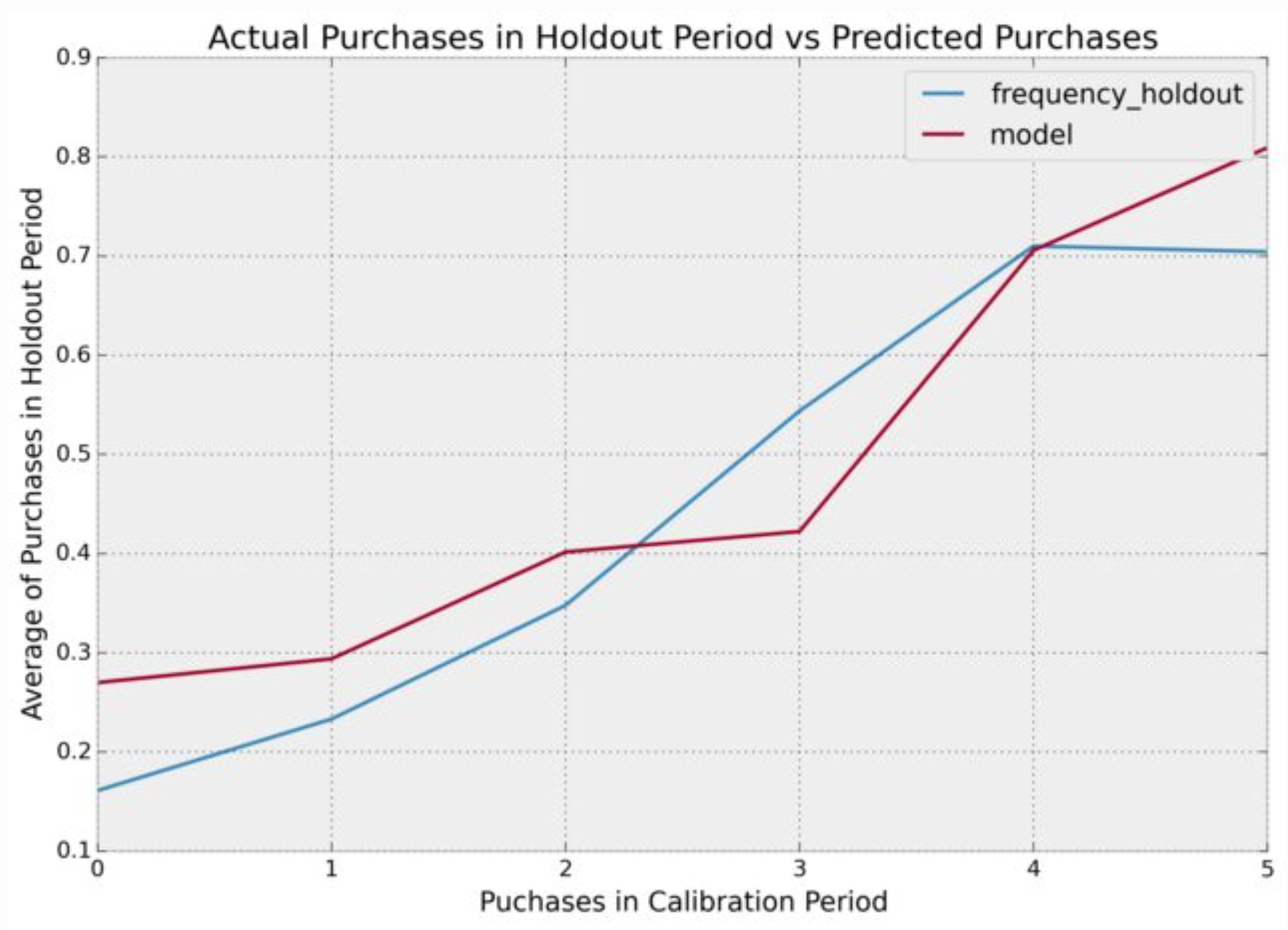
BG/NBD Model: Maximum Likelihood Estimation (lifetimes)
BG/NBD Model: Bayesian Estimation (pymc)
External Regressors
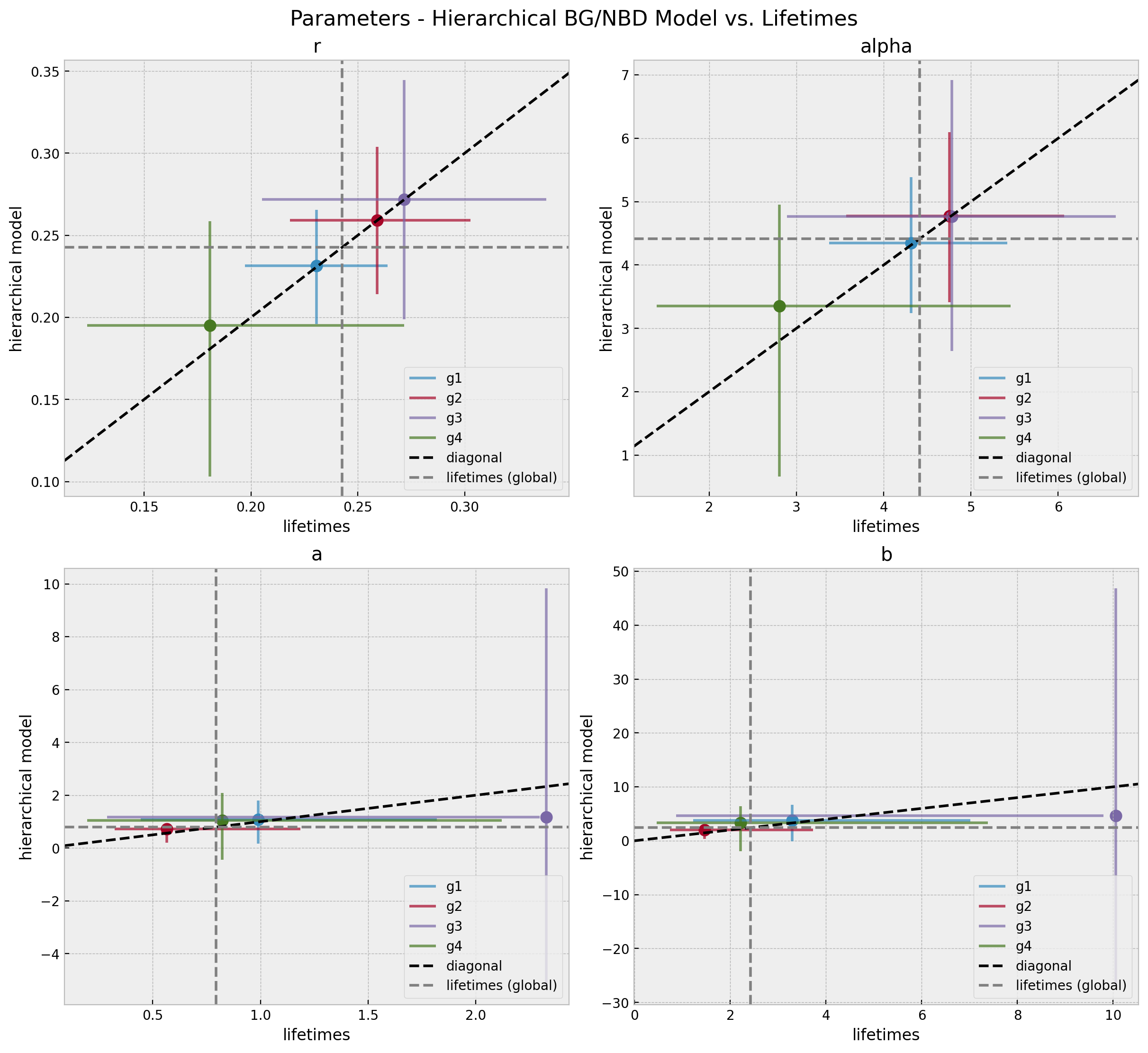
Hierarchical Model
References and Resources
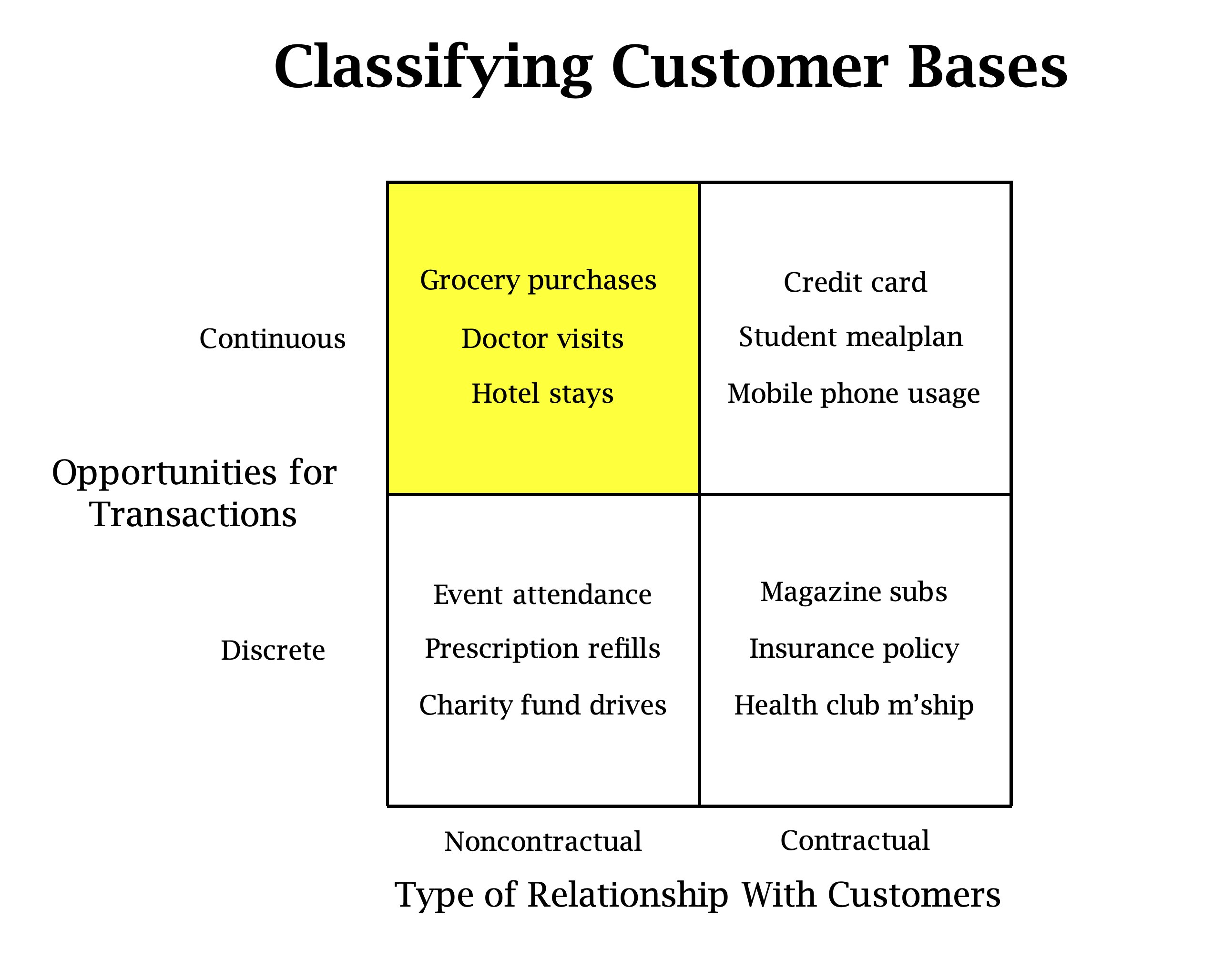
Classifying Customer Bases
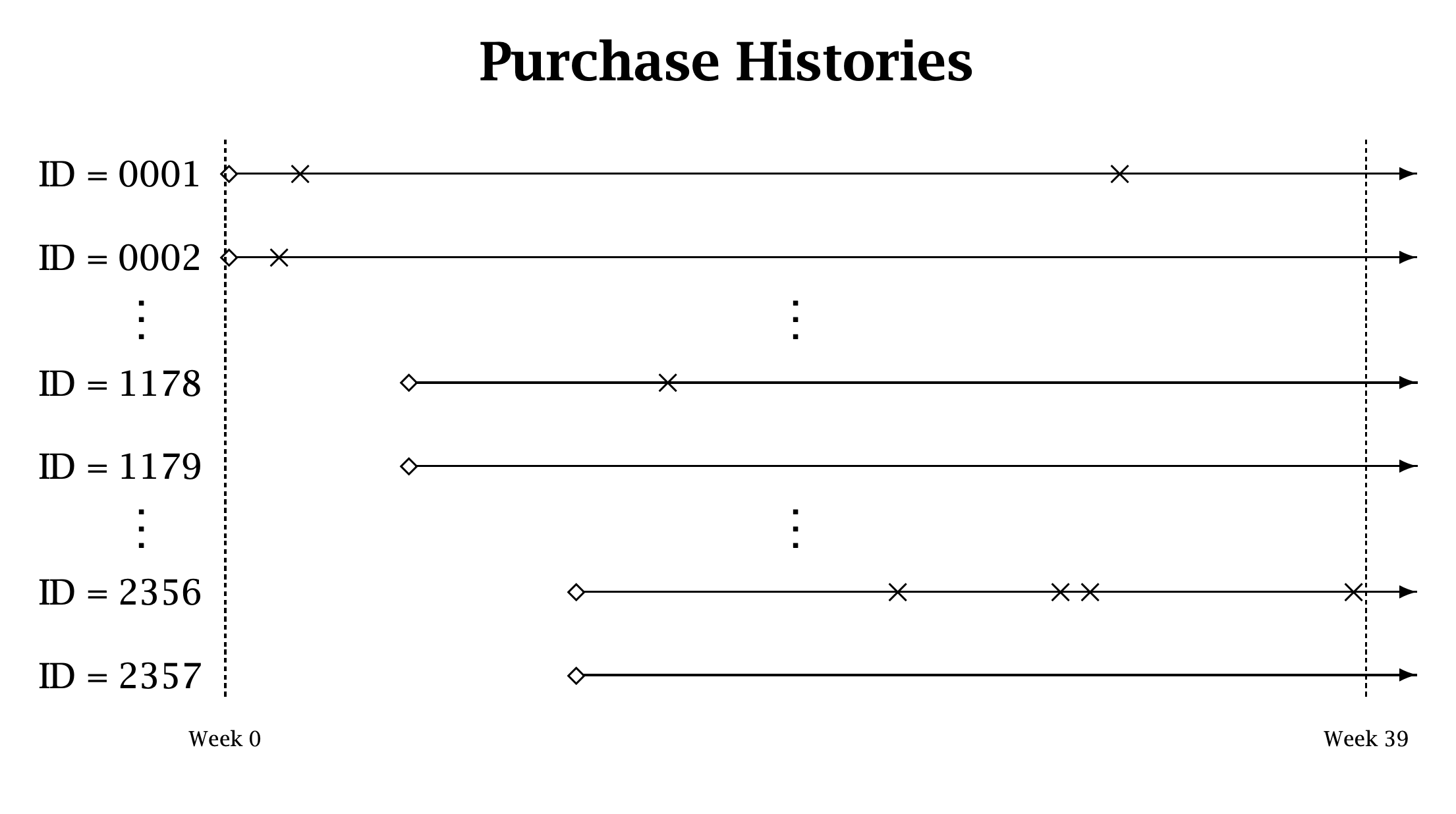
Purchase Histories
The Pareto/NBD Model
Models Workflow
%%{init: {"theme": "dark", "themeVariables": {"fontSize": "12px"}, "flowchart":{"htmlLabels":false}}}%%
flowchart LR
A["Transaction Data"] --> B("Transaction Model - BG/NBD")
A --> C("Monetary Model - GG")
B --> D["Probability of Alive"]
B --> E["Predicted Frequency"]
C --> F["Predicted Avg. Monetary Value"]
E --> G["Predicted CLV"]
F --> G
Transaction Model: Number of transactions per customer.
Monetary Model: Average monetary value of a transaction.
for i in steps: df["clv"] += ( (monetary_value * expected_number_of_transactions) / (1+ discount_rate) ** i )
The BG/NBD Transaction Model
Purchase Metrics
frequency: Number of repeat purchases the customer has made. More precisely, It’s the count of time periods the customer had a purchase in.
T: Age of the customer in whatever time units chosen. This is equal to the duration between a customer’s first purchase and the end of the period under study.
recency: Age of the customer when they made their most recent purchases. This is equal to the duration between a customer’s first purchase and their latest purchase.
BG/NBD Assumptions (Frequency)
While active, the time between transactions is distributed exponential with transaction rate, i.e.,
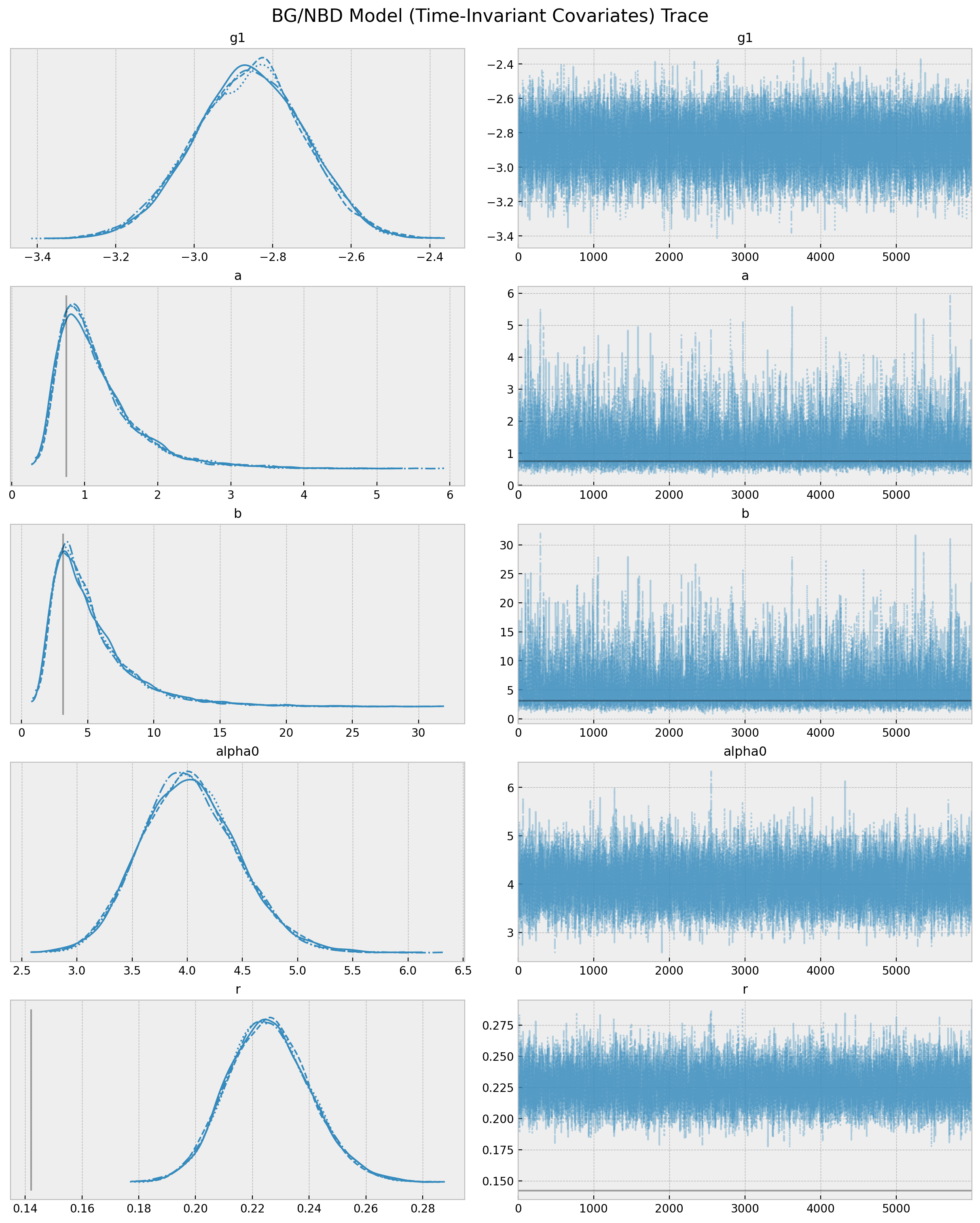
import pymc as pmimport pymc.sampling_jaxwith pm.Model() as model: a = pm.HalfNormal(name="a", sigma=10) b = pm.HalfNormal(name="b", sigma=10) alpha = pm.HalfNormal(name="alpha", sigma=10) r = pm.HalfNormal(name="r", sigma=10)def logp(x, t_x, T, x_zero): ... likelihood = pm.Potential( name="likelihood", var=logp(x=x, t_x=t_x, T=T, x_zero=x_zero), )
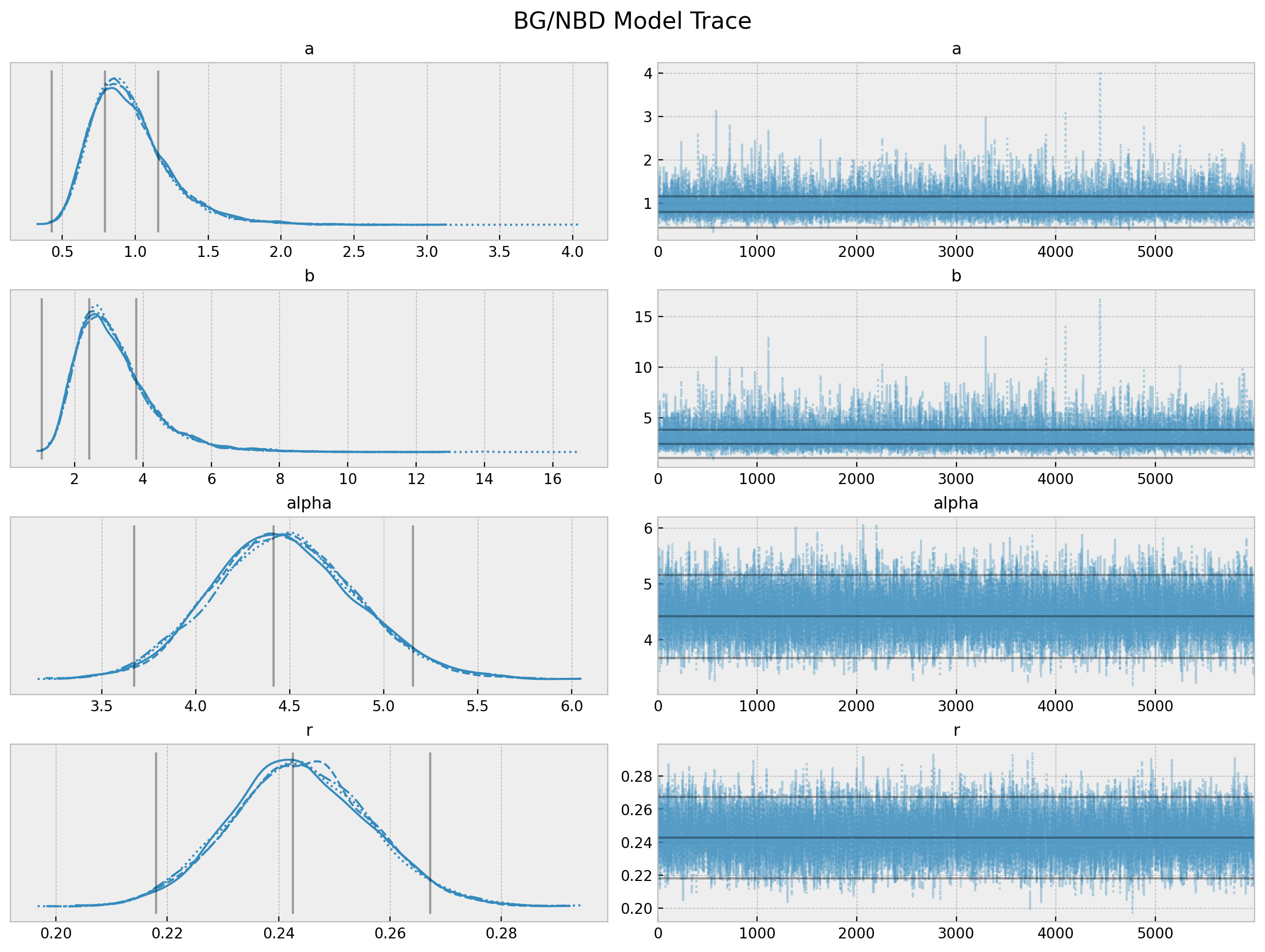
Model Sampling
with model: trace = pm.sampling_jax.sample_numpyro_nuts( tune=3000, draws=6000, chains=4,target_accept=0.95)
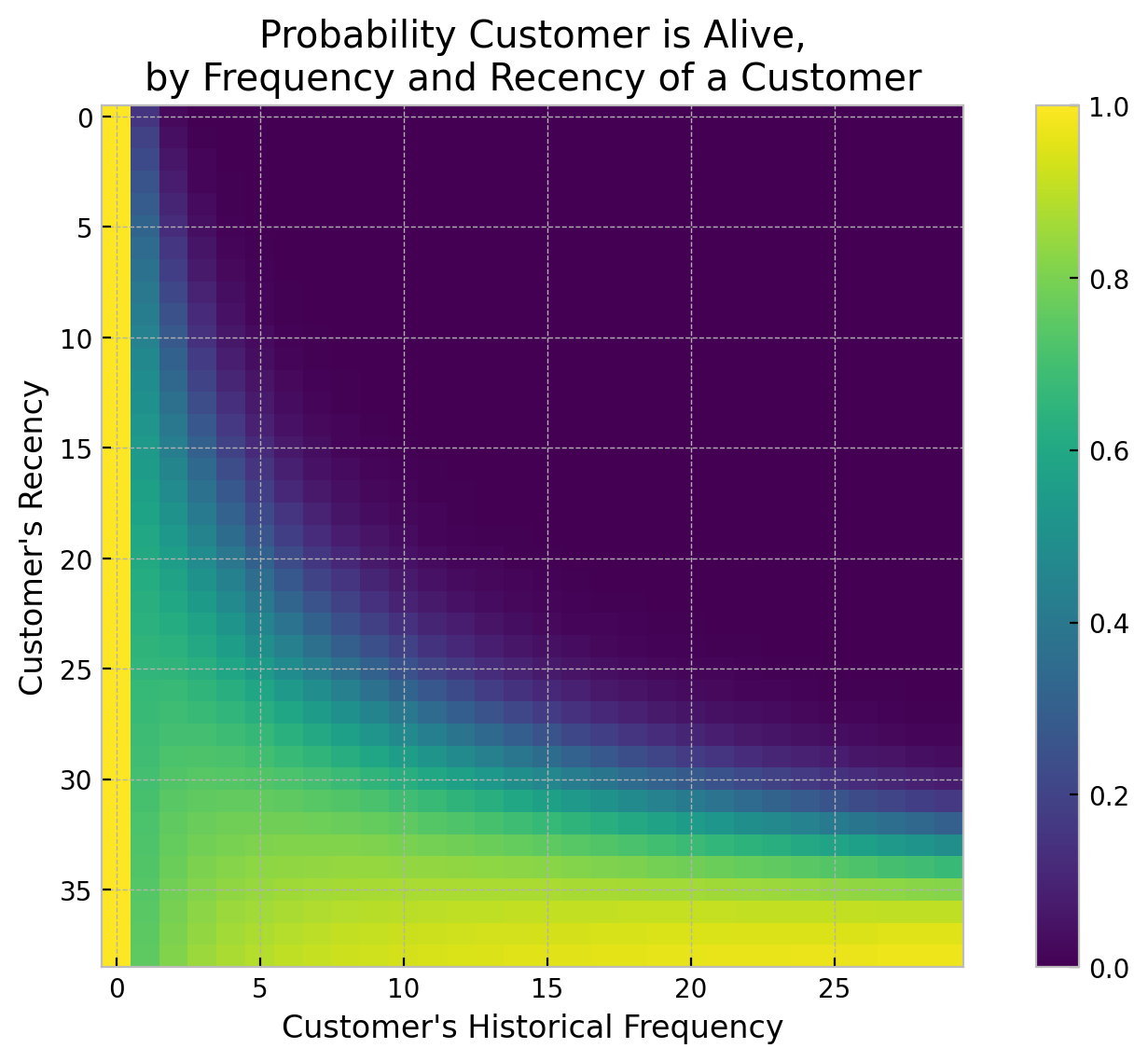
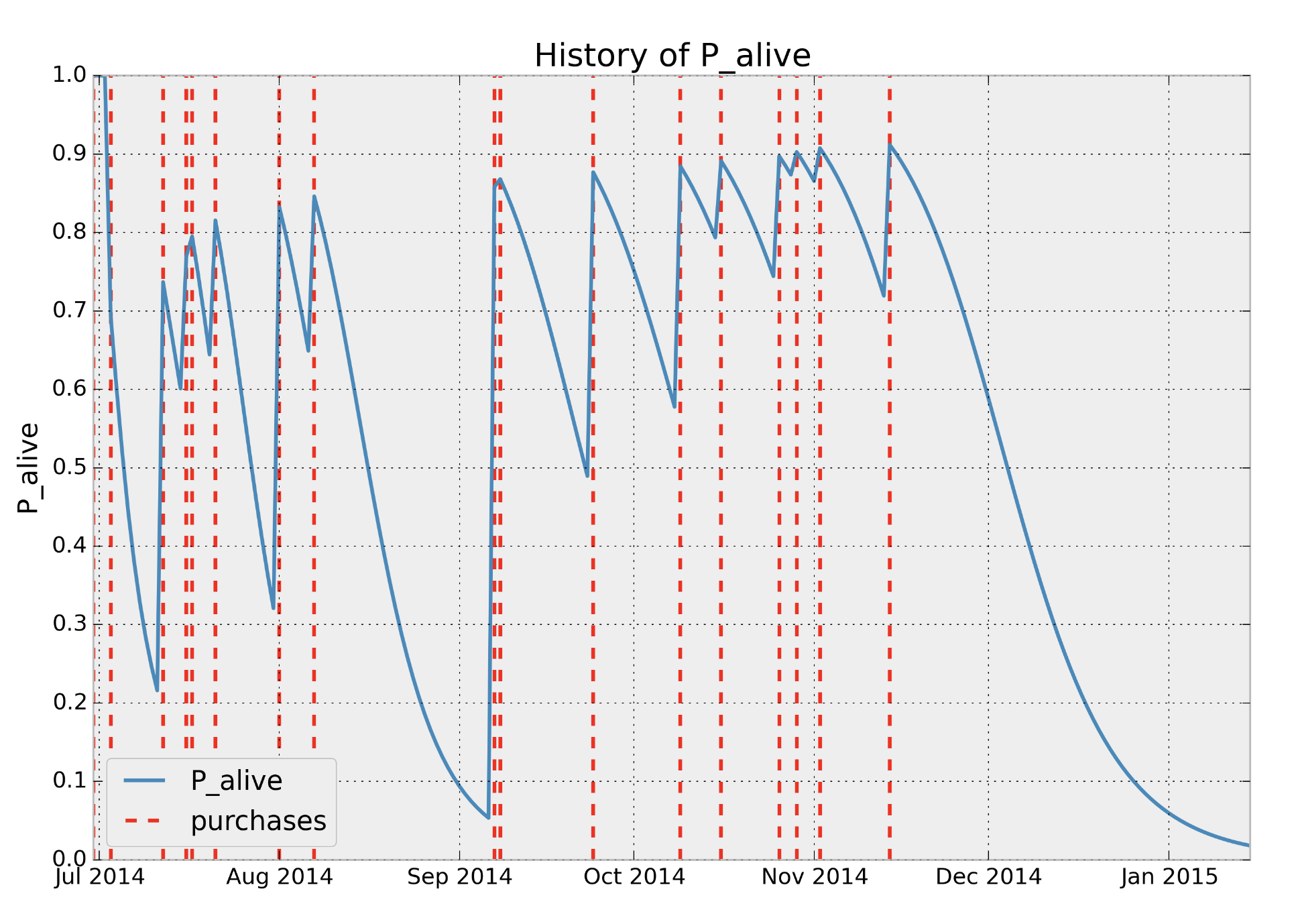
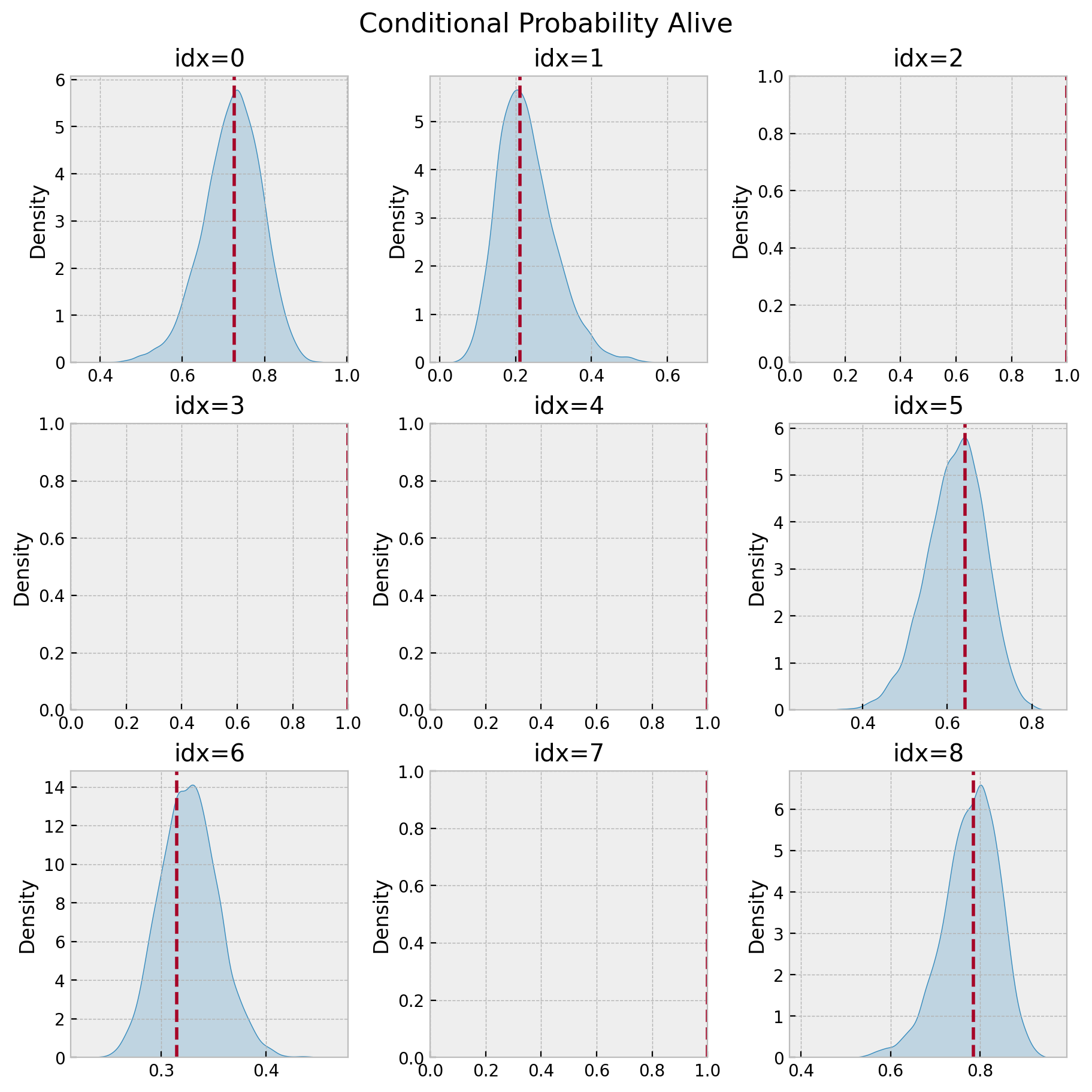
Probability of Active
How? Simply use the posterior samples (xarray) and broadcast the numpy expressions.
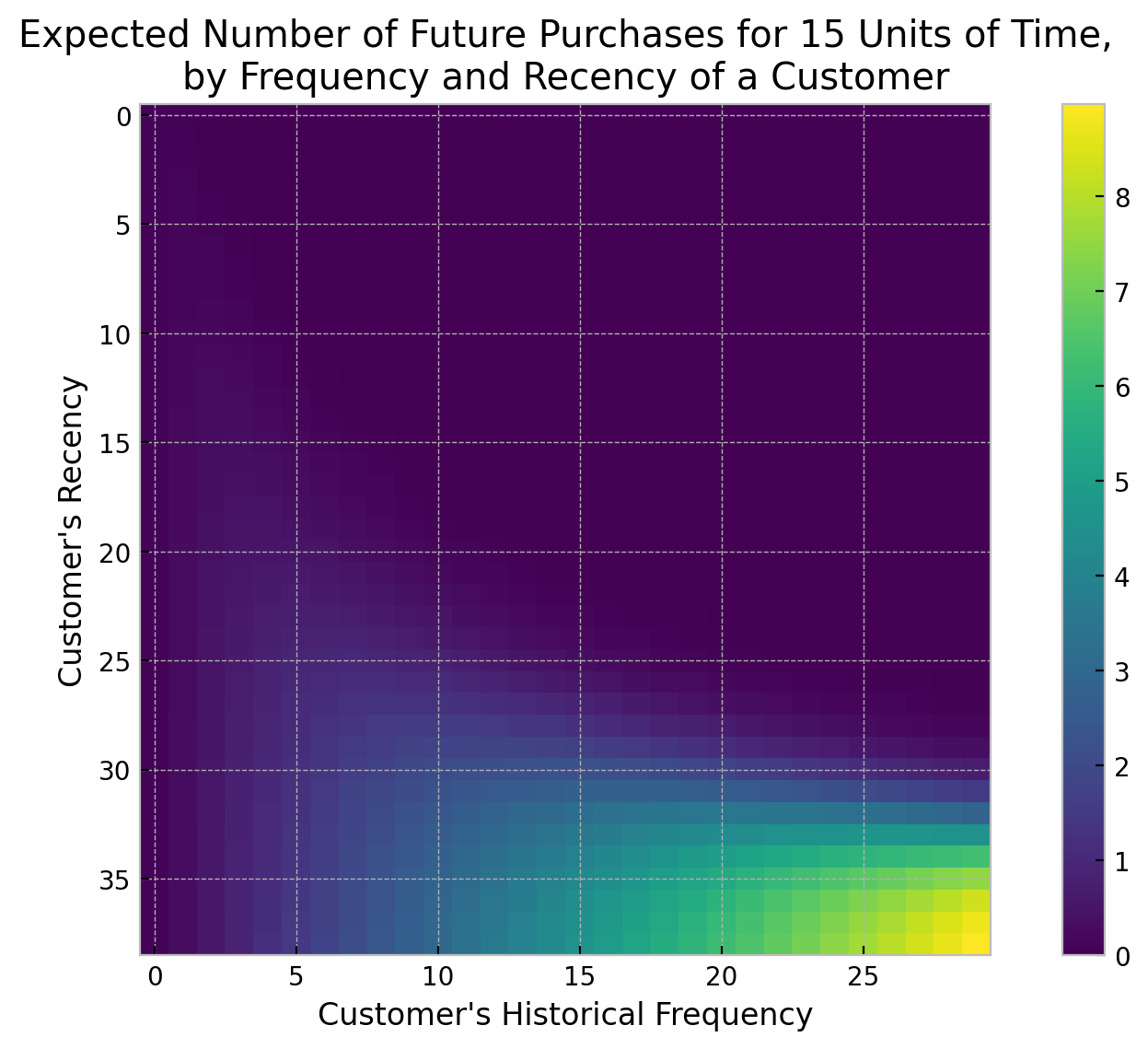
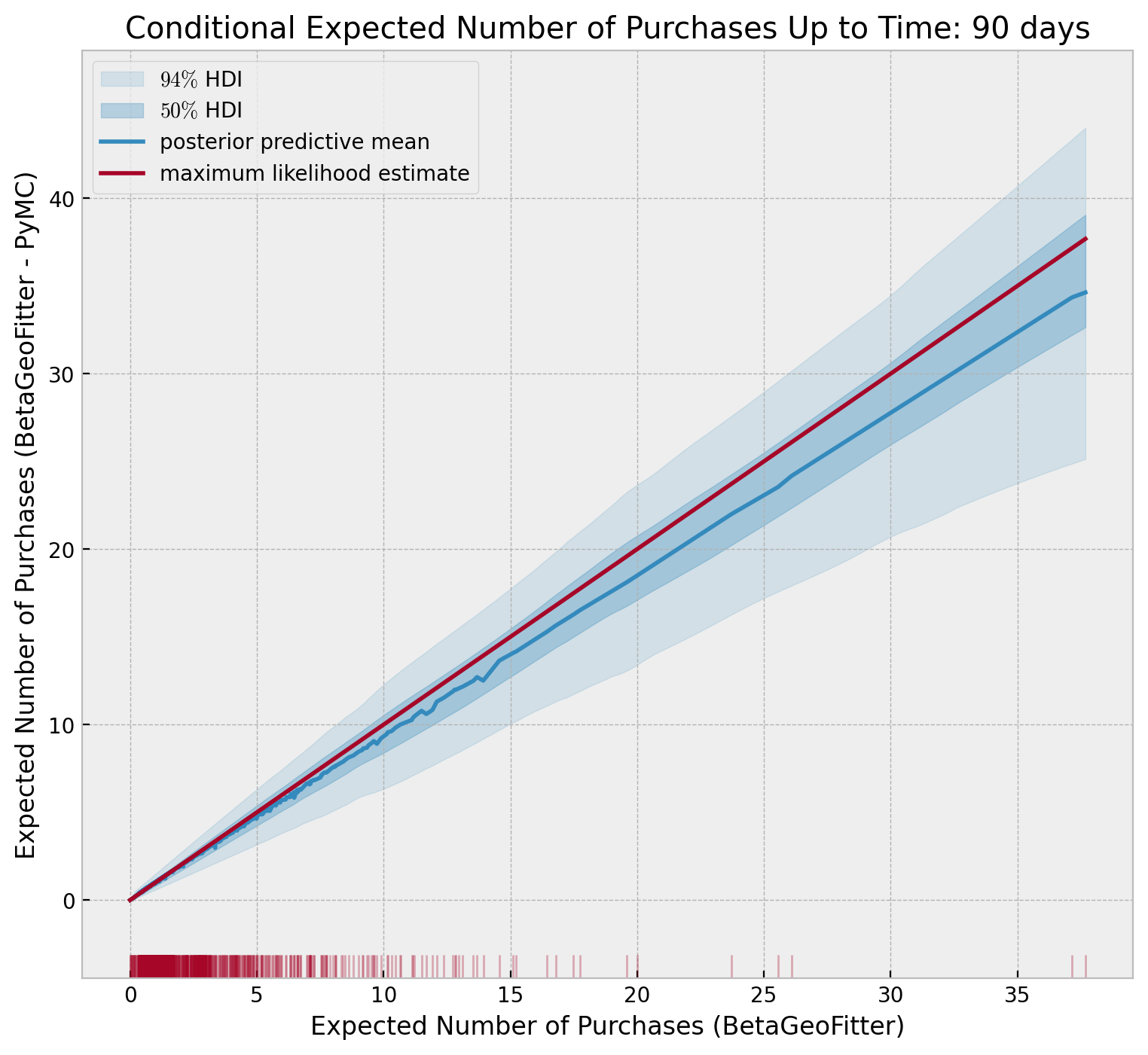
Future Purchases
Similarty, using the analytical expressions:
Time-Independent Covariates?
Allow covariates \(z_1\) and \(z_2\) to explain the cross-sectional heterogeneity in the purchasing process and cross-sectional heterogeneity in the dropout process respectively.
The likelihood and quantities of interests computed by computing expectations, remain almost the same. One only has to replace:
\[\begin{align*}
\alpha & \longmapsto \alpha_{0}\exp(-\gamma_{1}^{T}z_{1}) \\
a & \longmapsto a_{0}\exp(\gamma_{2}^{T}z_{2}) \\
b & \longmapsto b_{0}\exp(\gamma_{3}^{T}z_{2})
\end{align*}\]
Simulated Example
np.random.seed(42)# construct covariatemu =0.4rho =0.7z = np.random.binomial(n=1, p=mu, size=x.size)# change frequency values by reducing it the values where z !=0x_z = np.floor(x * (1- (rho * z)))# make sure the recency is zero whenever the frequency is zerot_x_z = t_x.copy()t_x_z[np.argwhere(x_z ==0).flatten()] =0# sanity checksassert x_z.min() ==0assert np.all(t_x_z[np.argwhere(x_z ==0).flatten()] ==0)
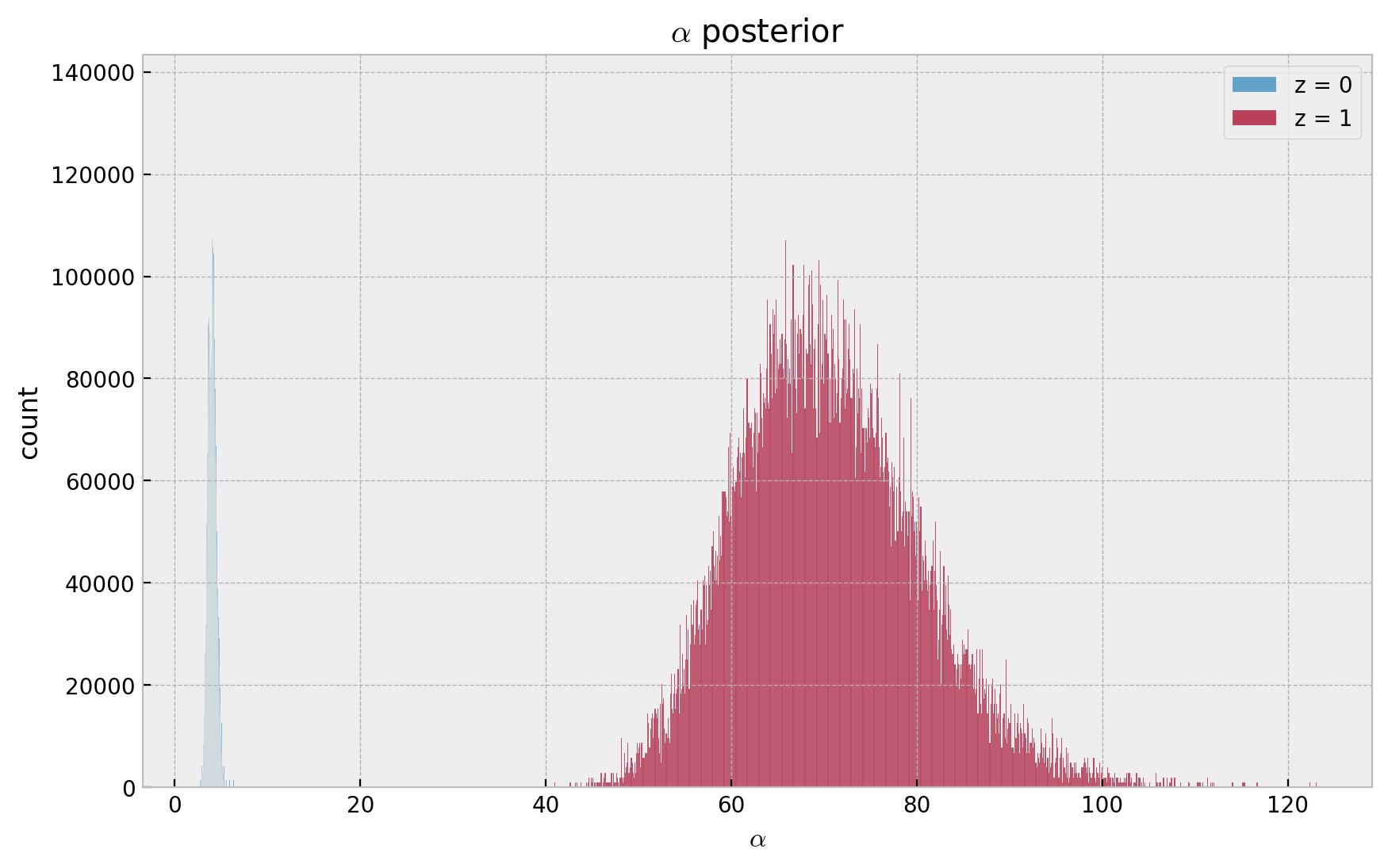
\(z = 1 \Rightarrow\) the frequency is reduced by \(70\%\).
PyMC Model
with pm.Model() as model_cov: a = pm.HalfNormal(name="a", sigma=10) b = pm.HalfNormal(name="b", sigma=10) alpha0 = pm.HalfNormal(name="alpha0", sigma=10) g1 = pm.Normal(name="g1", mu=0, sigma=10) alpha = pm.Deterministic(name="alpha", var=alpha0 * at.exp(- g1 * z)) r = pm.HalfNormal(name="r", sigma=10)def logp(x, t_x, T, x_zero): ... likelihood = pm.Potential( name="likelihood", var=logp(x=x_z, t_x=t_x_z, T=T, x_zero=x_zero_z), )
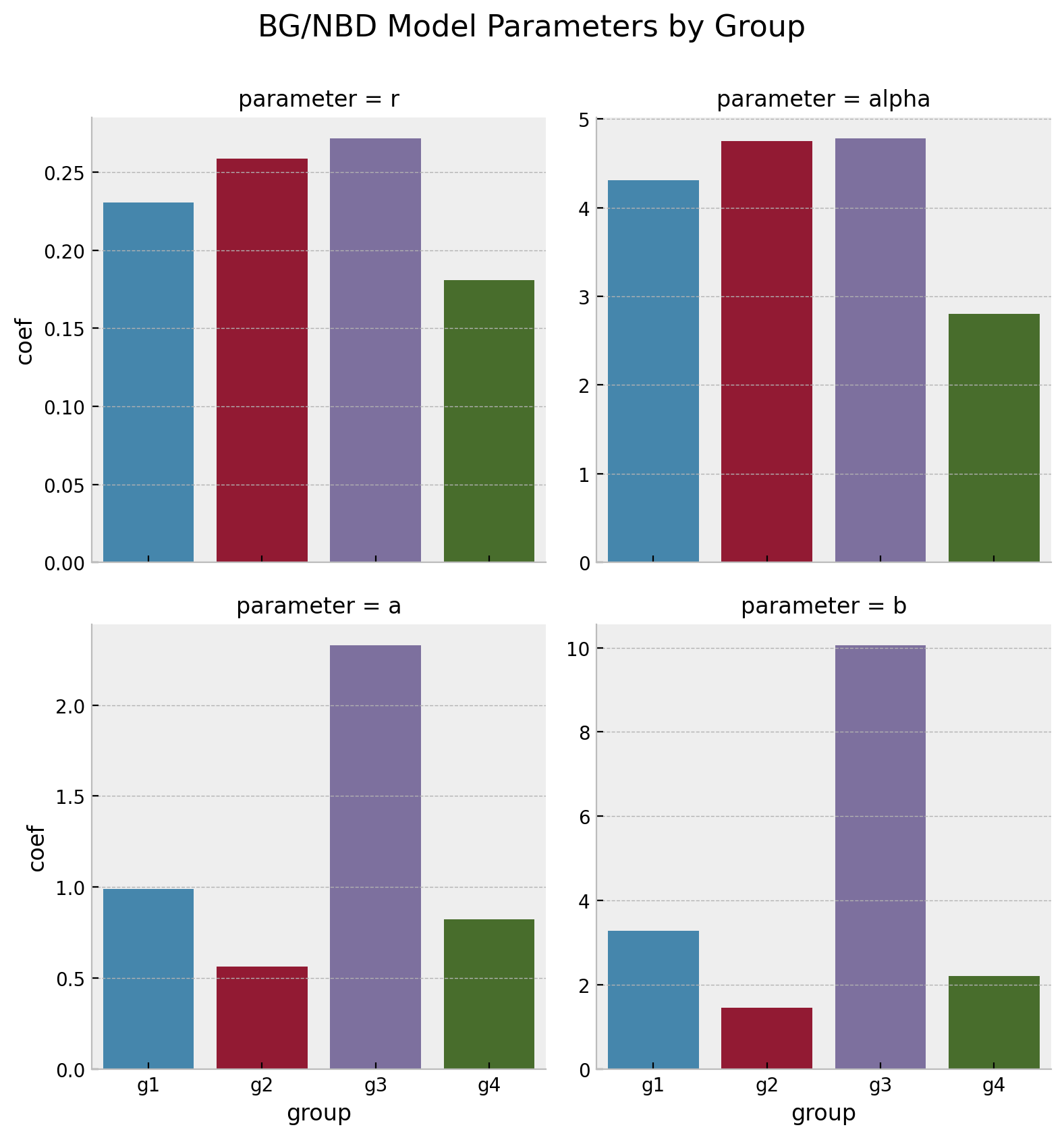
Model Parameters
Effect in Parameters
Recall \(\lambda \sim \text{Gamma}(r, \alpha)\), which has expected value \(r/\alpha\).
As \(g_1 < 0\), then \(\alpha(z=1) > \alpha(z=0)\) which is consistent with the data generation process.