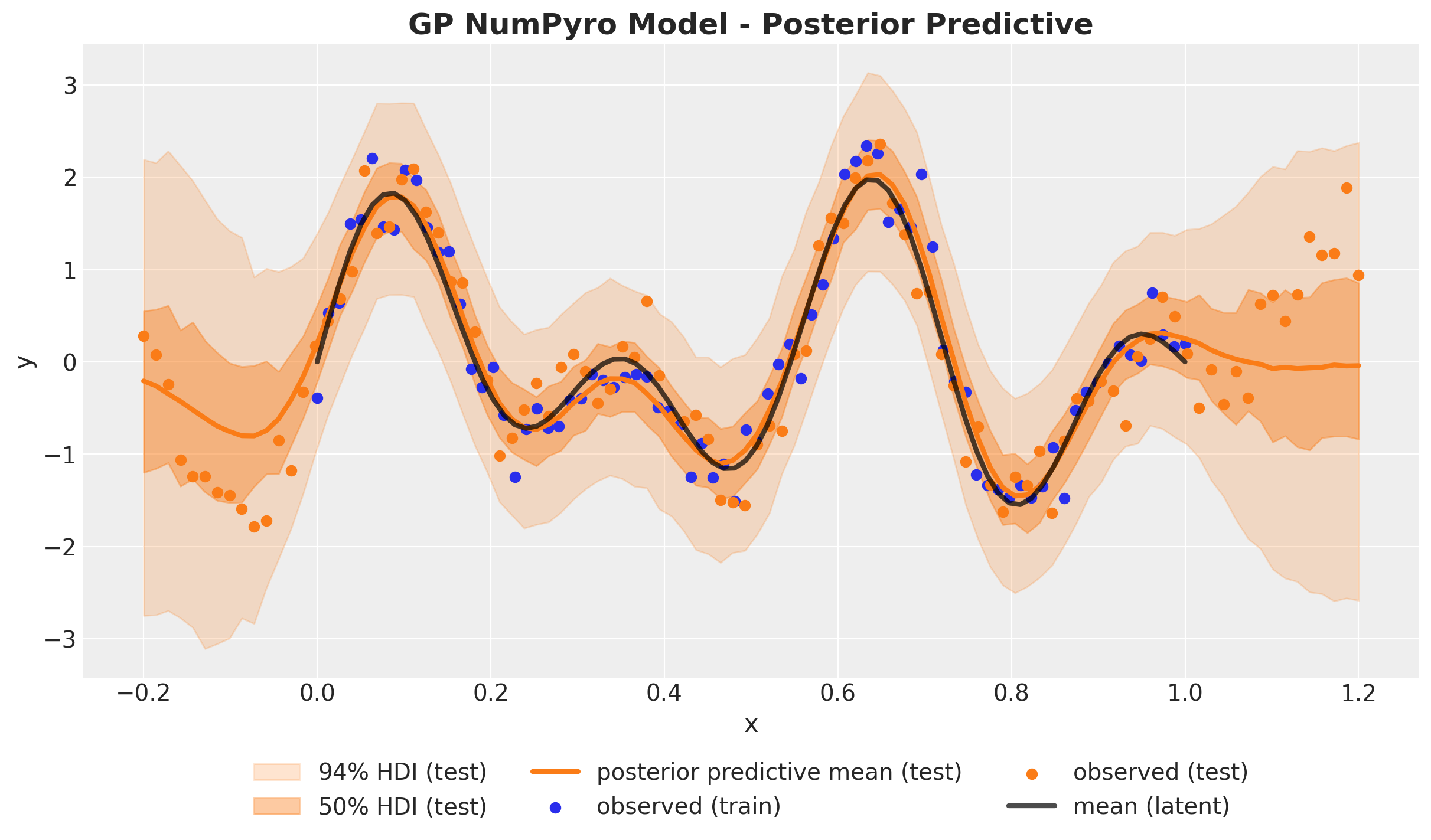
It looks very good 🚀! The in-sample fit captures very well the latent Gaussian process mean (black line). The out of sample also works well close to the boundaries (note how the uncertainty grows as we get far away from the training space, as expected). In the following plot we add indicators of one length scale the posterior distribution shift from the boundaries, until where we expect the model to work relatively well.
kernel_length_scale_hdi = az.hdi(gp_numpyro_idata.posterior)[
"kernel_length_scale"
].to_numpy()
fig, ax = plt.subplots()
plt.axvspan(
xmin=x_train.min().item() - kernel_length_scale_hdi[1],
xmax=x_train.min().item() - kernel_length_scale_hdi[0],
color="C7",
alpha=0.3,
label="x_train_min - length scale $94\\%$ HDI",
)
plt.axvspan(
xmin=x_train.max().item() + kernel_length_scale_hdi[1],
xmax=x_train.max().item() + kernel_length_scale_hdi[0],
color="C8",
alpha=0.3,
label="x_train_max + length scale $94\\%$ HDI",
)
az.plot_hdi(
x_test,
gp_numpyro_idata.posterior_predictive["y_pred_test"],
hdi_prob=0.94,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
gp_numpyro_idata.posterior_predictive["y_pred_test"],
hdi_prob=0.5,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$50\\%$ HDI (test)"},
ax=ax,
)
ax.plot(
x_test,
gp_numpyro_idata.posterior_predictive["y_pred_test"].mean(dim=("chain", "draw")),
color="C1",
linewidth=3,
label="posterior predictive mean (test)",
)
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
ax.scatter(x_test, y_test_obs, c="C1", label="observed (test)")
ax.plot(x_train, y_train, color="black", linewidth=3, alpha=0.7, label="mean (latent)")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=2)
ax.set(xlabel="x", ylabel="y")
ax.set_title("GP NumPyro Model - Posterior Predictive", fontsize=18, fontweight="bold");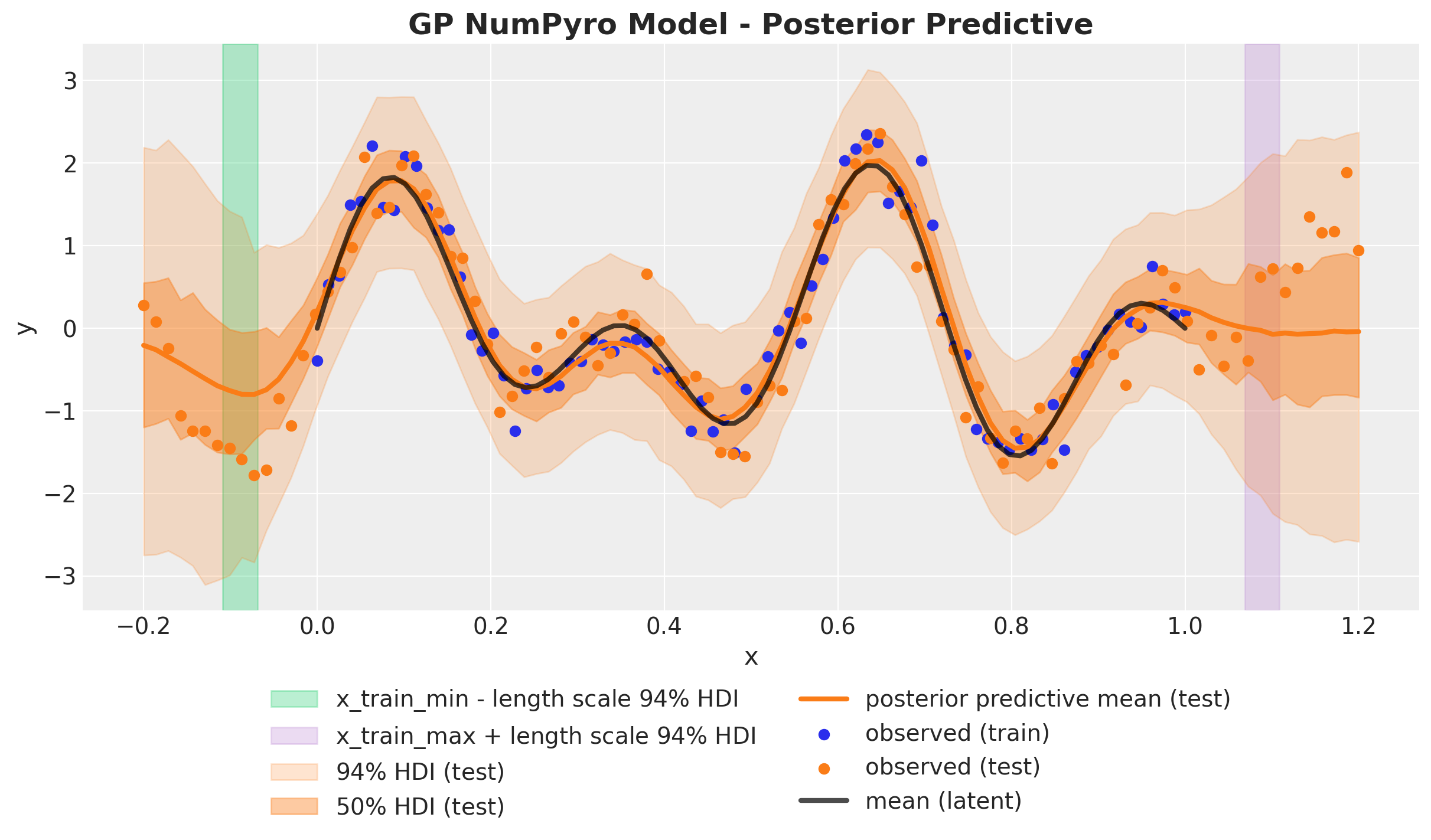
PyMC Gaussian Process Model
In this section we show how to use the gp module in PyMC to generate the same results as in the NumPyro implementation. The data, priors and sampling parameters are the same as above.
To define a Gaussian process component in PyMC we can use the pm.Latent class. This class allows us to define a Gaussian process with a given mean and kernel function. Moreover, we can use the conditional method to generate samples from the posterior distribution over functions on the test set without the need to write the expressions by hand. Let’s see how to do this.
with pm.Model() as gp_pymc_model:
x_data = pm.MutableData("x_data", value=x_train)
kernel_amplitude = pm.InverseGamma(
"kernel_amplitude",
alpha=inverse_gamma_params_2["alpha"],
beta=inverse_gamma_params_2["beta"],
)
kernel_length_scale = pm.InverseGamma(
"kernel_length_scale",
alpha=inverse_gamma_params_1["alpha"],
beta=inverse_gamma_params_1["beta"],
)
noise = pm.InverseGamma(
"noise",
alpha=inverse_gamma_params_2["alpha"],
beta=inverse_gamma_params_2["beta"],
)
mean = pm.gp.mean.Zero()
cov = kernel_amplitude**2 * pm.gp.cov.ExpQuad(input_dim=1, ls=kernel_length_scale)
gp = pm.gp.Latent(mean_func=mean, cov_func=cov)
f = gp.prior("f", X=x_data[:, None])
pm.Normal("likelihood", mu=f, sigma=noise, observed=y_train_obs)
pm.model_to_graphviz(model=gp_pymc_model)
Before fitting the model we run a prior predictive check. We expect this to be very similar to the NumPyro model as the priors and kernel are the same.
rng_key, rng_subkey = random.split(rng_key)
with gp_pymc_model:
gp_pymc_prior_predictive = pm.sample_prior_predictive(
samples=2_000, random_seed=rng_subkey[0].item()
)fig, ax = plt.subplots()
az.plot_hdi(
x_train,
gp_pymc_prior_predictive.prior_predictive["likelihood"],
hdi_prob=0.94,
color="C0",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_train,
gp_pymc_prior_predictive.prior_predictive["likelihood"],
hdi_prob=0.5,
color="C0",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$50\\%$ HDI"},
ax=ax,
)
ax.plot(
x_train,
gp_pymc_prior_predictive.prior_predictive["likelihood"].mean(dim=("chain", "draw")),
color="C0",
linewidth=3,
label="posterior predictive mean",
)
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
for i in range(5):
label = "prior samples" if i == 0 else None
ax.plot(
x_train,
gp_pymc_prior_predictive.prior_predictive["likelihood"].sel(chain=0, draw=i),
color="C0",
alpha=0.3,
label=label,
)
ax.plot(x_train, y_train, color="black", linewidth=3, alpha=0.7, label="mean (latent)")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=3)
ax.set(xlabel="x", ylabel="y")
ax.set_title("GP PyMC Model - Prior Predictive", fontsize=18, fontweight="bold");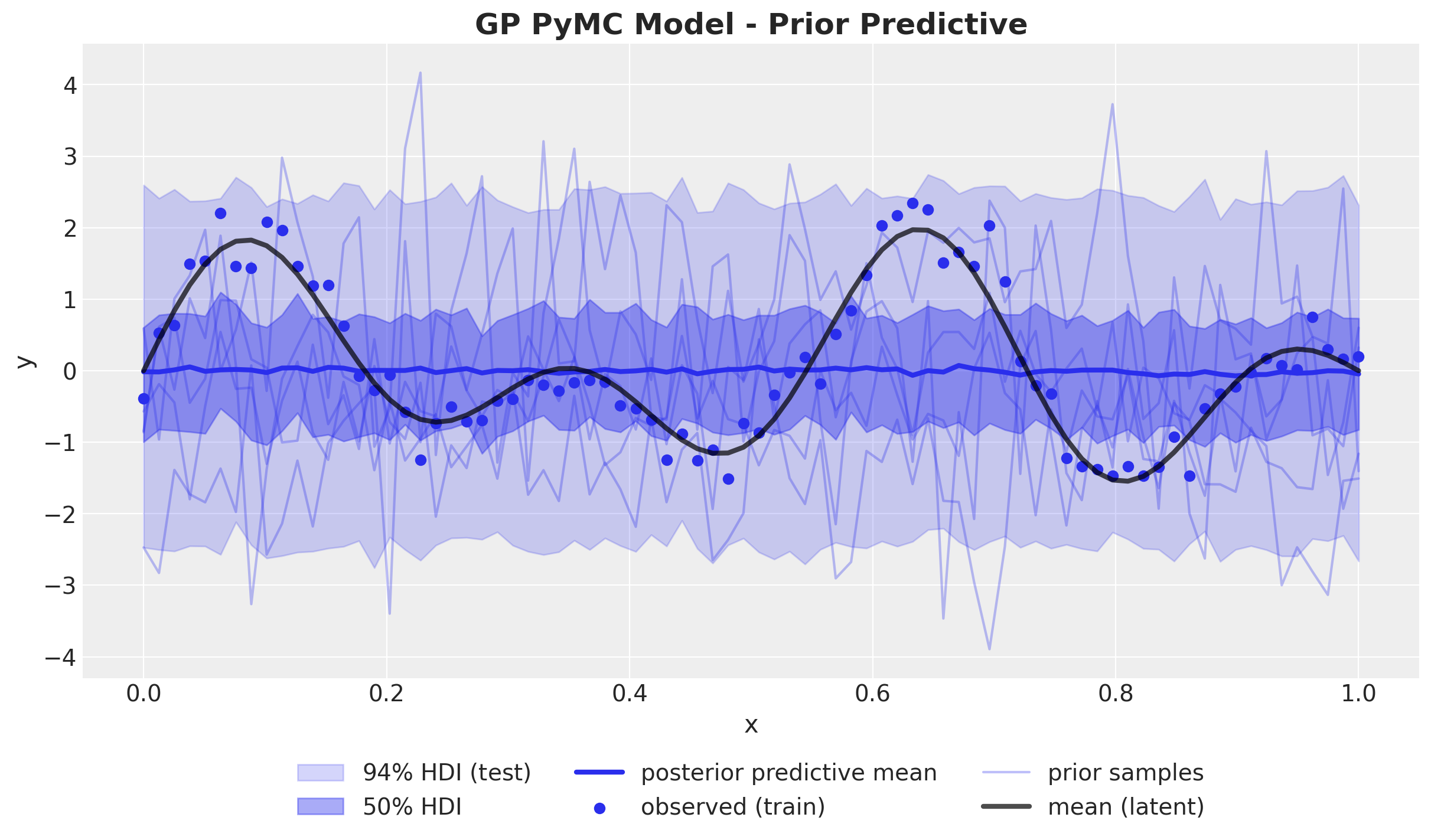
The prior predictive check looks indeed very similar as above. We proceed to fit the model to the data.
rng_key, rng_subkey = random.split(rng_key)
with gp_pymc_model:
gp_pymc_idata = pm.sample(
target_accept=0.9,
draws=inference_params.num_samples,
chains=inference_params.num_chains,
nuts_sampler="numpyro",
random_seed=rng_subkey[0].item(),
)The sampling time is not as fast as in the NumPyro implementation. It is slow, but it is still reasonable. We can now look into the posterior distributions and model diagnostics:
axes = az.plot_trace(
data=gp_pymc_idata,
var_names=["kernel_amplitude", "kernel_length_scale", "noise"],
compact=True,
kind="rank_bars",
backend_kwargs={"figsize": (12, 7), "layout": "constrained"},
)
plt.gcf().suptitle("GP PyMC - Trace", fontsize=18, fontweight="bold");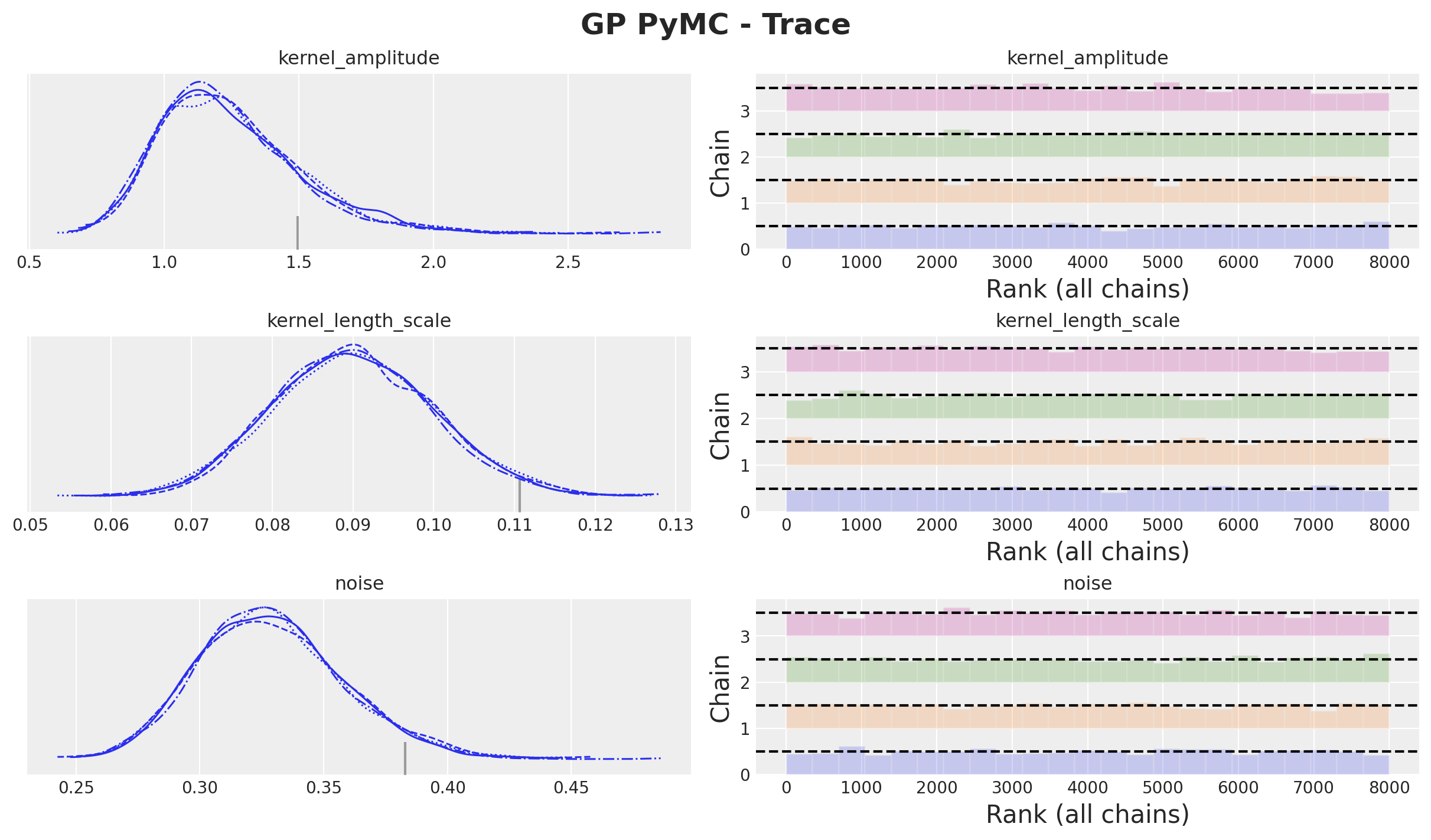
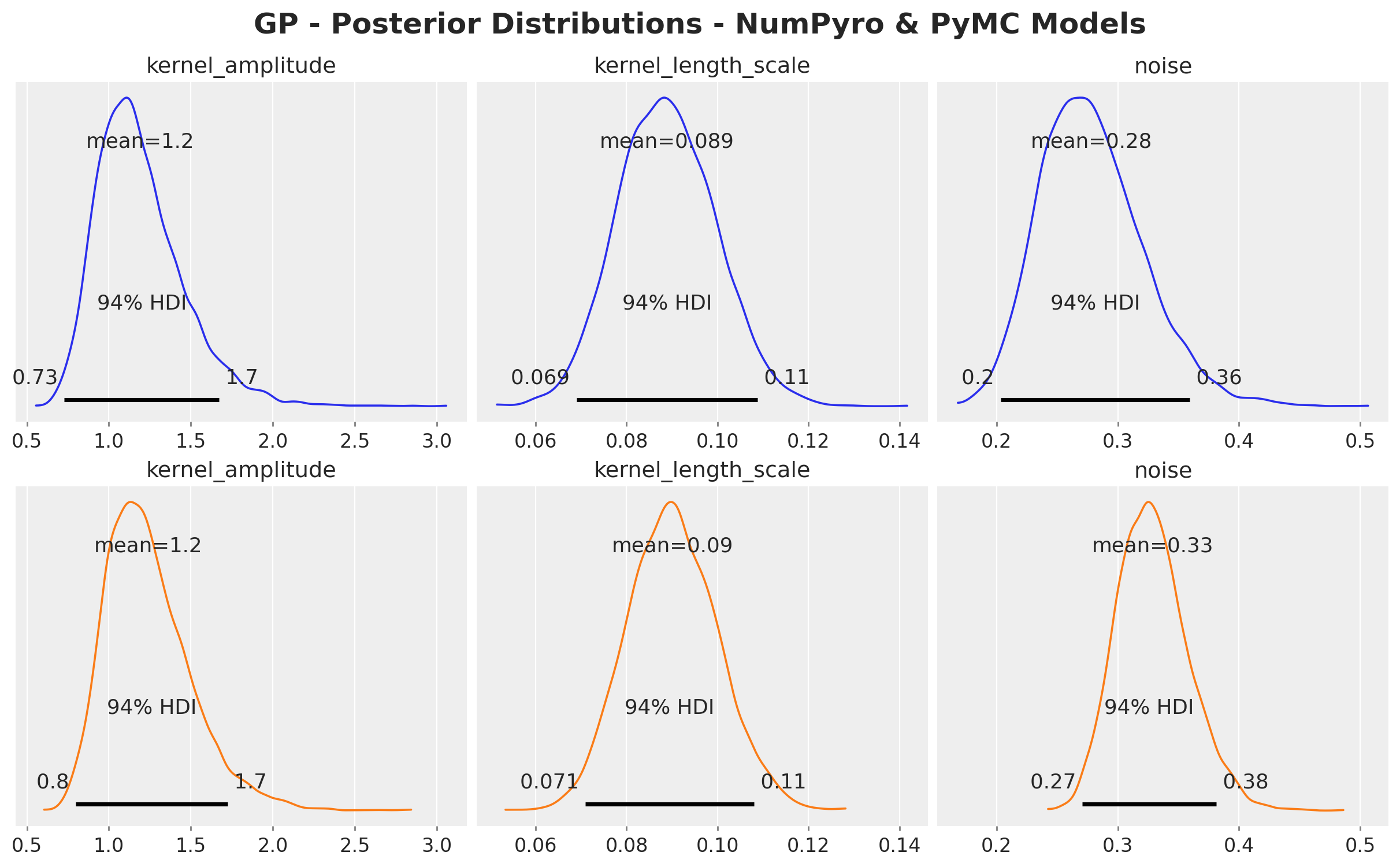
We can see that the posterior distributions of both frameworks are almost the same:
fig, ax = plt.subplots(
nrows=2,
ncols=3,
figsize=(12, 7),
sharex="col",
sharey=False,
constrained_layout=True,
)
az.plot_posterior(
data=gp_numpyro_idata,
var_names=["kernel_amplitude", "kernel_length_scale", "noise"],
round_to=2,
kind="kde",
hdi_prob=0.94,
color="C0",
textsize=12,
ax=ax[0, :],
)
az.plot_posterior(
data=gp_pymc_idata,
var_names=["kernel_amplitude", "kernel_length_scale", "noise"],
round_to=2,
kind="kde",
hdi_prob=0.94,
color="C1",
textsize=12,
ax=ax[1, :],
)
fig.suptitle(
"GP - Posterior Distributions - NumPyro & PyMC Models",
fontsize=18,
fontweight="bold",
y=1.05,
);
Next, we generate samples from the posterior distribution over functions on the test set. Here is where the conditional method comes into play:
with gp_pymc_model:
x_star_data = pm.MutableData("x_star_data", x_test)
f_star = gp.conditional("f_star", x_star_data[:, None])
pm.Normal("likelihood_test", mu=f_star, sigma=noise)
gp_pymc_idata.extend(
pm.sample_posterior_predictive(
trace=gp_pymc_idata,
var_names=["f_star", "likelihood_test"],
random_seed=rng_subkey[1].item(),
)
)Finally, we plot the posterior distribution over functions on the test set of both the likelihood and the latent Gaussian process:
fig, ax = plt.subplots()
az.plot_hdi(
x_test,
gp_pymc_idata.posterior_predictive["likelihood_test"],
hdi_prob=0.94,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
gp_pymc_idata.posterior_predictive["likelihood_test"],
hdi_prob=0.5,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$50\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
gp_pymc_idata.posterior_predictive["f_star"],
hdi_prob=0.94,
color="C3",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$f \\: 94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
gp_pymc_idata.posterior_predictive["f_star"],
hdi_prob=0.5,
color="C3",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$f \\: 50\\%$ HDI (test)"},
ax=ax,
)
ax.plot(
x_test,
gp_pymc_idata.posterior_predictive["f_star"].mean(dim=("chain", "draw")),
color="C3",
linewidth=3,
label="posterior predictive mean (test)",
)
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
ax.scatter(x_test, y_test_obs, c="C1", label="observed (test)")
ax.plot(x_train, y_train, color="black", linewidth=3, alpha=0.7, label="mean (latent)")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=3)
ax.set(xlabel="x", ylabel="y")
ax.set_title("GP PyMC Model - Posterior Predictive", fontsize=18, fontweight="bold");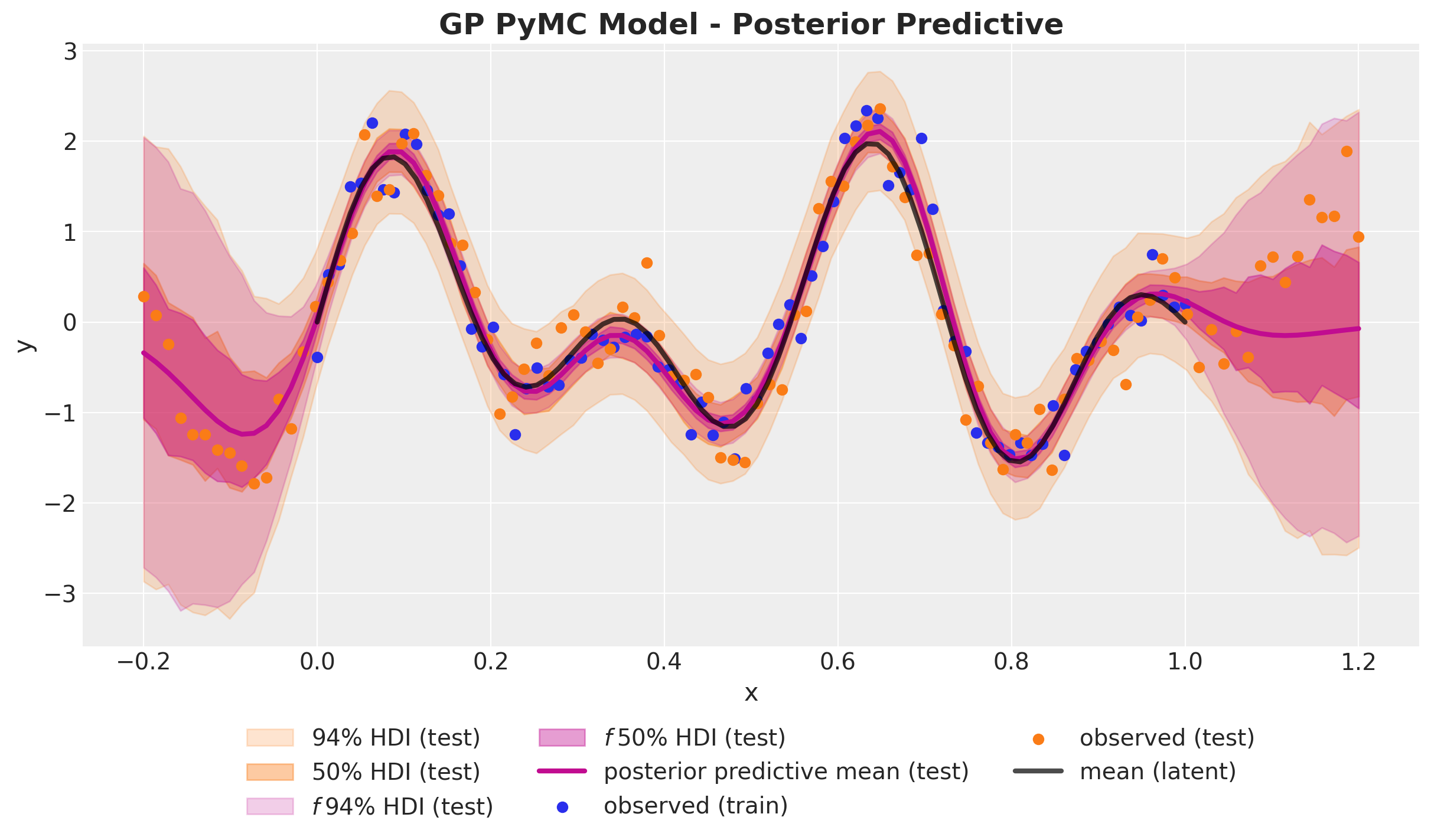
We again see that the posterior predictive distribution of both frameworks are almost the same 🙌!
Part II: Hilbert Space Gaussian Processes (HSGPs)
In this part we focus on the Hilbert Space Gaussian Process (HSGP) approximation method description following very closely the articles
- “Hilbert space methods for reduced-rank Gaussian process regression”
- “Practical Hilbert space approximate Bayesian Gaussian processes for probabilistic programming”
We strongly recommend looking into these articles to get the details of the method. Here we simply provide a description of the key ingredients and steps so that we can do a simple version of the implementation ourselves.
Why do we need an approximation? Gaussian processes do not scale well with the number of data points. Recall we had to invert the kernel matrix! The computational complexity of the Gaussian process model is \(\mathcal{O}(n^3)\), where \(n\) is the number of data points. This is due to the inversion of the kernel matrix. The HSGP approximation method is a way to reduce the computational complexity of the Gaussian process model \(\mathcal{O}(mn + m)\), where \(m\) is the number of basis functions used in the approximation.
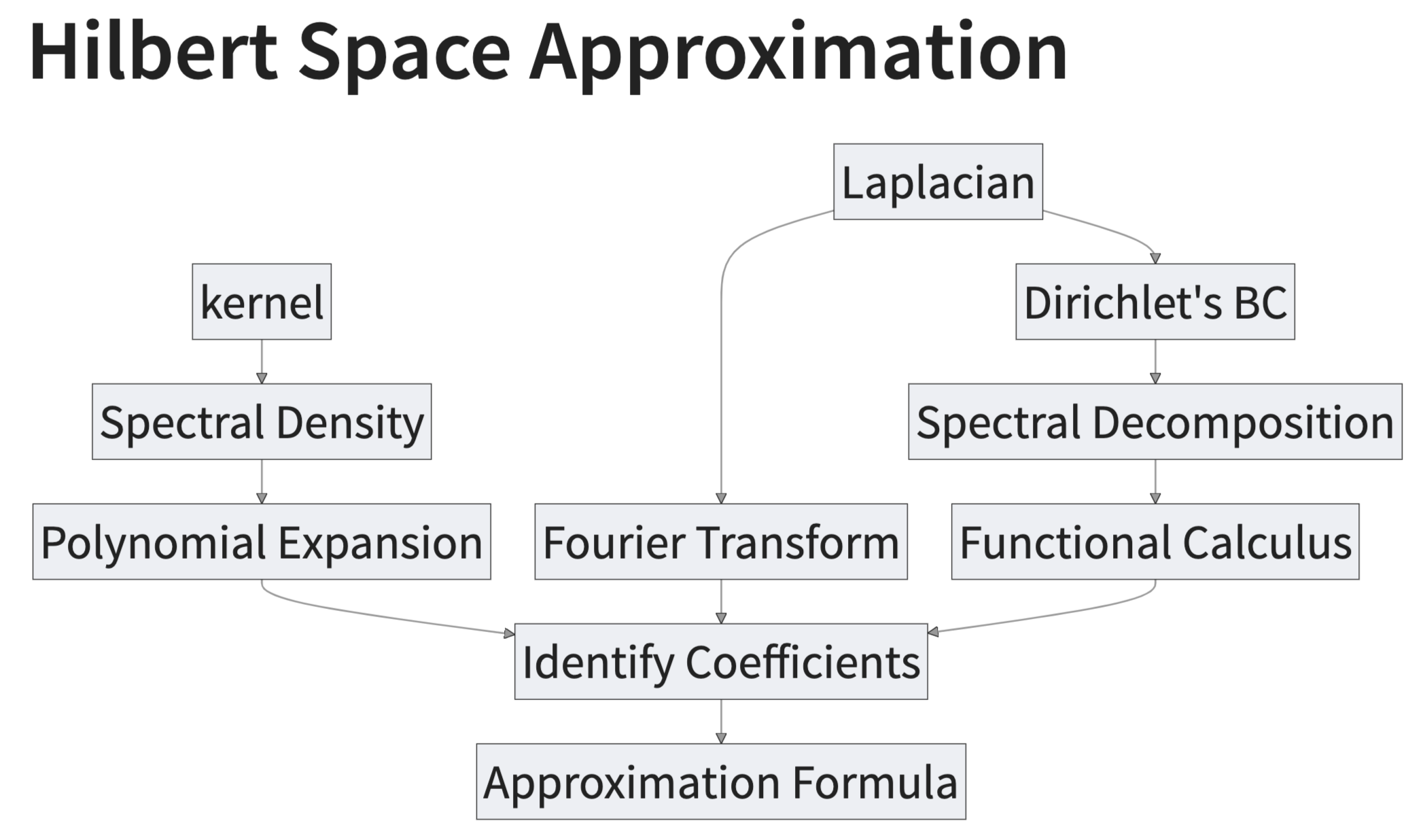
The outline of this part of the notebook is as follows:
First we briefly describe the scaling challenge to really understand the problem we are trying to solve with this approximation.
Then we do a linear algebra D-tour where we recall certain key results of eigenvalues and eigenvectors of a matrix. These concepts will appear constantly in the HSGP approximation method.
Finally we go through the main steps of the approximation.
Approach Summary 🤓
Let’s get the executive summary of the approximation strategy from Hilbert space methods for reduced-rank Gaussian process regression:
Strategy: Approximate the Gram matrix \(K\) with a matrix \(\tilde{K}\) with a smaller rank \(m < n\).
Key Idea: Interpret the covariance function as the kernel of a pseudo-differential operator and approximate it using Hilbert space methods.
Result: A reduced-rank approximation for the covariance function, where the basis functions are independent of the covariance functions and their parameters (plus asymptotic convergence).
We now break it down into more granular steps.
Approximation Strategy Steps:
- We recall the definition of the spectral density \(S(\omega)\) associated with a stationary kernel function \(k\).
- We approximate the spectral density \(S(\omega)\) as a polynomial series in \(||\omega||^2\).
- We can interpret these polynomial terms as “powers” of the Laplacian operator. The key observation is that the Fourier transform of the Laplacian operator is \(||\omega||^2\).
- Next, we impose Dirichlet boundary conditions on the Laplacian operator which makes it self-adjoint and with discrete spectrum (we do a D-tour in the main ideas and consequences of the spectral theorem).
- We identify the expansion in (2) with the sum of powers of the Laplacian operator in the eigenbasis of (4).
- We arrive at the final approximation formula and explicitly compute the terms for the squared exponential kernel in the one-dimensional case.
Here is a summary diagram of what we plan to discuss and how it comes together:
The Scaling Challenge
Why do Gaussian processes scale poorly with the number of data points? In the introduction of the paper “Hilbert space methods for reduced-rank Gaussian process regression” the authors give a great summary:
One of the main limitations of GPs in machine learning is the computational and memory requirements that scale as \(\mathcal{O}(n^3)\) and \(\mathcal{O}(n^2)\) in a direct implementation. This limits the applicability of GPs when the number of training samples \(n\) grows large. The computational requirements arise because in solving the GP regression problem we need to invert the \(n \times n\) Gram matrix \(K + \sigma_{n}^{2}I\), where \(K=k(x_i, x_j)\), which is an \(\mathcal{O}(n^3)\) operation in general.
Remark: In real applications, one does not invert the matrix but rather use the si called, Cholesky decomposition, since it is faster and numerically more stable. The Cholesky decomposition is an \(\mathcal{O}(n^3)\) operation and it is defined as a factorization of the form \(K = LL^{T}\) where \(L\) is a lower triangular matrix. See “Gaussian Processes for Machine Learning - Appendix A4: Cholesky Decomposition”.
The Spectral Theorem
In this small subsection we recall the main ideas of the spectral theorem. For a detailed practical introduction for the finite-dimensional case (i.e. matrices), please see my blog post “The Spectral Theorem for Matrices”. When we talk about spectrum we mean eigenvalues and eigenvectors of a matrix or operator. The spectral theorem is a statement that says that we can write any symmetric matrix as a sum of its eigenvectors and eigenvalues. In such representation (basis), the matrix becomes diagonal. There are generalizations of such result to much more general spaces and operators (e.g. differential operators).
Let’s work it out with a simple example. Consider the \(2 \times 2\) matrix:
\[ A = \begin{pmatrix} 1 & 2 \\ 2 & 1 \end{pmatrix} \]
A = jnp.array([[1.0, 2.0], [2.0, 1.0]])It is easy to see that the eigenvalues of \(A\) are \(\lambda_1 = 3\) and \(\lambda_2 = -1\) with eigenvectors:
\[ v_1 = \frac{1}{\sqrt{2}} \begin{pmatrix} 1 \\ 1 \end{pmatrix} \] and
\[ v_2 = \frac{1}{\sqrt{2}} \begin{pmatrix} -1 \\ 1 \end{pmatrix} \]
respectively. We include the \(1/\sqrt{2}\) factor so that \(\{v_1, v_2\}\) is an orthonormal basis of \(\mathbb{R}^2\). That is,
\[ v_1^{T} v_2 = 0 \quad \text{and} \quad v_1^{T} v_1 = v_2^{T} v_2 = 1 \]
We can see this numerically:
eigenvalues, eigenvectors = jnp.linalg.eig(A)
print(f"Eigenvalues: {eigenvalues}\nEigenvectors:\n{eigenvectors}")Eigenvalues: [ 3.+0.j -1.+0.j]
Eigenvectors:
[[ 0.70710678+0.j -0.70710678+0.j]
[ 0.70710678+0.j 0.70710678+0.j]]The spectral theorem states that we can always find such orthonormal basis of eigenvectors for a symmetric matrix. Observe that if we consider the change-of-basis matrix
\[ Q = \begin{pmatrix} v_1 & v_2 \end{pmatrix} \]
then we can write the matrix \(A\) in the new basis as
\[ D = Q^{T} A Q = \begin{pmatrix} 3 & 0 \\ 0 & -1 \end{pmatrix}. \]
We can verify this in JAX:
Q = eigenvectors
Q.T @ A @ QArray([[ 3.00000000e+00+0.j, 4.44089210e-16+0.j],
[ 6.10622664e-16+0.j, -1.00000000e+00+0.j]], dtype=complex128)Remark: Since \(Q\) is defined trough an orthonormal basis, then \(Q \in O(2)\) and \(QQ^{T} = Q^{T}Q = I_2\).
Q @ Q.TArray([[1.+0.j, 0.+0.j],
[0.+0.j, 1.+0.j]], dtype=complex128)Another important consequence of the spectral theorem is that we can decompose the matrix \(A\) as a sum of projections onto its eigenspaces. That is, we can write is as
\[ A = \sum_{j=1}^{2} \lambda_i v_j v_j^{T} \]
Observe that the operator \(P_{j} = v_j v_j ^{T}\) is indeed a projection operator, that is \(P^2 = P\) and \(P^T = P\), since the \(v_j\) constitute an orthonormal basis.
We can write each individual projection as:
def proj(v, x):
return jnp.dot(v, x) * vSo that the weighted sum of projections is the matrix \(A\):
def matrix_proj(x):
return eigenvalues[0] * proj(Q[:, 0], x) + eigenvalues[1] * proj(Q[:, 1], x)We can verify that the action on a vector \(x\) is the same as the action of the matrix \(A\):
- Eigenvector \(v_1\):
matrix_proj(Q[:, 0]) / eigenvalues[0]Array([0.70710678+0.j, 0.70710678+0.j], dtype=complex128)- Eigenvector \(v_2\):
matrix_proj(Q[:, 1]) / eigenvalues[1]Array([-0.70710678-0.j, 0.70710678-0.j], dtype=complex128)- Arbitrary vector \(v\):
v = jnp.array([1.0, 2.0])
jnp.allclose(jnp.dot(A, v), matrix_proj(v))Array(True, dtype=bool)The last consequence of the spectral theorem we want to mention is the functional calculus of operators. This is a generalization of the Taylor series for functions to operators. Given a function \(f\) we can define the operator \(f(A)\) as
\[ f(A) = \sum_{j=1}^{2} f(\lambda_j) v_j v_j^{T} \]
Observe that in particular cases:
- \(f(z) = z\) we recover the operator \(A\).
- \(f(z) = 1\) we recover the identity operator \(I\).
To illustrate this, we can evaluate the exponential of the matrix \(A\) defined as
\[ \exp(A) = \sum_{j=0}^{\infty} \frac{A^j}{j!} \]
We can use the existing implmenetation to compute this directly:
scipy.linalg.expm(A)Array([[10.22670818, 9.85882874],
[ 9.85882874, 10.22670818]], dtype=float64)On the other hand, we can use the fact that \(A = Q D Q^{T}\) and that \(Q\) is an orthogonal matrix to write
\[ \exp(A) = \sum_{j=0}^{\infty} \frac{(Q D Q^{T})^j}{j!} = Q \left(\sum_{j=0}^{\infty} \frac{D^j}{j!}\right) Q^{T} = Q \exp(D) Q^{T} \]
and observe that \(\exp(D)\) is a diagonal matrix with the exponential of the diagonal elements:
Q @ jnp.diag(jnp.exp(eigenvalues)) @ Q.TArray([[10.22670818+0.j, 9.85882874+0.j],
[ 9.85882874+0.j, 10.22670818+0.j]], dtype=complex128)We indeed see that both methods give the same result.
Through the functional calculus we can define a large class of operators by evaluating functions on the eigenvalues.
The spectral theorem has generalization to more general operators, including differential operators between Sobolev spaces. The theory is much more involved but the main ideas are the same. We do not go into details here (for a reference see “Unbounded Self-adjoint Operators on Hilbert Space” by Konrad Schmüdgen).
After this short D-tour, we are ready to go through the main steps of the HSGP approximation method.
Spectral Densities
In the case a kernel function is stationary, i.e. when the kernel just depends in the difference \(r := x - x'\) so that \(k(x, x') = k(x - x') = k(r)\) (for example, the square exponential), we can use certain spectral representation of the kernel function to write it as an integral operator. The spectral representation of a kernel function is given by (Bochner’s theorem)
\[ k(r) = \frac{1}{(2 \pi)^{d}}\int_{\mathbb{R}^{d}} e^{i \omega^{T} r} d\mu(\omega) \]
where \(\mu\) is a positive measure. If this measure has a density, it is called the spectral density \(S(\omega)\) corresponding to the covariance function \(k(r)\). That is, we can write the kernel function as
\[ k(x, x') = \frac{1}{(2 \pi)^{d}} \int_{\mathbb{R}^{d}} e^{i \omega^{T} r} S(\omega) d\omega \]
See “Gaussian Processes for Machine Learning - Chapter 4: Covariance Functions”.
Remark: In the context of unbounded operators the spectral theorem can be stated in the language of spectral projections and measures. This is way out of the scope of this exposition. Nevertheless, it is interesting to see how the spectral theorem at this level can have key implications for concrete applications.
Remark: Note the similarity between the spectral density and the Fourier transform. For Gaussian-like kernels, like the squared exponential, we therefore expect the associated spectral density to also be Gaussian-like. Of course, we care about the constants and parameters of the kernel. This motivates the following example.
Example: For the squared exponential kernel, it can be shown that the spectral density is given by
\[ S(\omega) = a^2(2 \pi \ell^2)^{d/2} \exp\left(-2\pi^2\ell^2\omega^2\right) \]
where \(a\) is the amplitude and \(\ell\) is the length-scale parameter.
For the special case \(d=1\) we have
\[ S(\omega) = a^2 \sqrt{2 \pi} \ell \exp\left(-2\pi^2\ell^2\omega^2\right) \]
We can write this spectral density as a function in JAX:
def squared_exponential_spectral_density(w, amplitude, length_scale):
c = amplitude**2 * jnp.sqrt(2 * jnp.pi) * length_scale
e = jnp.exp(-0.5 * (length_scale**2) * (w**2))
return c * eFor an amplitude of one, we can plot the spectral density for different length-scales:
w = jnp.linspace(start=0, stop=10, num=100)
length_scales = [0.3, 0.5, 1.0, 2.0]
fig, ax = plt.subplots()
for i, length_scale in enumerate(length_scales):
ax.plot(
w,
squared_exponential_spectral_density(
w, amplitude=1.0, length_scale=length_scale
),
c=f"C{i}",
linewidth=3,
label=f"length_scale={length_scale}",
)
ax.legend(loc="upper right")
ax.set(xlabel="Frequency ($\\omega$)", ylabel="Spectral Density $S(\\omega)$")
ax.set_title("Squared Exponential Spectral Density", fontsize=18, fontweight="bold");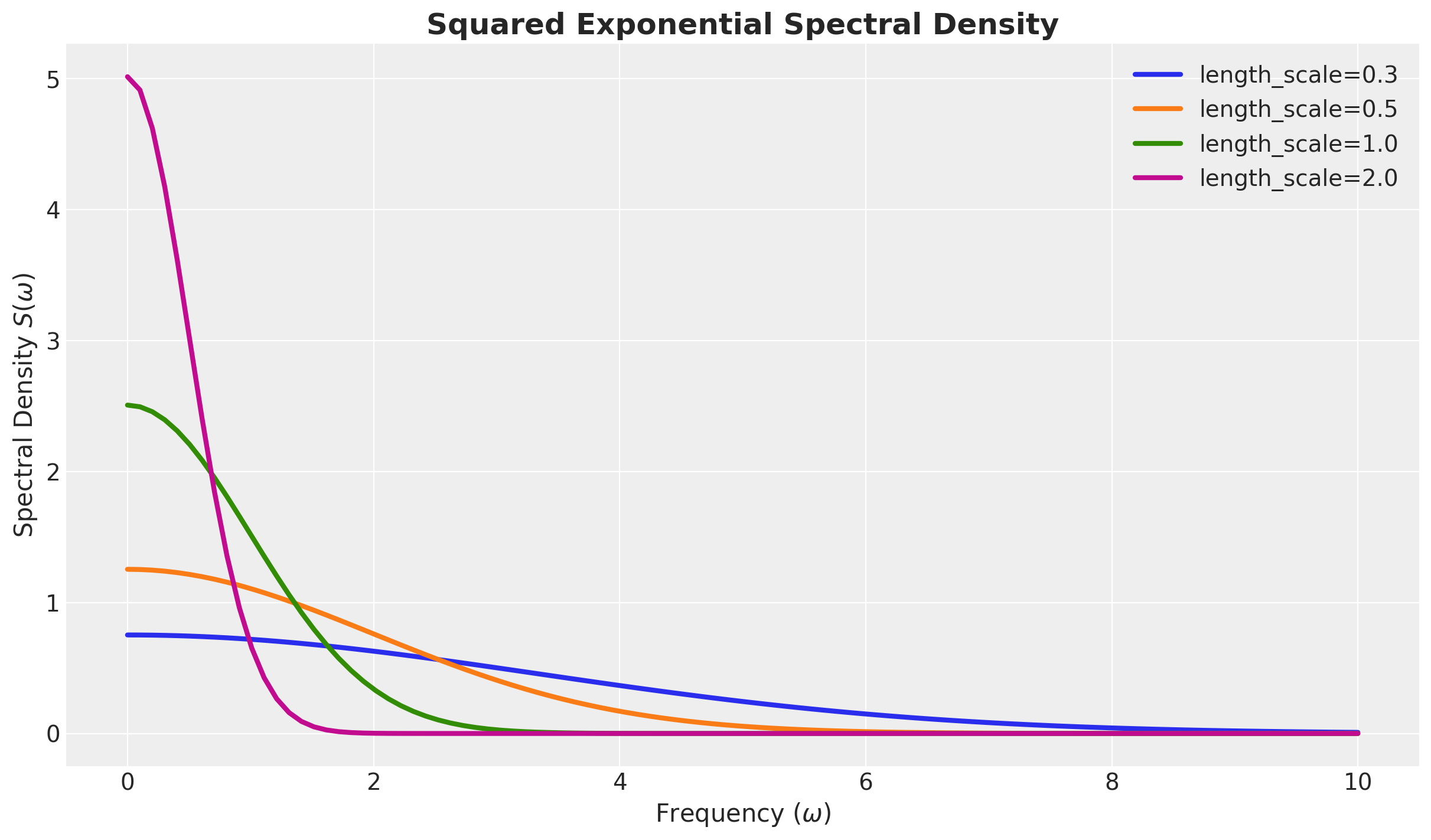
Observe that the spectral density is a bell-shaped curve centered at zero. In particular they decay fast at infinity. The length-scale parameter controls the width of the curve. The larger the length-scale, the narrower the curve.
Remark [On the interpretation of spectral densities from Rasmussen & Williams]: The complex exponentials \(\exp(2 \pi i \omega x)\) are eigenfunctions of a stationary kernel \[ k(x, x') = \int_{\mathbb{R}} e^{2\pi i \omega (x - x')} d\mu \] with respect to Lebesgue measure \(d\mu\) . Thus \(S(\omega)\) is, loosely speaking, the amount of power allocated on average to the eigenfunction \(\exp(2\pi i \omega x)\) with frequency \(\omega\).
Formal Power Expansion of the Spectral Density
Next, we describe a convenient polynomial expansion of an spectral density, just like we do with Taylor series for functions. On the way, I will add comments relevant for the audience familiar with (pseudo) differential operators. This is not necessary to understand the main ideas but it is a nice connection to other areas of mathematics.
Let us assume the kernel function is isotropic, i.e. it only depends on the Euclidean (or \(L^2\)) norm \(||r||\). In this case the associated spectral density \(S(\omega)\) is also isotropic, i.e. \(S(\omega) = S(||\omega||)\). We can formally write \(S(||\omega||) = \psi(||\omega||^2)\) for a suitable function \(\psi\). We can expand \(\psi\) (for example, by requiring that \(\psi\) is an analytic function) in a power series:
\[ S(||\omega||) = \psi(||\omega||^2) = a_0 + a_1 (||\omega||^2) + a_2 (||\omega||^2)^2 + a_3 (||\omega||^2)^3 + \cdots \]
Fourier Transform of the Laplacian
At first sight, it looks very strange to expand the spectral density in terms of \(||\omega||^2\) instead of \(\omega\). The reason for this, as we will see below, is that we want to match this expansion with the one coming from the Laplace operator (via the spectral theorem). As the Laplace operator is a second order differential operator, its Fourier transform is a second order polynomial in \(\omega\) (recall that the Fourier transform maps derivatives to polynomials). This is the link 😉!
Concretely, if we denote by \(\mathcal{F}\) the Fourier transform operator, then
\[ \mathcal{F}[\nabla^2 f](\omega) = - ||\omega||^2 \mathcal{F}[f] \]
Remark [Ellipticity]: This also shows that the Laplacian is an elliptic operator, as its principal symbol (highest order of the Fourier transform) is \(||\omega||^2\), which is invertible for \(\omega \neq 0\). This is a key property for the existence of discrete eigenvalues and eigenfunctions.
Given the above, we can connect the spectral density expansion with the Laplacian operator by taking the inverse Fourier transform of the expansions of the spectral density. This will give us a polynomial expansion of the kernel operator
\[ \mathcal{K} := \int_{\mathbb{R}^d} k(\cdot, x')\phi(x') dx' \]
in terms of the Laplacian operator:
\[ \mathcal{K} = a_0 + a_1 (- \nabla^2) + a_2 (-\nabla^2)^2 - a_3 (-\nabla^2)^3 + \cdots \]
which is not a differential operator but a pseudo-differential operator.
Our goal now is to use the spectral decomposition of the Laplacian (in terms of things we can explicitly compute) to approximate the kernel operator using the formula above. This is the main idea behind the Hilbert space approximation.
Dirichlet’s Laplacian
Recall that an unbounded operator is not only defined by its action, but also by its domain of definition. In the case of the Laplacian on an open domain \(\Omega \subset \mathbb{R}^d\) (with boundary \(\partial \Omega\) sufficiently smooth), we need to specify the boundary conditions. The most common boundary conditions are the Dirichlet boundary conditions, which are defined by requiring that the function vanishes on the boundary of the domain. The Laplacian with Dirichlet boundary conditions is a self-adjoint operator defined on the Hilbert space \(L^{2}(\Omega)\) equipped with the Lebesgue measure. That is, it satisfies the following property:
\[ \int_{\Omega} (-\nabla^2 f(x)) g(x) dx = \int_{\Omega} f(x) (-\nabla^2 g(x)) dx \]
In addition, it has discrete spectrum with eigenvalues \(\lambda_j \rightarrow \infty\) and eigenfunctions \(\phi_j\) that form an orthonormal basis of \(L^2(\Omega)\), so that \[ \int_{\Omega} \phi_{j}(x) \phi_{k}(x) dx = \delta_{jk} \]
Example [One Dimension]: One can easily find the spectral decomposition of the Laplacian on the interval \([-L, L]\) with Dirichlet boundary conditions. We just need to solve the equation
\[ \frac{d^2 \phi}{dx^2} = - \lambda \phi \quad \text{with} \quad \phi(-L) = \phi(L) = 0 \]
It is easy to see that the solutions are given by
\[ \phi_j(x) = \sqrt{\frac{1}{L}} \sin\left(\frac{\pi j (x + L)}{2L}\right) \]
with eigenvalues
\[ \lambda_j = \left(\frac{j \pi}{2L}\right)^2. \]
Hilbert Space Gaussian Process Approximation
Using the functional calculus of the spectral decomposition (see details in the section above), one can write the Laplacian as acting on function \(f\) in the domain of definition as:
\[ -\nabla^2 f(x) = \int_{\Omega} l(x, x') f(x') dx' \]
where
\[ l(x, x') = \sum_{j} \lambda_{j} \phi_{j}(x) \phi_{j}(x') \]
is the kernel operator associated with the Laplacian. Note that this resembles the finite-dimensional case, where we use the dot product instead of the integral.
The functional calculus allows us to consider powers of the Laplacian \((- \nabla^2)^{s}\),
\[ (- \nabla^2)^{s} f(x) = \int_{\Omega} l^{s}(x, x') f(x') dx'. \]
We can use this expression and compare it with the expansion of the spectral density to approximate the kernel operator of the Gaussian process:
\[\begin{align*} & \left[ a_{0} + a_{1}(-\nabla^2) + a_{2}(-\nabla^2)^2 + \cdots \right]f(x) = \\ &\int_{\Omega} \left[a_{0} + a_{1} l(x, x') + a_{2} l^{2}(x, x') + \cdots \right] f(x') dx' \end{align*}\]
This implies we can approximate the kernel as
\[\begin{align*} k(x, x') \approx & \: a_{0} + a_{1} l(x, x') + a_{2} l^{2}(x, x') + \cdots \\ \approx & \sum_{j} \left[ a_{0} + a_{1} \lambda_{j} + a_{2} \lambda_{j}^2 + \cdots \right] \phi_{j}(x) \phi_{j}(x') \end{align*}\]
which is only an approximation to the covariance function due to the restriction of the domain to Ω and the boundary conditions.
Finally, recall that the coefficients \(a_j\) were defined by the polynomial expansion of the spectral density, so if we take \(||\omega||^2 = \lambda_j\) then we arrive at the final expression for the approximation formula:
\[ \boxed{ k(x, x') \approx \sum_{j} S(\sqrt{\lambda_j})\phi_{j}(x) \phi_{j}(x') } \]
That is, the model of the Gaussian process \(f\) can be written as
\[ f(x) \sim \text{MultivariateNormal}(\boldsymbol{\mu}, \Phi\mathcal{D}\Phi^{T}) \]
where \(\mathcal{D} = \text{diag}(S(\sqrt{\lambda_1}), S(\sqrt{\lambda_2}), \ldots, S(\sqrt{\lambda_{m}}))\).
As a result, we can write the approximation as
\[ f(x) \approx \sum_{j = 1}^{m} \overbrace{\color{red}{\left(S(\sqrt{\lambda_j})\right)^{1/2}}}^{\text{all hyperparameters are here!}} \times \underbrace{\color{blue}{\phi_{j}(x)}}_{\text{easy to compute!}} \times \overbrace{\color{green}{\beta_{j}}}^{\sim \: \text{Normal}(0,1)} \]
From where we see two important properties:
The only dependence on the hyperparameters is through the spectral density.
The computational cost of evaluating the log posterior density of univariate HSGPs scales as \(\mathcal{O}(nm + m)\).
Example [One Dimension]: Coming back to the one-dimensional case, we can use this formula to approximate the squared exponential kernel in terms of the Dirichlet’s Laplacian on the interval \([-L, L]\),
\[ k(x, x') \approx \sum_{j} \underbrace{a^2 \sqrt{2 \pi} \ell \exp\left(-2\pi^2\ell^2 \left(\frac{\pi j}{2L}\right)^2 \right) }_{S(\sqrt{\lambda_j})} \overbrace{\left(\sqrt{\frac{1}{L}} \sin\left(\frac{\pi j (x + L)}{2L}\right)\right)}^{\phi_{j}(x)} \overbrace{\left(\sqrt{\frac{1}{L}} \sin\left(\frac{\pi j (x' + L)}{2L}\right)\right)}^{\phi_{j}(x')} \]
In the next section we use this formula to approximate the squared exponential kernel in the one-dimensional case.
Remark: Note that the eigenvectors \(\phi_j\) do not depend on the kernel parameters \(a\) and \(\ell\). This is a key property as this is essentially reducing the problem to a linear regression problem in the eigenvector basis. This is where the speed-up comes from 🤓!
NumPyro Hilbert Space Gaussian Process Model
Now that we have a theoretical understanding of the Hilbert space Gaussian process approximation and have explicit formulas for the case of the squared exponential kernel in one dimension, we can implement the approximation in JAX and NumPyro for the same synthetic data as before. We follow closelly the implementation described in NumPyro’s documentation “Example: Hilbert space approximation for Gaussian processes”.
Hilbert Space Approximation Step by Step
In the last part we already implemented the spectral density for the squared exponential kernel in one dimension. Next, we need to write the expressions of the eigenvalues and eigenvector of the Laplacian in the interval \([-L, L]\) (we use the l_max for \(L\) as we do not like upper-case for function arguments 😅).
def laplacian_sqrt_eigenvalues(l_max: float, m: int):
sqrt_base_eigenvalue = jnp.pi / (2 * l_max)
return sqrt_base_eigenvalue * jnp.arange(1, 1 + m)
def diag_squared_exponential_spectral_density(
amplitude: float, length_scale: float, l_max: float, m: int
):
sqrt_eigenvalues = laplacian_sqrt_eigenvalues(l_max, m)
return squared_exponential_spectral_density(
sqrt_eigenvalues, amplitude, length_scale
)Recall that the weights in the approximation formula are given by the spectral density evaluated on the square root of the eigenvalues of the Laplacian. Let’s see how these look for various length scales and fixed amplitude \(a=1\) and box length \(L=1.5\).
m = 8
l_max = 1.5
fig, ax = plt.subplots()
for i, length_scale in enumerate(length_scales):
ax.plot(
laplacian_sqrt_eigenvalues(l_max=l_max, m=m),
diag_squared_exponential_spectral_density(
amplitude=1.0, length_scale=length_scale, l_max=l_max, m=m
),
marker="o",
c=f"C{i}",
linewidth=3,
markersize=8,
label=f"length_scale={length_scale}",
)
ax.legend(loc="upper right")
ax.set(
xlabel="Laplacian Sqrt Eigenvalue $\\sqrt{\\lambda}$",
ylabel="Spectral Density $S(\\sqrt{\\lambda})$",
)
ax.set_title(
"""Squared Exponential Spectral Density
as a Function of the Laplacian Eigenvalues (sqrt)
""",
fontsize=18,
fontweight="bold",
);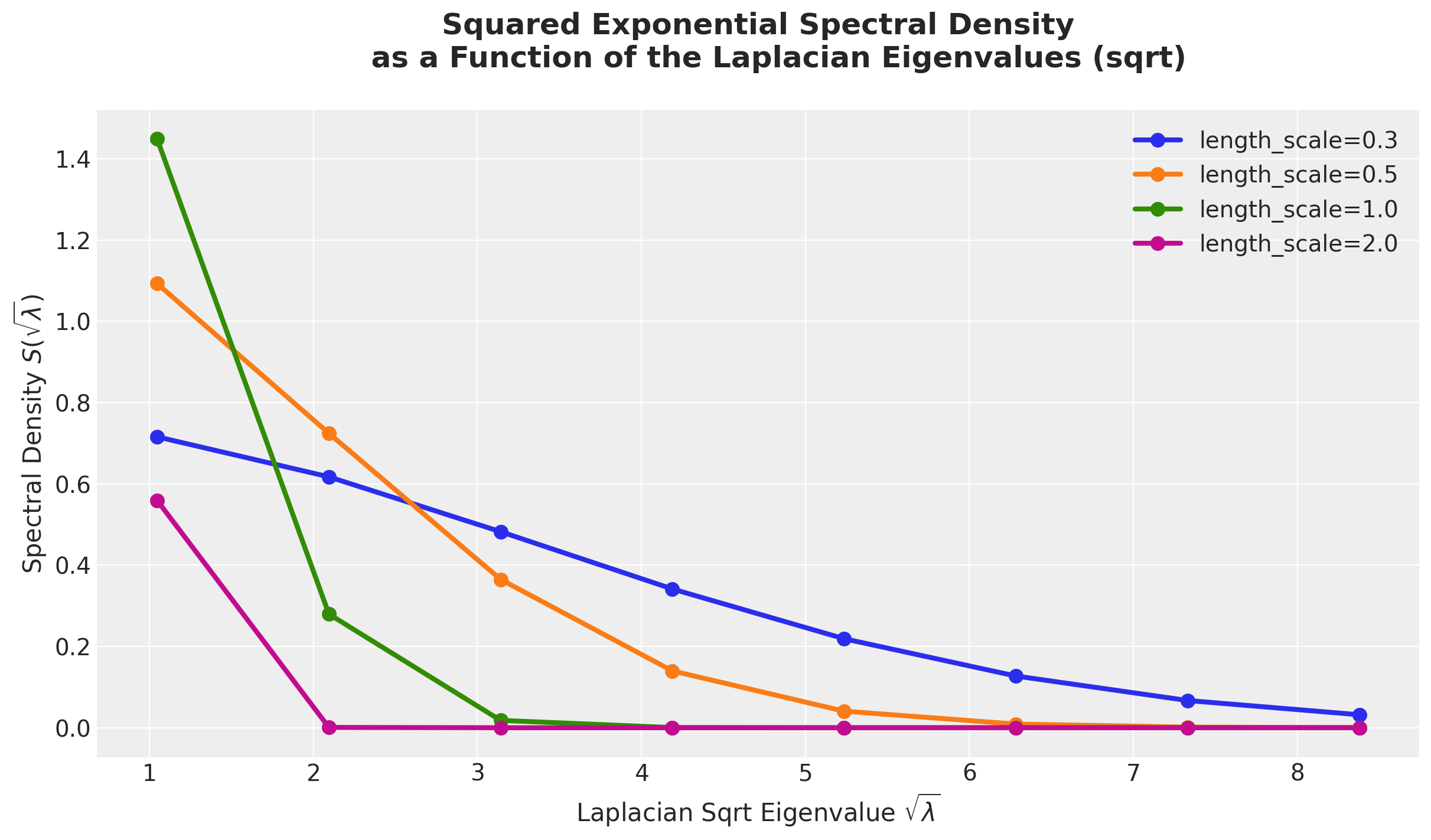
From this plot we see how the concentration of the spectral density varies with the langth-scale parameter. The larger the length-scale, the more concentrated the spectral density is around zero.
We continue by looking into the Laplacian eigenfunctions
\[ \phi_j(x) = \sqrt{\frac{1}{L}} \sin\left(\frac{\pi j (x + L)}{2L}\right) \]
We can compute them in a vectorized way:
def laplace_eigenfunctions(x, l_max, m):
sqrt_eigenvalues = laplacian_sqrt_eigenvalues(l_max, m)
rep_x = jnp.tile(l_max + x[:, None], reps=m)
diag_sqrt_eigenvalues = jnp.diag(sqrt_eigenvalues)
num = jnp.sin(rep_x @ diag_sqrt_eigenvalues)
den = jnp.sqrt(l_max)
return num / den
phi = laplace_eigenfunctions(x_train, l_max, m)
assert phi.shape == (n_train, m)We can visualize the first few eigenfunctions on the domain of the training data:
fig, ax = plt.subplots()
for i in range(m):
ax.plot(
x_train,
phi[:, i],
linewidth=3,
c=f"C{i}",
label=f"eigenfunction {i + 1}",
)
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=4)
ax.set(xlabel="x", ylabel="eigenfunction value")
ax.set_title("Laplacian Eigenfunctions", fontsize=18, fontweight="bold");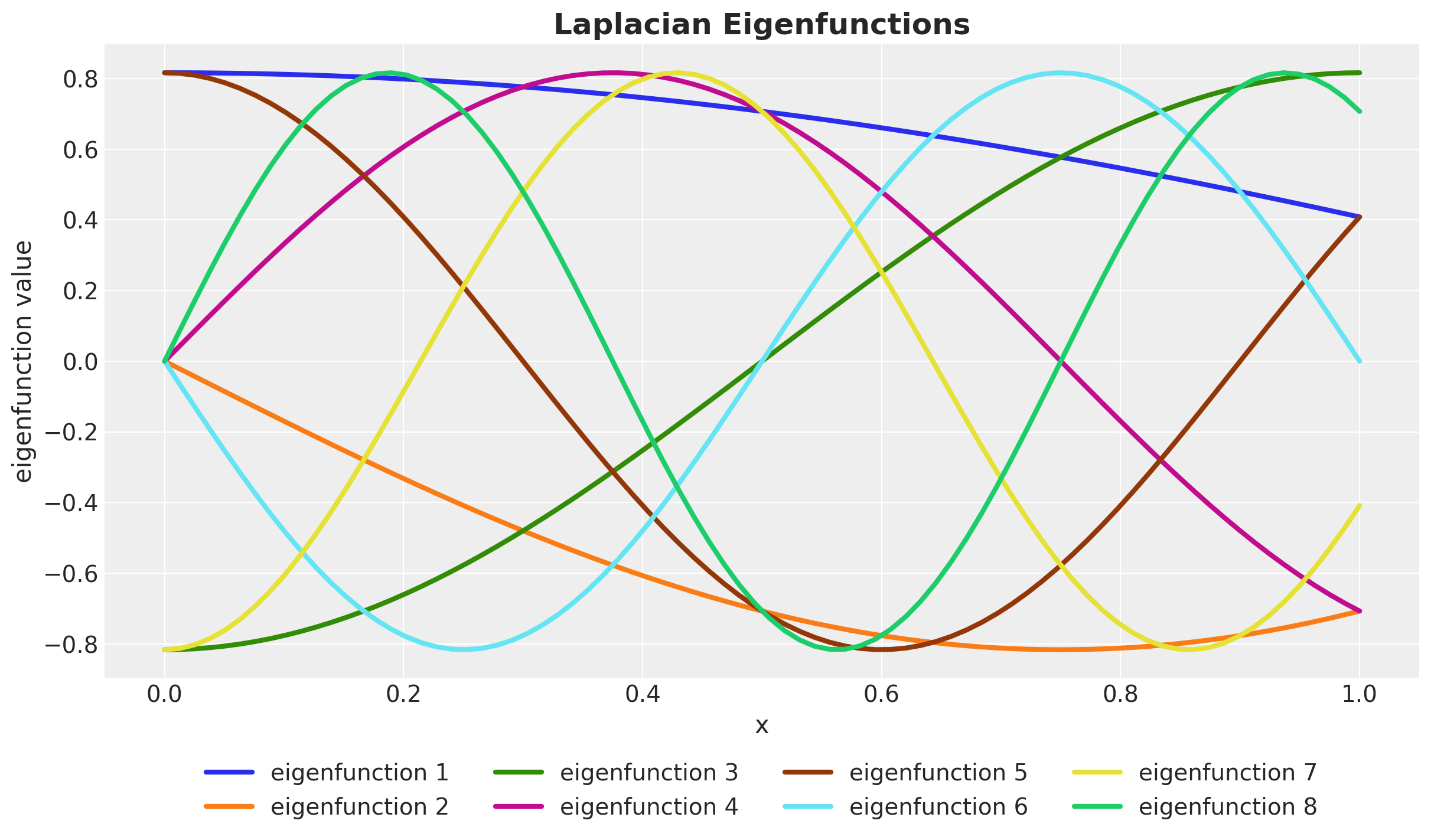
Remark: Although it is not strictly necessary, it is recommended to center the training data x_train so that it has mean zero and it is symmetrically located in a bounded box \([-L, L]\). This is automatically handled in the PyMC implementation as we will see below (see “Practical Hilbert space approximate Bayesian Gaussian processes for probabilistic programming”).
Now we can put everything together as a function that computes the Hilbert space approximation of the squared exponential kernel in one dimension:
def hs_approx_squared_exponential_ncp(x, amplitude, length_scale, l_max, m):
phi = laplace_eigenfunctions(x, l_max, m)
spd = jnp.sqrt(
diag_squared_exponential_spectral_density(amplitude, length_scale, l_max, m)
)
with numpyro.plate("basis", m):
beta = numpyro.sample("beta", dist.Normal(0, 1))
return numpyro.deterministic("f", phi @ (spd * beta))Remark: This implementation is using the so called non-centered parametrization. It is the same mathematical model but just written in a way that it samples more efficiently. This is a common practice in hierarchical models. The main idea is that sampling from a normal distribution
\[x \sim \text{Normal}(\mu, \sigma)\]
is equivalent to sampling from the standard normal distribution and then transforming the samples as
\[x = \mu + \sigma z \quad \text{with} \quad z \sim \text{Normal}(0, 1).\]
For details, see the example “A Primer on Bayesian Methods for Multilevel Modeling”.
In order to get a feeling on the implementation, let’s sample from this component using the mean of the parameters (amplitude and length-scale) from the model fitted in the first part. We use take \(40\) samples with \(m=8\) eigenfunctions to approximate the kernel and we keep the box size \(L=1.5\).
# prior sample from the HSGP component
def prior_sample_f_approx_se_ncp(rng_key, *args, **kwargs):
model = seed(hs_approx_squared_exponential_ncp, rng_key)
model_trace = trace(model).get_trace(*args, **kwargs)
return model_trace["f"]["value"]
# set parameters
m = 8
l_max = 1.5
amplitude = gp_mcmc.get_samples()["kernel_amplitude"].mean()
length_scale = gp_mcmc.get_samples()["kernel_length_scale"].mean()
# vectorize the computation
# see https://num.pyro.ai/en/stable/tutorials/bayesian_regression.html#Predictive-Utility-With-Effect-Handlers
vmap_prior_sample_f_approx_se_ncp = vmap(
lambda rng_key: prior_sample_f_approx_se_ncp(
rng_key=rng_key,
x=x_train,
amplitude=amplitude,
length_scale=length_scale,
l_max=l_max,
m=m,
),
in_axes=0,
out_axes=-1,
)n_prior_samples = 40
rng_key, rng_subkey = random.split(rng_key)
prior_samples_f_approx_se_ncp = vmap_prior_sample_f_approx_se_ncp(
rng_key=random.split(rng_subkey, n_prior_samples)
)
fig, ax = plt.subplots()
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
ax.plot(x_train, y_train, color="black", linewidth=3, alpha=0.7, label="mean (latent)")
ax.plot(x_train, prior_samples_f_approx_se_ncp, c="C3", alpha=0.5, linewidth=0.5)
ax.plot(
x_train,
prior_samples_f_approx_se_ncp[:, 0],
c="C3",
alpha=1,
linewidth=2,
label="prior sample (given amplitude and length_scale)",
)
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=3)
ax.set(xlabel="x", ylabel="y")
ax.set_title(
"HSGP Prior Samples (Given Amplitude and Length Scale)",
fontsize=18,
fontweight="bold",
);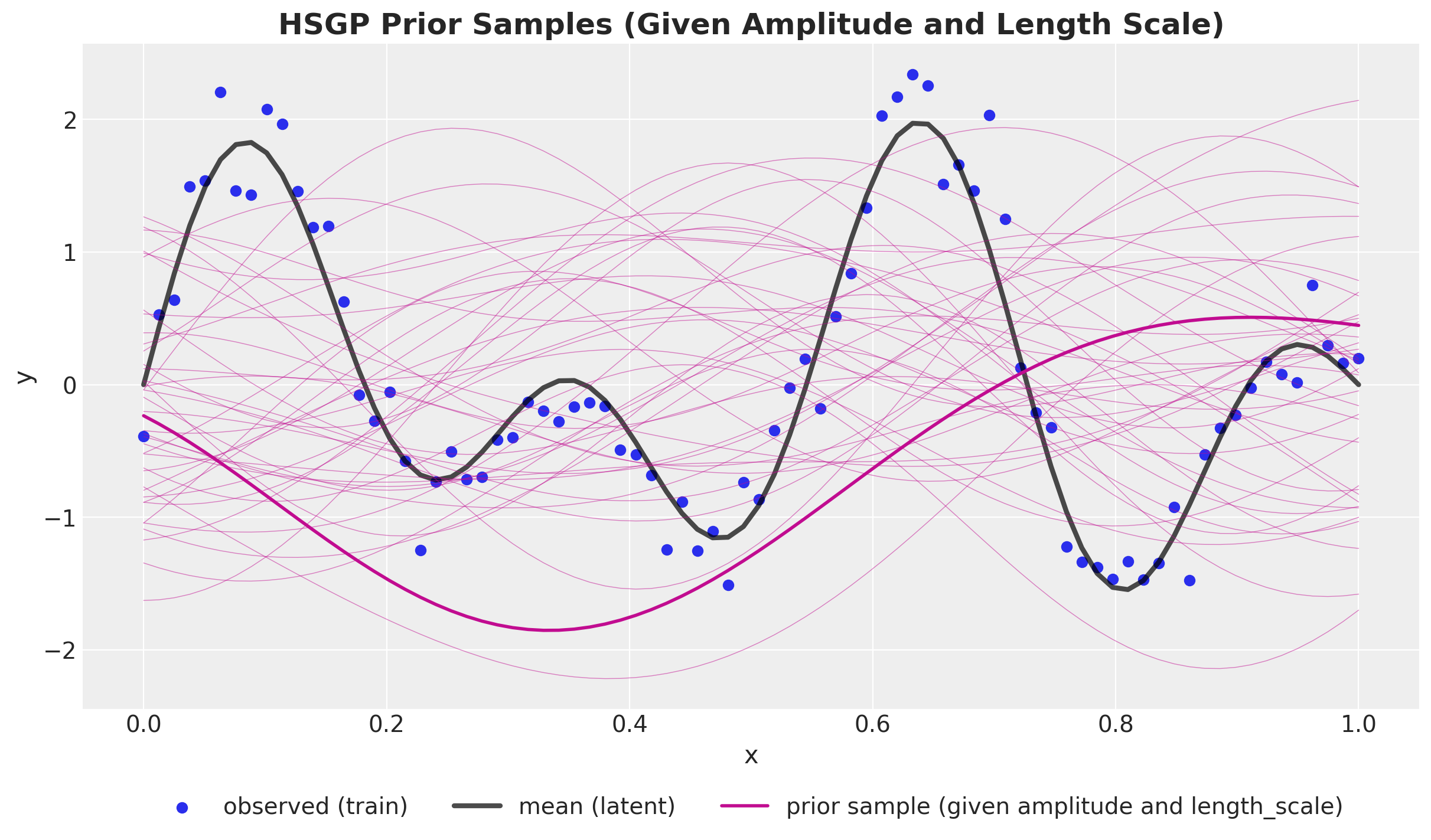
These prior predictive samples look very reasonable!
Model Specification
Having implemented the Hilbert space approximation component, we are ready to define the whole model in NumPyro. We use the same priors for the amplitude and length-scale parameters as in the first part. We also use the same priors for the noise parameter.
def hsgp_model(x, l_max, m, y=None) -> None:
"""Hilbert Space Gaussian Process (HSGP) model with a
squared-exponential kernel in one dimension.
Parameters
----------
x : feature variable
l_max : box size L (well, the box size is in fact 2L)
m : number of eigenfunctions to select
y : target variable
"""
# --- Priors ---
kernel_amplitude = numpyro.sample(
"kernel_amplitude",
dist.InverseGamma(
concentration=inverse_gamma_params_2["alpha"],
rate=inverse_gamma_params_2["beta"],
),
)
kernel_length_scale = numpyro.sample(
"kernel_length_scale",
dist.InverseGamma(
concentration=inverse_gamma_params_1["alpha"],
rate=inverse_gamma_params_1["beta"],
),
)
noise = numpyro.sample(
"noise",
dist.InverseGamma(
concentration=inverse_gamma_params_2["alpha"],
rate=inverse_gamma_params_2["beta"],
),
)
# --- Parametrization ---
f = hs_approx_squared_exponential_ncp(
x, kernel_amplitude, kernel_length_scale, l_max, m
)
# --- Likelihood ---
with numpyro.plate("data", x.shape[0]):
numpyro.sample("likelihood", dist.Normal(loc=f, scale=noise), obs=y)numpyro.render_model(
model=hsgp_model,
model_kwargs={"x": x_train, "l_max": 1.5, "m": 8, "y": y_train_obs},
render_distributions=True,
render_params=True,
)
Prior Predictive Check
For this specific example we choose:
l_max = 1.3
m = 20Before fitting the model to the data, we can use the model above to generate samples from the prior distribution over functions.
hsgp_numpyro_prior_predictive = Predictive(hsgp_model, num_samples=1_000)
rng_key, rng_subkey = random.split(rng_key)
hsgp_numpyro_prior_samples = hsgp_numpyro_prior_predictive(
rng_subkey, x_train, l_max, m
)
hsgp_numpyro_prior_idata = az.from_numpyro(prior=hsgp_numpyro_prior_samples)fig, ax = plt.subplots()
az.plot_hdi(
x_train,
hsgp_numpyro_prior_idata.prior["likelihood"],
hdi_prob=0.94,
color="C0",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_train,
hsgp_numpyro_prior_idata.prior["likelihood"],
hdi_prob=0.5,
color="C0",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$50\\%$ HDI (test)"},
ax=ax,
)
ax.plot(
x_train,
hsgp_numpyro_prior_idata.prior["likelihood"].mean(dim=("chain", "draw")),
color="C0",
linewidth=3,
label="posterior predictive mean (test)",
)
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
for i in range(5):
label = "prior samples" if i == 0 else None
ax.plot(
x_train,
hsgp_numpyro_prior_idata.prior["likelihood"].sel(chain=0, draw=i),
color="C0",
alpha=0.3,
label=label,
)
ax.plot(x_train, y_train, color="black", linewidth=3, alpha=0.7, label="mean (latent)")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=3)
ax.set(xlabel="x", ylabel="y")
ax.set_title("HSGP NumPyro Model - Prior Predictive", fontsize=18, fontweight="bold");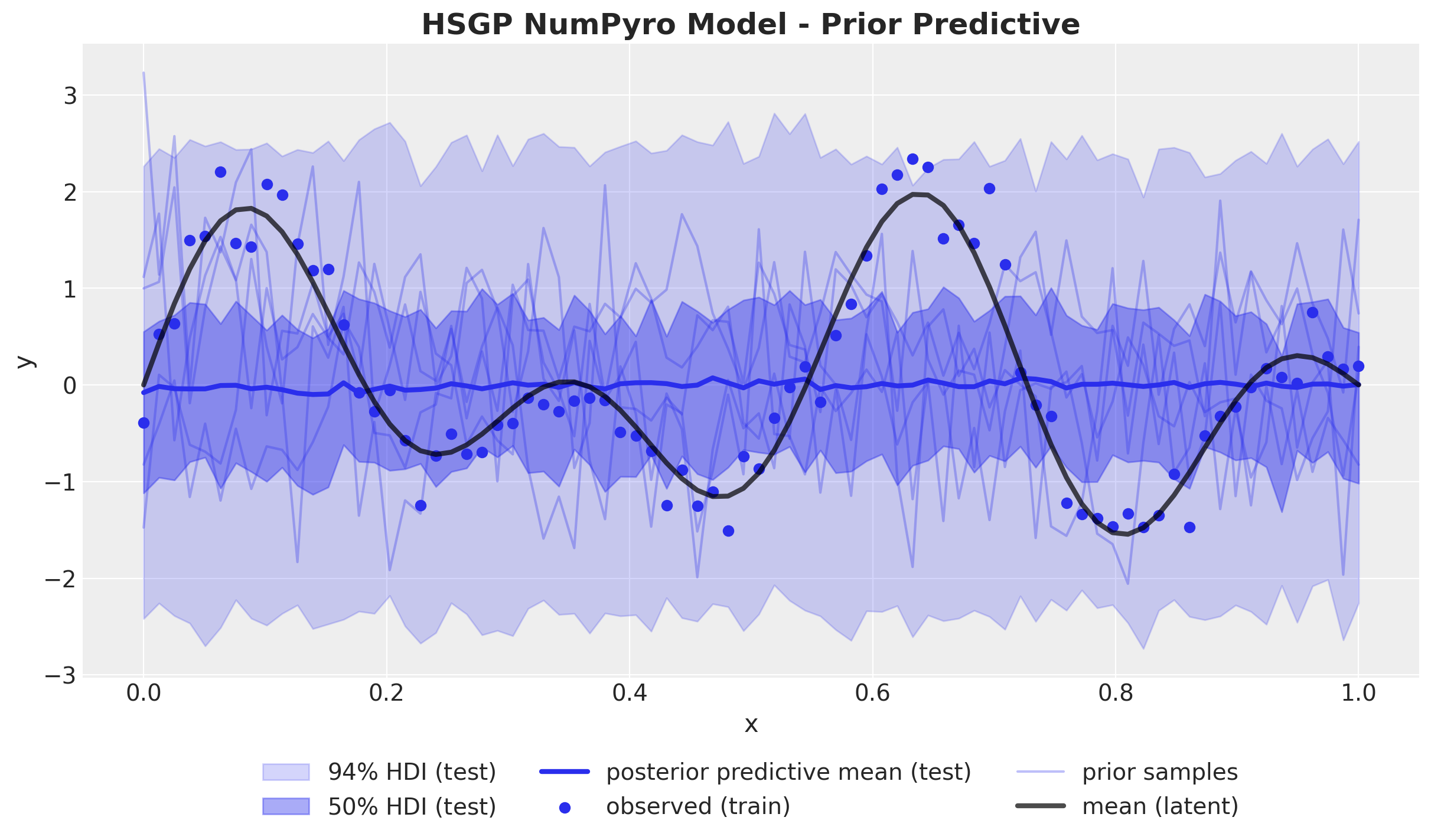
The prior predictive samples look similar to the ones from the first part (vanilla Gaussian process model).
Model Fitting
We can fit the model as usual:
rng_key, rng_subkey = random.split(rng_key)
hsgp_mcmc = run_inference(
rng_subkey,
hsgp_model,
inference_params,
x_train,
l_max,
m,
y_train_obs,
target_accept_prob=0.9,
)Observe that it runs very fast!
Model Diagnostics
The model diagnostics look good:
hsgp_numpyro_idata = az.from_numpyro(posterior=hsgp_mcmc)
az.summary(
data=hsgp_numpyro_idata,
var_names=["kernel_amplitude", "kernel_length_scale", "noise", "beta"],
)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| kernel_amplitude | 1.283 | 0.254 | 0.842 | 1.740 | 0.004 | 0.003 | 4465.0 | 5147.0 | 1.0 |
| kernel_length_scale | 0.077 | 0.012 | 0.055 | 0.098 | 0.000 | 0.000 | 7337.0 | 5679.0 | 1.0 |
| noise | 0.327 | 0.029 | 0.275 | 0.382 | 0.000 | 0.000 | 10151.0 | 5634.0 | 1.0 |
| beta[0] | -0.121 | 0.654 | -1.349 | 1.097 | 0.008 | 0.007 | 6735.0 | 5550.0 | 1.0 |
| beta[1] | -0.006 | 0.721 | -1.382 | 1.309 | 0.009 | 0.008 | 6754.0 | 5913.0 | 1.0 |
| beta[2] | -0.006 | 0.676 | -1.357 | 1.183 | 0.008 | 0.007 | 6529.0 | 5918.0 | 1.0 |
| beta[3] | 0.236 | 0.725 | -1.156 | 1.564 | 0.009 | 0.008 | 6355.0 | 6020.0 | 1.0 |
| beta[4] | -0.164 | 0.692 | -1.504 | 1.130 | 0.009 | 0.007 | 5802.0 | 5631.0 | 1.0 |
| beta[5] | 0.061 | 0.752 | -1.315 | 1.503 | 0.009 | 0.008 | 7008.0 | 5944.0 | 1.0 |
| beta[6] | -0.373 | 0.726 | -1.748 | 0.968 | 0.009 | 0.007 | 7131.0 | 5508.0 | 1.0 |
| beta[7] | 0.422 | 0.764 | -1.052 | 1.845 | 0.009 | 0.008 | 7514.0 | 5620.0 | 1.0 |
| beta[8] | 0.604 | 0.734 | -0.793 | 1.977 | 0.009 | 0.007 | 7412.0 | 5687.0 | 1.0 |
| beta[9] | -1.300 | 0.787 | -2.762 | 0.194 | 0.009 | 0.007 | 7615.0 | 6307.0 | 1.0 |
| beta[10] | 0.305 | 0.727 | -1.024 | 1.667 | 0.009 | 0.007 | 6679.0 | 6302.0 | 1.0 |
| beta[11] | 1.025 | 0.742 | -0.382 | 2.412 | 0.009 | 0.007 | 6983.0 | 6127.0 | 1.0 |
| beta[12] | -0.753 | 0.761 | -2.177 | 0.669 | 0.009 | 0.007 | 6856.0 | 5939.0 | 1.0 |
| beta[13] | 0.019 | 0.725 | -1.346 | 1.364 | 0.009 | 0.008 | 6710.0 | 6176.0 | 1.0 |
| beta[14] | -0.420 | 0.725 | -1.832 | 0.900 | 0.009 | 0.007 | 6578.0 | 5359.0 | 1.0 |
| beta[15] | 0.633 | 0.715 | -0.692 | 1.982 | 0.008 | 0.007 | 7306.0 | 6027.0 | 1.0 |
| beta[16] | 0.936 | 0.729 | -0.417 | 2.296 | 0.008 | 0.006 | 7465.0 | 6252.0 | 1.0 |
| beta[17] | -2.396 | 0.772 | -3.891 | -1.003 | 0.009 | 0.006 | 7241.0 | 6058.0 | 1.0 |
| beta[18] | 1.219 | 0.679 | 0.030 | 2.568 | 0.008 | 0.006 | 6848.0 | 6025.0 | 1.0 |
| beta[19] | 0.998 | 0.561 | -0.077 | 2.035 | 0.007 | 0.005 | 6375.0 | 5778.0 | 1.0 |
axes = az.plot_trace(
data=hsgp_numpyro_idata,
var_names=["kernel_amplitude", "kernel_length_scale", "noise", "beta"],
compact=True,
kind="rank_bars",
backend_kwargs={"figsize": (12, 9), "layout": "constrained"},
)
plt.gcf().suptitle("HSGP NumPyro - Trace", fontsize=18, fontweight="bold");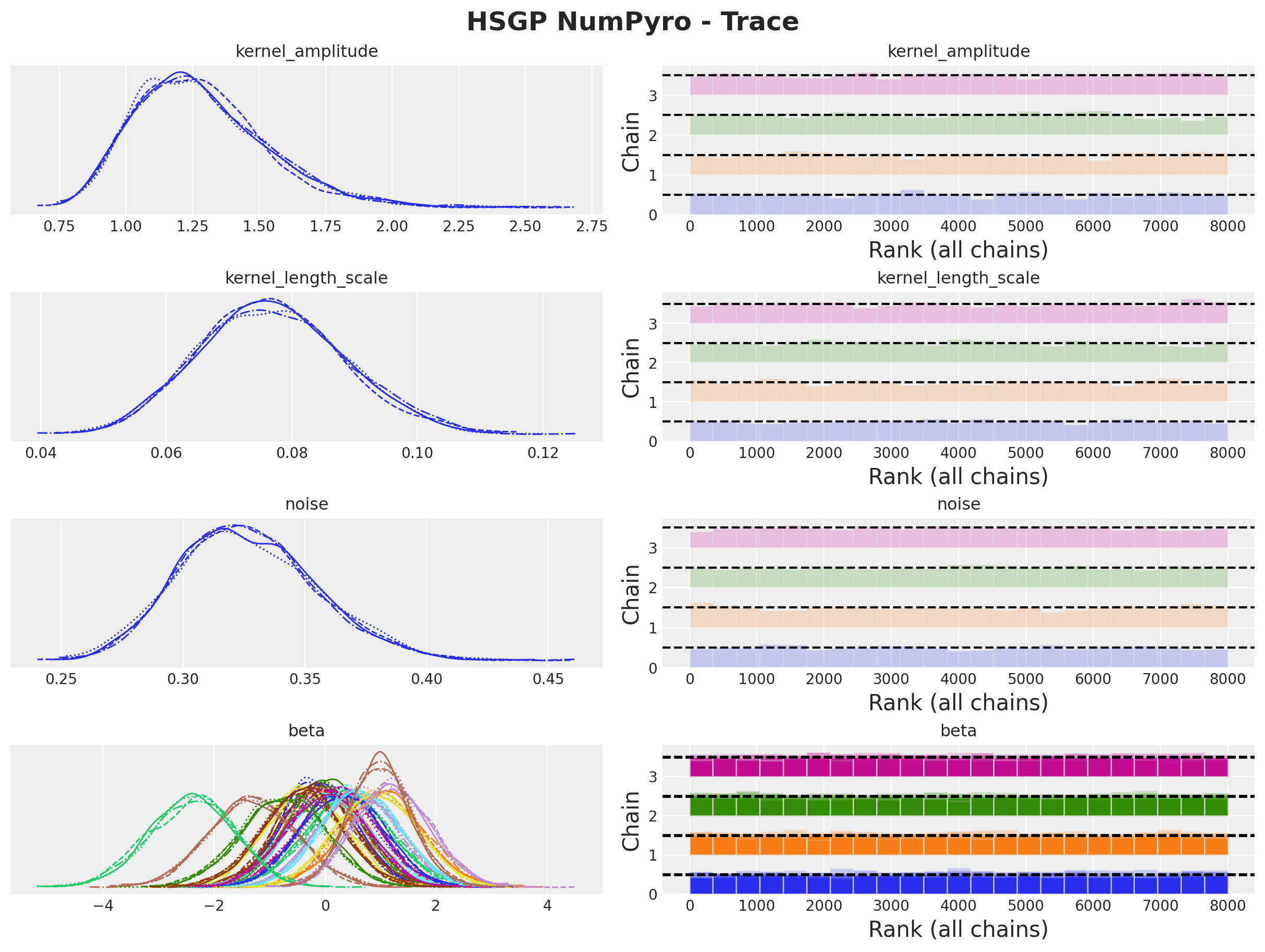
We can compare the posterior distributions of the parameters of the Hilbert space approximation with the ones of the Gaussian process model:
axes = az.plot_forest(
data=[gp_numpyro_idata, hsgp_numpyro_idata],
model_names=["GP", "HSGP"],
var_names=["kernel_amplitude", "kernel_length_scale", "noise"],
combined=True,
hdi_prob=0.94,
figsize=(10, 6),
)
axes[0].figure.suptitle("NumPyro Models", fontsize=18, fontweight="bold", x=0.32);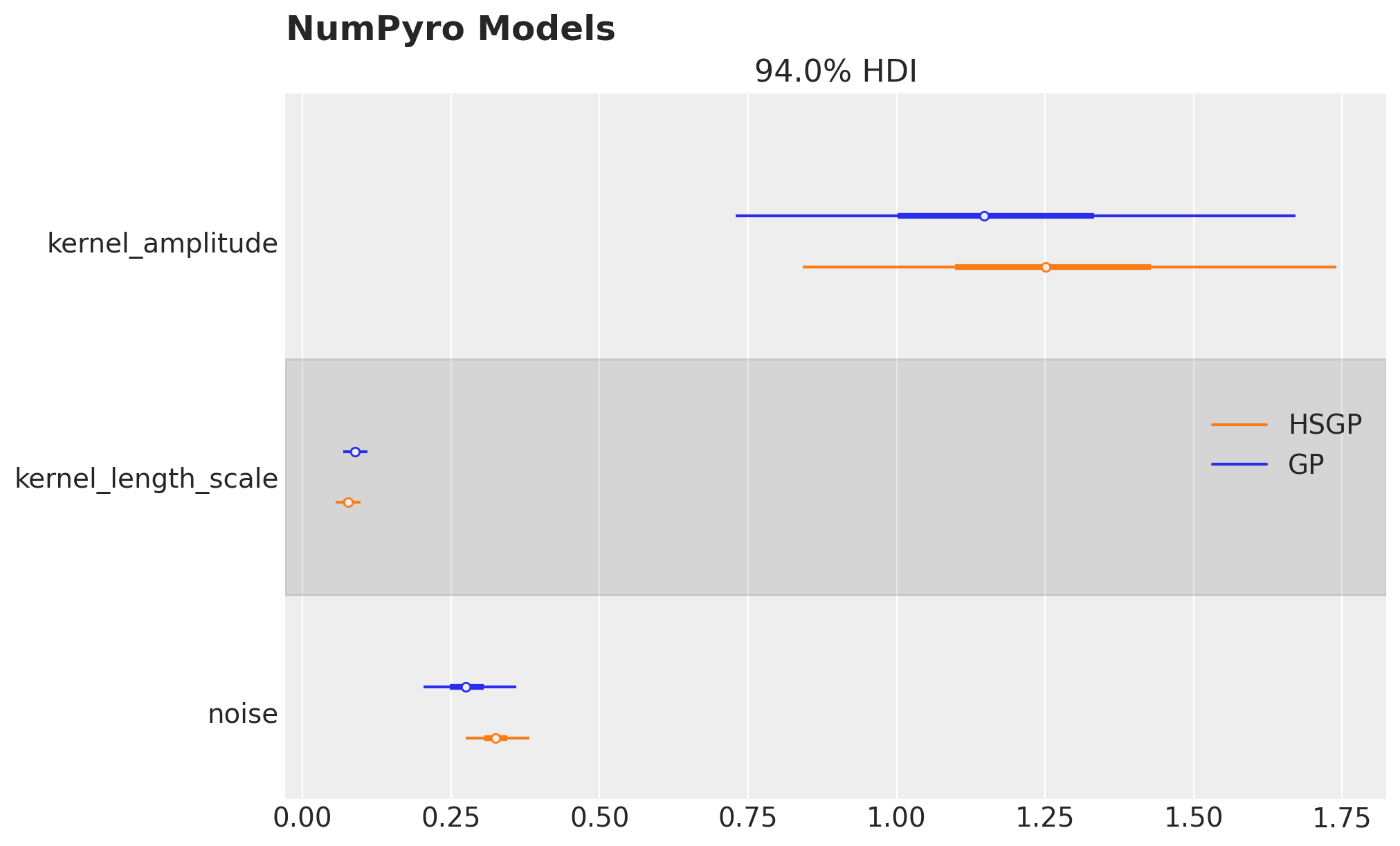
They look very similar!
Out of Sample Prediction
Finally, we can generate samples from the posterior distribution over functions on the test set. Note that we need to ensure these values lie inside the approximation domain \([-L, L]\).
hpgp_mcmc_samples_no_f = {
k: v for (k, v) in hsgp_mcmc.get_samples().items() if k != "f"
}
rng_key, rng_subkey = random.split(rng_key)
hsgp_numpyro_idata.extend(
az.from_numpyro(
posterior_predictive=Predictive(hsgp_model, hpgp_mcmc_samples_no_f)(
rng_subkey, x_test, l_max, m
)
)
)fig, ax = plt.subplots()
az.plot_hdi(
x_test,
hsgp_numpyro_idata.posterior_predictive["likelihood"],
hdi_prob=0.94,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
hsgp_numpyro_idata.posterior_predictive["likelihood"],
hdi_prob=0.5,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$50\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
hsgp_numpyro_idata.posterior_predictive["f"],
hdi_prob=0.94,
color="C3",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$f \\: 94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
hsgp_numpyro_idata.posterior_predictive["f"],
hdi_prob=0.5,
color="C3",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$f \\: 50\\%$ HDI (test)"},
ax=ax,
)
ax.plot(
x_test,
hsgp_numpyro_idata.posterior_predictive["f"].mean(dim=("chain", "draw")),
color="C3",
linewidth=3,
label="posterior predictive mean (test)",
)
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
ax.scatter(x_test, y_test_obs, c="C1", label="observed (test)")
ax.plot(x_train, y_train, color="black", linewidth=3, alpha=0.7, label="mean (latent)")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=4)
ax.set(xlabel="x", ylabel="y")
ax.set_title(
"HSGP NumPyro Model - Posterior Predictive", fontsize=18, fontweight="bold"
);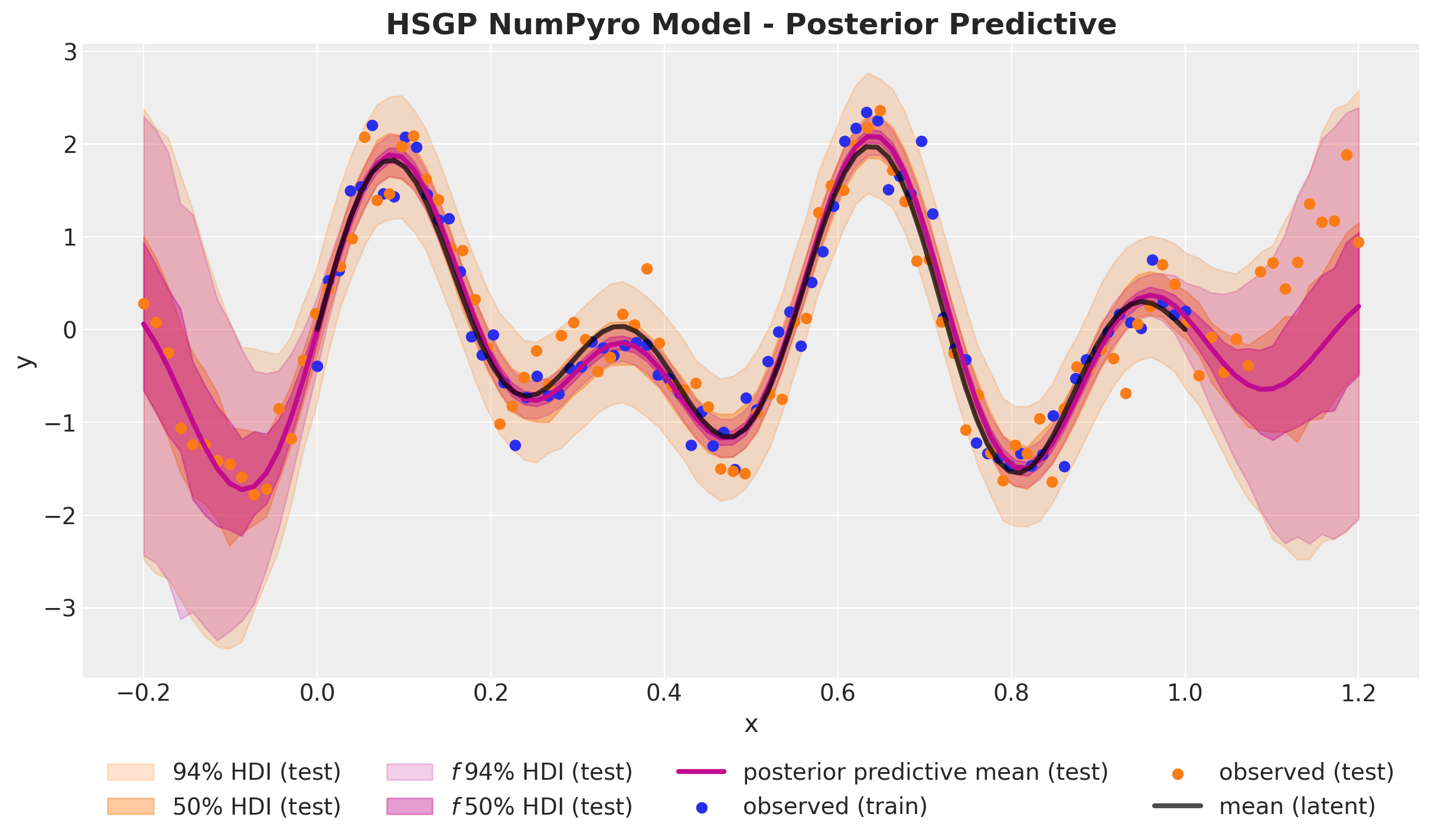
We have successfully implemented the Hilbert space Gaussian process approximation in NumPyro and applied it to the same synthetic data as in the first part. The results look very good 🚀!
Next, let’s see how to leverage PyMC’s API to do the same!
PyMC Hilbert Space Gaussian Process Model
NumPyro + JAX is a great framework for developing and creating custom components as the Hilbert space Gaussian process approximation as above. In many applications, one does not want to write everything from scratch but rather use a high-level API, especially when the model has many GP components with different kernels (and therefore different spectral densities). PyMC offers a convenient API for using the HSGP components is a very intuitive and efficient way. Moreover, we can still use NumPyro’s backend for the sampling, so it is a win-win situation!
There are two ways to use the HSGP components in PyMC depending on the requirements of the application. To illustrate them both we use the same synthetic data as before.
HSGP.prior
This first implementation follows the PyMC’s GP module API and therefore changing from a vanilla Gaussian process to the corresponding Hilbert space approximation requires changing no more than \(3\) lines of code:
with pm.Model() as hsgp_pymc_model:
x_data = pm.MutableData("x_data", value=x_train)
y_data = pm.MutableData("y_data", y_train_obs)
kernel_amplitude = pm.InverseGamma(
"kernel_amplitude",
alpha=inverse_gamma_params_2["alpha"],
beta=inverse_gamma_params_2["beta"],
)
kernel_length_scale = pm.InverseGamma(
"kernel_length_scale",
alpha=inverse_gamma_params_1["alpha"],
beta=inverse_gamma_params_1["beta"],
)
noise = pm.InverseGamma(
"noise",
alpha=inverse_gamma_params_2["alpha"],
beta=inverse_gamma_params_2["beta"],
)
mean = pm.gp.mean.Zero()
cov = kernel_amplitude**2 * pm.gp.cov.ExpQuad(input_dim=1, ls=kernel_length_scale)
gp = pm.gp.HSGP(m=[20], L=[1.3], mean_func=mean, cov_func=cov)
f = gp.prior("f", X=x_data[:, None])
pm.Normal("likelihood", mu=f, sigma=noise, observed=y_data)
pm.model_to_graphviz(model=hsgp_pymc_model)
Let’s inspect the HSGP class
print(pm.gp.HSGP.__doc__) Hilbert Space Gaussian process approximation.
The `gp.HSGP` class is an implementation of the Hilbert Space Gaussian process. It is a
reduced rank GP approximation that uses a fixed set of basis vectors whose coefficients are
random functions of a stationary covariance function's power spectral density. Its usage
is largely similar to `gp.Latent`. Like `gp.Latent`, it does not assume a Gaussian noise model
and can be used with any likelihood, or as a component anywhere within a model. Also like
`gp.Latent`, it has `prior` and `conditional` methods. It supports any sum of covariance
functions that implement a `power_spectral_density` method. (Note, this excludes the
`Periodic` covariance function, which uses a different set of basis functions for a
low rank approximation, as described in `HSGPPeriodic`.).
For information on choosing appropriate `m`, `L`, and `c`, refer to Ruitort-Mayol et al. or to
the PyMC examples that use HSGP.
To work with the HSGP in its "linearized" form, as a matrix of basis vectors and a vector of
coefficients, see the method `prior_linearized`.
Parameters
----------
m: list
The number of basis vectors to use for each active dimension (covariance parameter
`active_dim`).
L: list
The boundary of the space for each `active_dim`. It is called the boundary condition.
Choose L such that the domain `[-L, L]` contains all points in the column of X given by the
`active_dim`.
c: float
The proportion extension factor. Used to construct L from X. Defined as `S = max|X|` such
that `X` is in `[-S, S]`. `L` is calculated as `c * S`. One of `c` or `L` must be
provided. Further information can be found in Ruitort-Mayol et al.
drop_first: bool
Default `False`. Sometimes the first basis vector is quite "flat" and very similar to
the intercept term. When there is an intercept in the model, ignoring the first basis
vector may improve sampling.
parameterization: str
Whether to use the `centered` or `noncentered` parameterization when multiplying the
basis by the coefficients.
cov_func: Covariance function, must be an instance of `Stationary` and implement a
`power_spectral_density` method.
mean_func: None, instance of Mean
The mean function. Defaults to zero.
Examples
--------
.. code:: python
# A three dimensional column vector of inputs.
X = np.random.rand(100, 3)
with pm.Model() as model:
# Specify the covariance function.
# Three input dimensions, but we only want to use the last two.
cov_func = pm.gp.cov.ExpQuad(3, ls=0.1, active_dims=[1, 2])
# Specify the HSGP.
# Use 25 basis vectors across each active dimension for a total of 25 * 25 = 625.
# The value `c = 4` means the boundary of the approximation
# lies at four times the half width of the data.
# In this example the data lie between zero and one,
# so the boundaries occur at -1.5 and 2.5. The data, both for
# training and prediction should reside well within that boundary..
gp = pm.gp.HSGP(m=[25, 25], c=4.0, cov_func=cov_func)
# Place a GP prior over the function f.
f = gp.prior("f", X=X)
...
# After fitting or sampling, specify the distribution
# at new points with .conditional
Xnew = np.linspace(-1, 2, 50)[:, None]
with model:
fcond = gp.conditional("fcond", Xnew=Xnew)
References
----------
- Ruitort-Mayol, G., and Anderson, M., and Solin, A., and Vehtari, A. (2022). Practical
Hilbert Space Approximate Bayesian Gaussian Processes for Probabilistic Programming
- Solin, A., Sarkka, S. (2019) Hilbert Space Methods for Reduced-Rank Gaussian Process
Regression.
Observe that the parametrization argument allow us to select between centered and non-centered parametrizations automatically 🤩!
Sampling from this model is much faster that the GP model from the fist part!
rng_key, rng_subkey = random.split(rng_key)
with hsgp_pymc_model:
hsgp_pymc_idata = pm.sample(
target_accept=0.9,
draws=inference_params.num_samples,
chains=inference_params.num_chains,
nuts_sampler="numpyro",
random_seed=rng_subkey[0].item(),
)axes = az.plot_trace(
data=hsgp_pymc_idata,
var_names=["kernel_amplitude", "kernel_length_scale", "noise"],
compact=True,
kind="rank_bars",
backend_kwargs={"figsize": (12, 7), "layout": "constrained"},
)
plt.gcf().suptitle("HSGP PyMC - Trace", fontsize=18, fontweight="bold");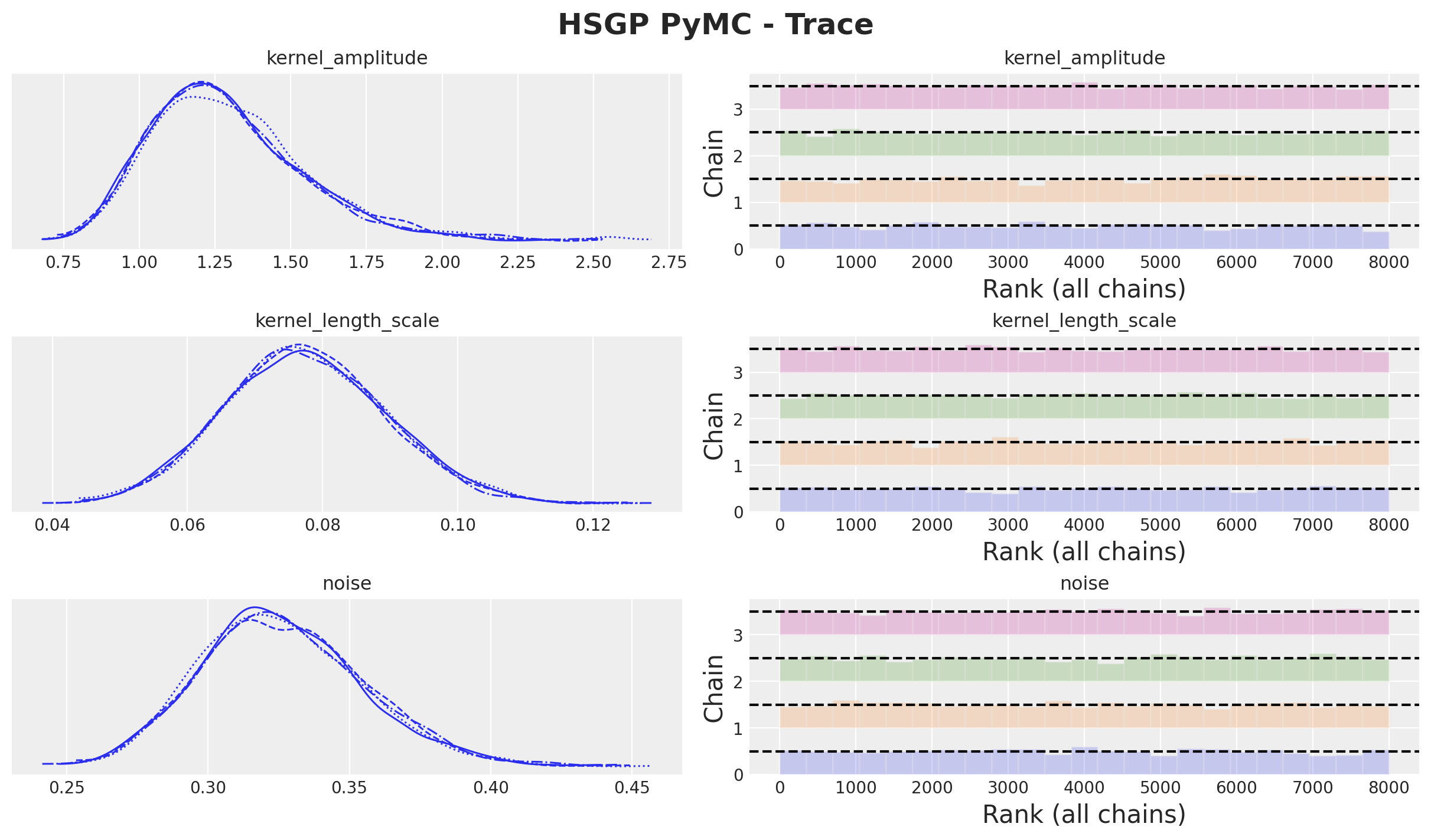
We can generate out of sample predictions using the conditional method as before.
with hsgp_pymc_model:
x_star_data = pm.MutableData("x_star_data", x_test)
f_star = gp.conditional("f_star", x_star_data[:, None])
pm.set_data({"x_data": x_test, "y_data": np.ones_like(x_test)})
hsgp_pymc_idata.extend(
pm.sample_posterior_predictive(
trace=hsgp_pymc_idata,
var_names=["f_star", "likelihood"],
random_seed=rng_subkey[1].item(),
)
)Let’s see the final fit:
fig, ax = plt.subplots()
az.plot_hdi(
x_test,
hsgp_pymc_idata.posterior_predictive["likelihood"],
hdi_prob=0.94,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$\\: 94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
hsgp_pymc_idata.posterior_predictive["likelihood"],
hdi_prob=0.5,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$\\: 50\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
hsgp_pymc_idata.posterior_predictive["f_star"],
hdi_prob=0.94,
color="C3",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$f \\: 94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
hsgp_pymc_idata.posterior_predictive["f_star"],
hdi_prob=0.5,
color="C3",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$f \\: 50\\%$ HDI (test)"},
ax=ax,
)
ax.plot(
x_test,
hsgp_pymc_idata.posterior_predictive["f_star"].mean(dim=("chain", "draw")),
color="C3",
linewidth=3,
label="posterior predictive mean (test)",
)
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
ax.scatter(x_test, y_test_obs, c="C1", label="observed (test)")
ax.plot(x_train, y_train, color="black", linewidth=3, alpha=0.7, label="mean (latent)")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=4)
ax.set(xlabel="x", ylabel="y")
ax.set_title("HSGP PyMC Model - Posterior Predictive", fontsize=18, fontweight="bold");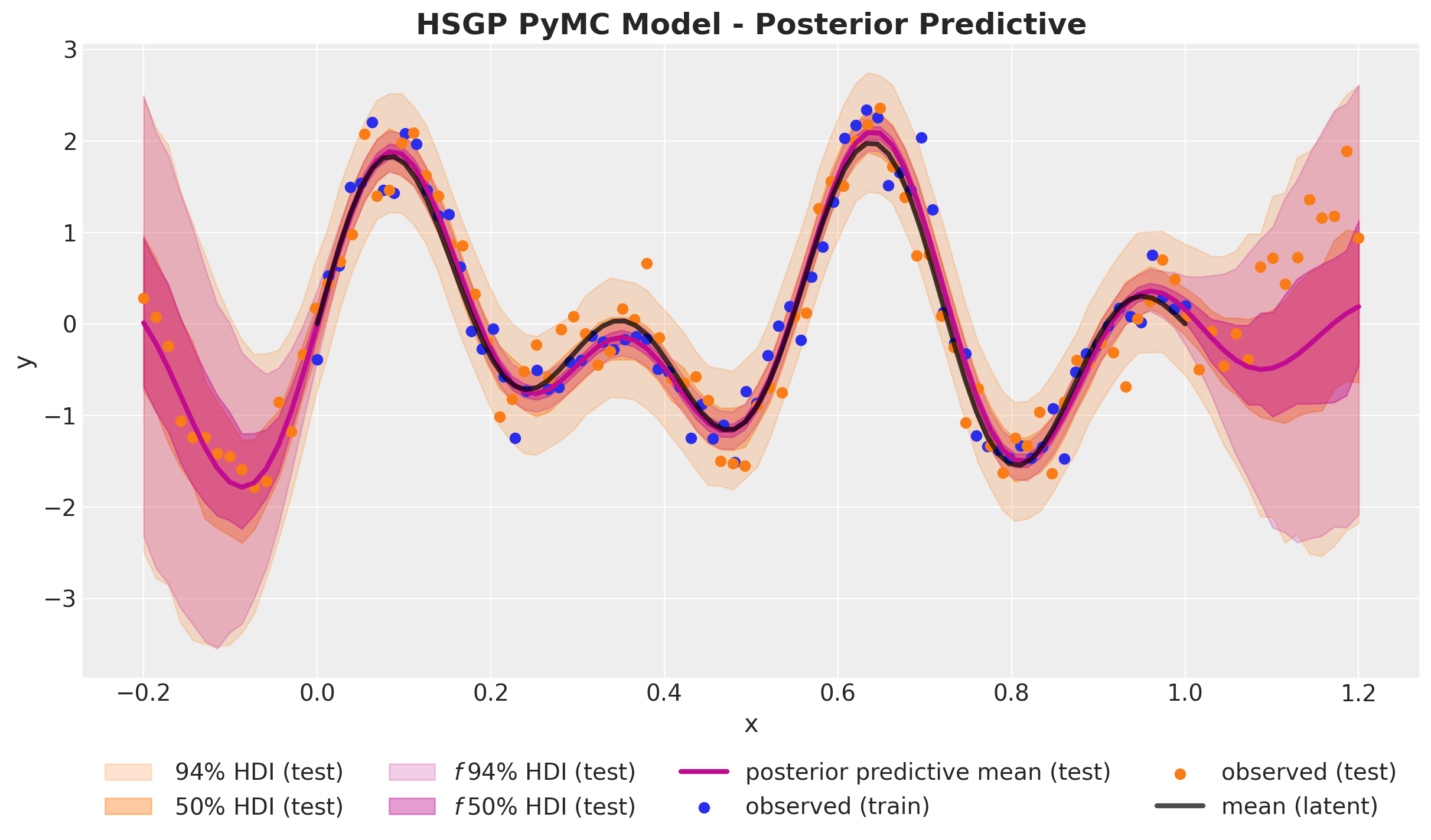
🙌 !
HSGP.prior_linearized
The alternative implementation is to extract the spectral density expressions and the Laplacian eigenfunctions explicitly so that we can use them as a component in the model. This provides a lot of flexibility! Note that in the implementation below we are using the non-centered parametrization as well.
with pm.Model() as hsgp_linearized_pymc_model:
x_train_mean = np.array(x_train).mean(axis=0)
x_data = pm.MutableData("x_data", value=x_train)
x_data_centered = x_data - x_train_mean
y_data = pm.MutableData("y_data", value=y_train_obs)
kernel_amplitude = pm.InverseGamma(
"kernel_amplitude",
alpha=inverse_gamma_params_2["alpha"],
beta=inverse_gamma_params_2["beta"],
)
kernel_length_scale = pm.InverseGamma(
"kernel_length_scale",
alpha=inverse_gamma_params_1["alpha"],
beta=inverse_gamma_params_1["beta"],
)
noise = pm.InverseGamma(
"noise",
alpha=inverse_gamma_params_2["alpha"],
beta=inverse_gamma_params_2["beta"],
)
mean = pm.gp.mean.Zero()
cov = kernel_amplitude**2 * pm.gp.cov.ExpQuad(input_dim=1, ls=kernel_length_scale)
gp = pm.gp.HSGP(m=[20], L=[1.3], mean_func=mean, cov_func=cov)
phi, sqrt_psd = gp.prior_linearized(Xs=x_data_centered[:, None])
beta = pm.Normal("beta", mu=0, sigma=1, size=gp._m_star)
f = pm.Deterministic("f", phi @ (beta * sqrt_psd))
pm.Normal("likelihood", mu=f, sigma=noise, observed=y_data)
pm.model_to_graphviz(model=hsgp_linearized_pymc_model)
Fitting the model is again very fast!
rng_key, rng_subkey = random.split(rng_key)
with hsgp_linearized_pymc_model:
hsgp_linearized_pymc_idata = pm.sample(
target_accept=0.92,
draws=inference_params.num_samples,
chains=inference_params.num_chains,
nuts_sampler="numpyro",
random_seed=rng_subkey[0].item(),
)axes = az.plot_trace(
data=hsgp_linearized_pymc_idata,
var_names=["kernel_amplitude", "kernel_length_scale", "noise", "beta"],
compact=True,
kind="rank_bars",
backend_kwargs={"figsize": (12, 9), "layout": "constrained"},
)
plt.gcf().suptitle("HSGP (Linearized) PyMC - Trace", fontsize=18, fontweight="bold");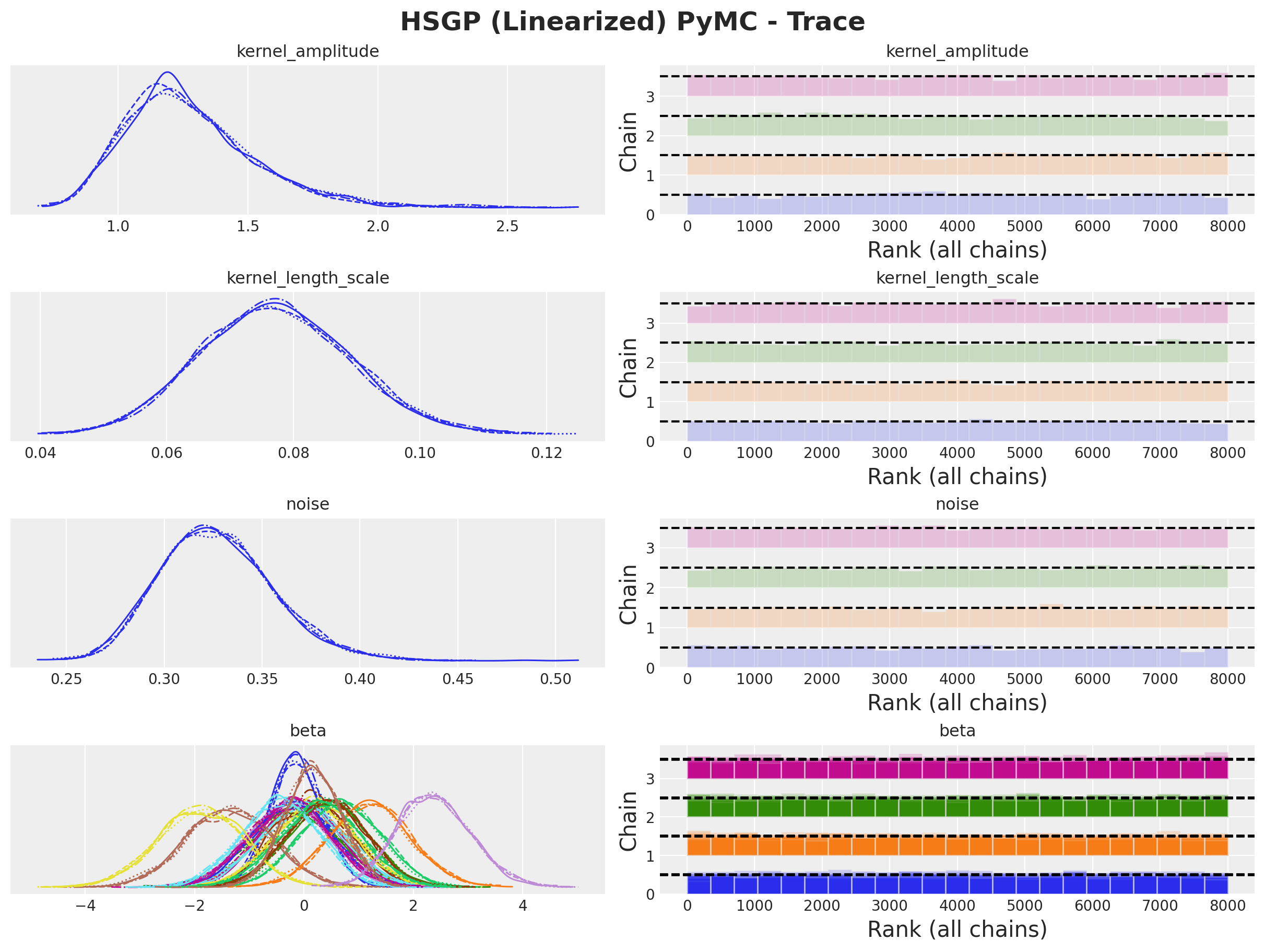
Using this approach we can generate out-of-sample predictions as one would do with a simple linear model using pm.set_data, see “Out-Of-Sample Predictions”.
with hsgp_pymc_model:
pm.set_data({"x_data": x_test, "y_data": np.ones_like(x_test)})
hsgp_linearized_pymc_idata.extend(
pm.sample_posterior_predictive(
trace=hsgp_pymc_idata,
var_names=[
"f",
"likelihood",
],
random_seed=rng_subkey[1].item(),
)
)fig, ax = plt.subplots()
az.plot_hdi(
x_test,
hsgp_linearized_pymc_idata.posterior_predictive["likelihood"],
hdi_prob=0.94,
color="C1",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$f \\: 94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
hsgp_linearized_pymc_idata.posterior_predictive["likelihood"],
hdi_prob=0.5,
color="C3",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$f \\: 50\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
hsgp_linearized_pymc_idata.posterior_predictive["f"],
hdi_prob=0.94,
color="C3",
smooth=False,
fill_kwargs={"alpha": 0.2, "label": "$f \\: 94\\%$ HDI (test)"},
ax=ax,
)
az.plot_hdi(
x_test,
hsgp_linearized_pymc_idata.posterior_predictive["f"],
hdi_prob=0.5,
color="C3",
smooth=False,
fill_kwargs={"alpha": 0.4, "label": "$f \\: 50\\%$ HDI (test)"},
ax=ax,
)
ax.plot(
x_test,
hsgp_linearized_pymc_idata.posterior_predictive["f"].mean(dim=("chain", "draw")),
color="C3",
linewidth=3,
label="posterior predictive mean (test)",
)
ax.scatter(x_train, y_train_obs, c="C0", label="observed (train)")
ax.scatter(x_test, y_test_obs, c="C1", label="observed (test)")
ax.plot(x_train, y_train, color="black", linewidth=3, alpha=0.7, label="mean (latent)")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.1), ncol=4)
ax.set(xlabel="x", ylabel="y")
ax.set_title(
"HSGP (Linearized) PyMC Model - Posterior Predictive",
fontsize=18,
fontweight="bold",
);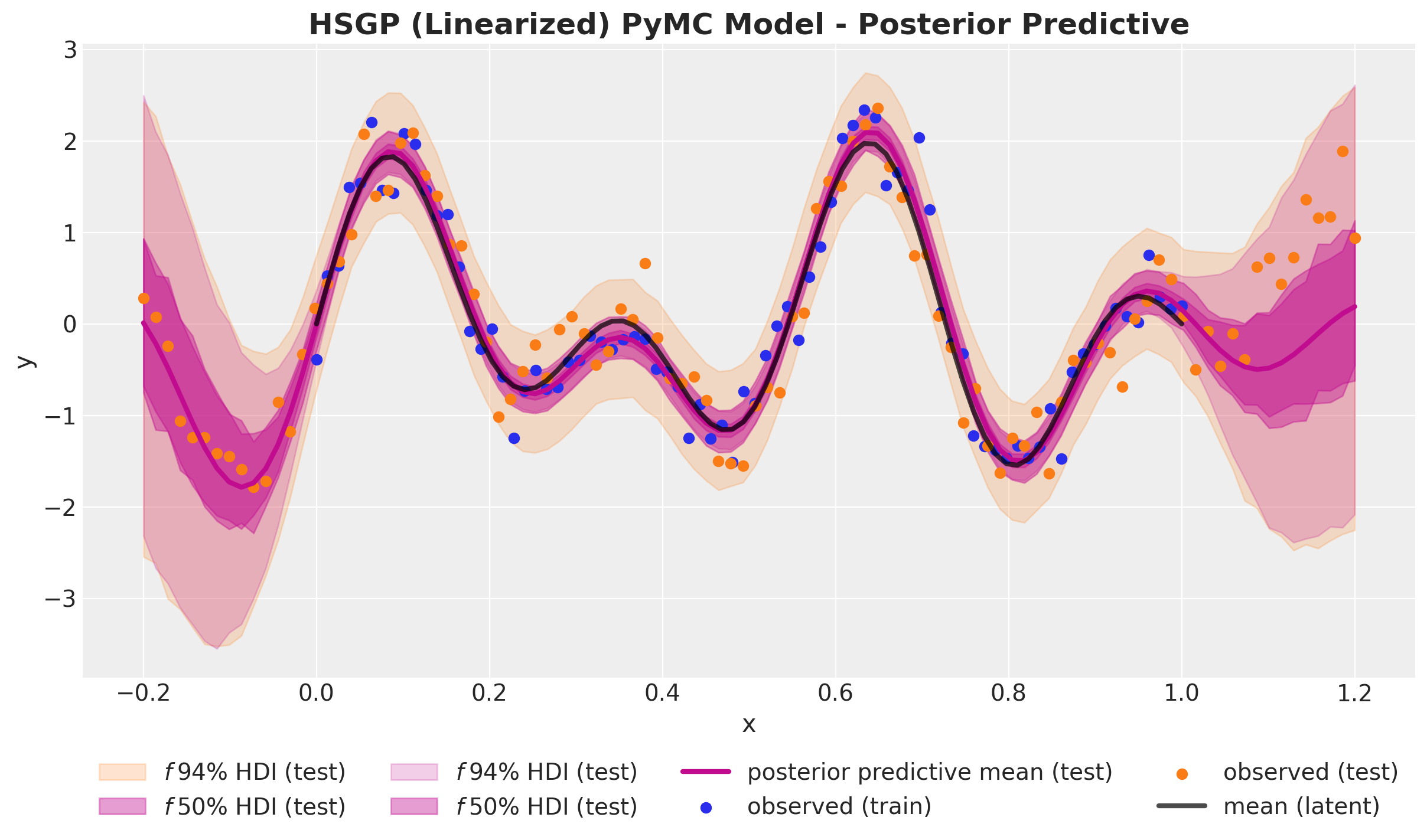
Finally, we can compare the results of the the three models: vanilla Gaussian process, Hilbert space Gaussian process approximation and the linearized Hilbert space Gaussian process approximation.
axes = az.plot_forest(
data=[gp_pymc_idata, hsgp_pymc_idata, hsgp_linearized_pymc_idata],
model_names=["GP", "HSGP", "HSGP (Linearized)"],
var_names=["kernel_amplitude", "kernel_length_scale", "noise"],
combined=True,
hdi_prob=0.94,
figsize=(10, 6),
)
axes[0].figure.suptitle("PyMC Models", fontsize=18, fontweight="bold", x=0.3);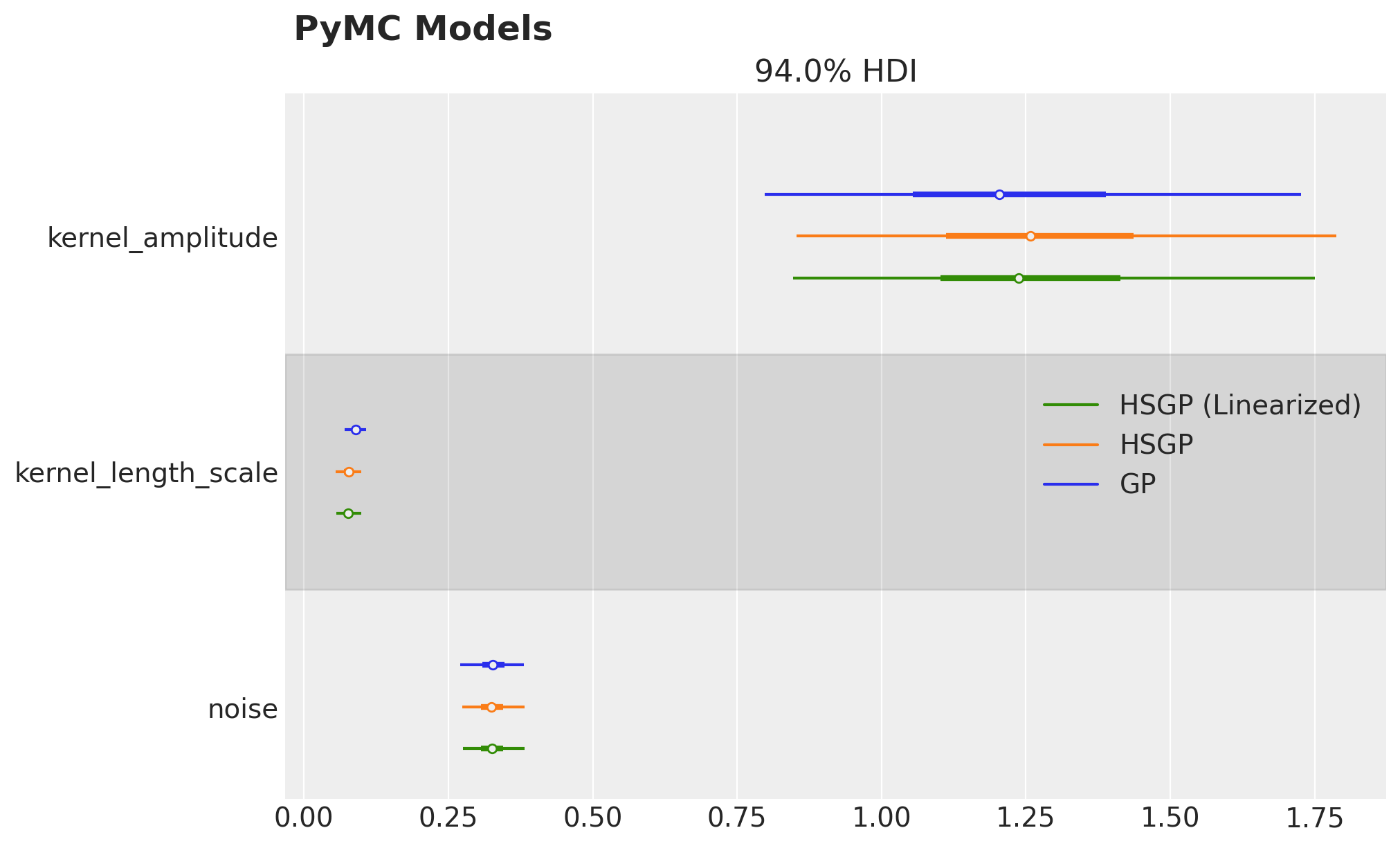
The results look very similar 🤗!
I hope this notebook gave you enough tools to understand the main ideas behind the Hilbert space approximation for Gaussian processes and some tips on how to implement this in NumPyro and PyMC. This opens a huge modeling space for applications at scale. Now is your turn to apply this to your own problems! 🚀