In this notebook we present a concrete example of estimating the media effects via bayesian methods, following the strategy outlined in Google’s paper Jin, Yuxue, et al. “Bayesian methods for media mix modeling with carryover and shape effects.” (2017). This example can be considered the continuation of the post Media Effect Estimation with Orbit’s KTR Model. However, it is not strictly necessary to read before as we make this notebook self-contained. In addition, we provide some remarks and references regarding MMM projects in practice.
Remark: If you are interested in this topic (and other applications of bayesian methods in marketing!) please take a look into the pymc-marketing project. I am working together with PyMC Labs and other contributors to open source some interesting models (including MMMs)!
Data Generation Process
In Part I of the post Media Effect Estimation with Orbit’s KTR Model, we generated a synthetic dataset where we modeled a target variable y (sales) as a function of a trend, a seasonal component and an external regressor z (media spend). The effect of z on y was specified by the composition two transformations: a carryover effect (adstock) and a shape (saturation) effect.These two transformations have proven successful in practical Media Mix Modeling.
- The (geometric) adstock transformation is parametrized by the decaying parameter \(\alpha\) and the carryover parameter \(\ell\). For this specific dataset, we set \(\alpha = 0.5\) and \(\ell =12\).
- The saturation effect is parametrized by the shape parameter \(\lambda\). In this example we set \(\lambda=0.15\).
In the previous post (where we used the greek letter \(\mu\) for the shape parameter), we transformed the variable z as:
\[ z \xrightarrow{\text{adstock}(\alpha)} z_{\text{adstock}} \xrightarrow{\text{saturation}(\lambda)} z_{\text{effect}} \]
and generated y as:
\[ y(t) = \beta_{0} + \beta_{\text{trend}}\:\text{trend} + \beta_{\text{seasonality}}\:\text{seasonality} + \beta_{z}(t)\:z_{\text{effect}} + \varepsilon \]
where the beta coefficient \(\beta_{z}(t)\) was a (smooth) decaying function encoding the diminishing returns over time.
Prophet and KTR Models
In the previous post the Media Effect Estimation with Orbit’s KTR Model we fitted two models:
Prophet: Given the strong seasonal patter nof the time series, we used a Prophet model as a baseline. This model was able to successfully capture the trend ans seasonal components. On the other hand, the estimated regression coefficients \(\widehat{\beta}_{z}(t)=\widehat{\beta}_{\text{Prophet}}\) was a constant (i.e. constant over time, as expected) very close to the median of \(z_{\text{effect}}\).
KTR (Kernel-based Time-varying Regression): The second model we used was Orbit’s KTR model, on which regression coefficients are allowed to vary over time by using kernel smooths (see Edwin, Ng, et al. “Bayesian Time Varying Coefficient Model with Applications to Marketing Mix Modeling” for more details). For this example, the model has able to give a good approximation \(\widehat{\beta}_{z}(t)=\widehat{\beta}_{\text{KTR}}\) to the true \(\beta_{z}(t)\) coefficient.
It is important to emphasize that both models where fitted using z_adstock as the external regressor. That is, we assumed the value of alpha was given as it is not straight forward to estimate it using the models above.
PyMC Model
Motivated by the results above, we now want to build a bayesian model to estimate \(\alpha\), \(\lambda\) and \(\beta_z(t)\) simultaneously (as well as the other regression coefficients for the trend and seasonality). We will use the PyMC motivated by the following great resources:
- Simulated Example by Dr. Robert Kübler:
- An Upgraded Marketing Mix Modeling in Python
- Bayesian Marketing Mix Modeling in Python via PyMC3
- Rockin‘ Rolling Regression in Python via PyMC3
- HelloFresh’s Media Mix Model: Bayesian Marketing Mix Modeling in Python via PyMC3. Here are some additional references for this use cases:
- Article: Bayesian Media Mix Modeling using PyMC3, for Fun and Profit
- Video: A Bayesian Approach to Media Mix Modeling by Michael Johns & Zhenyu Wang
- Articles by PyMC Labs:
Of course, the main motivation is Google’s paper Jin, Yuxue, et al. “Bayesian methods for media mix modeling with carryover and shape effects” (2017). Moreover, for a discussion of MMM in practice please see Chan, David, et al. “Challenges and Opportunities in Media Mix Modeling” (2017)
As usual in applied data analysis, we will start from simple models and iterate to add more complexity. Moreover, we will follow the recommended bayesian workflow.
Some Additional Remarks on MMM in Practice
MMM Projects
There are many existing projects regarding media mix models. Two of the most known ones are
- Facebook’s Robyn: This model uses a combination of Prophet (trend-seasonality model) and a ridge regression to model media data.
- Google’s LightweightMMM: This project in essence follows the approach we describe in this post. The code is written in Numpyro.
Which Media Data to Use?
In this simulated example we are using media spend as regressor for the media variable. Nevertheless, in practice this is not the best choice as described in the Analysts guide to MMM from Facebook’s Robyn documentation:
Data collected for media ideally should reflect how many “eyeballs” have seen or been exposed to the media (e.g. impressions, GRPs). Spends should also be collected in order to calculate Return On Investment, however it is best practice to use exposure metrics as direct inputs into the model, as this is a better representation than spends of how media activity has been consumed by consumers.
So, if we use impressions in the model, how to include the cost data? There are various alternatives. For example:
Facebook’s Robyn: Includes the costs data as part of the model selection. They train many models and the user has to select the best among two metrics: model fit (NRMSE) and the predicted cost distribution (DECOMP.RSSD), see here for details.
Googles’s LightweightMMM: Their approach is fully-bayesian so they include the cost data as part of the prior distributions of the model.
Remark: In practice, I have used Googles’s LightweightMMM approach to include costs as part of the priors with PyMC models as the one presented in this post. The results are quite good and personally I like it more that the manual-model selection approach.
Controling for Seasonality and other Factors: Causal Graph
As Richard McElreath would say (paraphrasing from his amazing lectures!) “Do not try to be clever, build a causal graph model!” Indeed, it is not worth trying to add all control variables to the media mix models and hope to solve all confounding effects. A much better approach (strongly recommended!) is to build a causal graph. For more details about this approach I recommend Statistical Rethinking by Richard McElreath (and the corresponding YouTube videos). Once we have a causal model, we can actually use software (for example dagitty: Graphical Analysis of Structural Causal Models in R) to help us with the regression model structure. For example, let’s consider a simple causal graph:
library(dagitty)
dag <- dagitty( x = "dag {
TV -> Search -> Conversions
TV -> Conversions
Seasonality -> Conversions
Seasonality -> Search
Seasonality -> Facebook -> Search
}" )
coordinates( x = dag ) <- list(
x = c(
"Seasonality" = -1,
"TV" = 0,
"Search" = 1,
"Facebook" = 0,
"Conversions" = 2
),
y = c(
"Seasonality" = 1,
"TV" = -1,
"Search" = 0,
"Facebook" = 0,
"Conversions" = 0
)
)
plot( dag )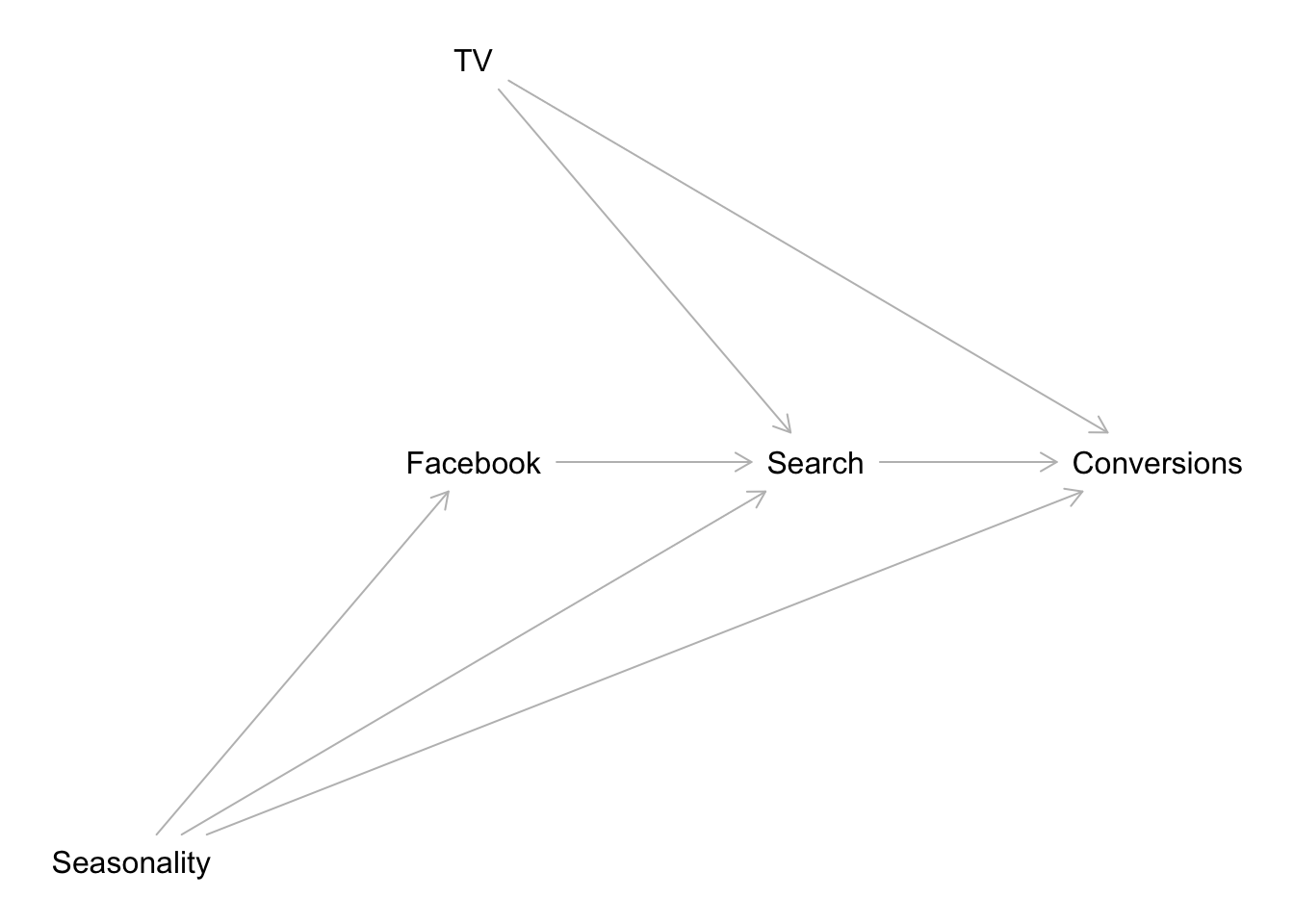
We would like to estimate the effect of TV on Conversions. To begin, we can get the list of conditional independence statements that must hold in every probability distribution compatible with the given model.
impliedConditionalIndependencies( x = dag )## Cnvr _||_ Fcbk | Srch, Ssnl, TV
## Fcbk _||_ TV
## Ssnl _||_ TVWe can use the data to test these implications. Next, we can get the sets of covariates that (asymptotically) allow unbiased estimation of causal effects from observational data, assuming that the input causal graph is correct (by looking into the back-door criterion). For example to estimate the direct effect of TV on Conversions we run:
adjustmentSets( x = dag , exposure = "TV", outcome = "Conversions", type = "canonical")## { Facebook, Seasonality }This shows that the regression model structure should be
Conversions ~ Intercept + TV + Facebook + Seasonality.
On the other hand, if we want the effect of Facebook to Conversions we run:
adjustmentSets( x = dag , exposure = "Facebook", outcome = "Conversions", type = "canonical")## { Seasonality, TV }Hence, the correct model (given the graph causal model!) is
Conversions ~ Intercept + Facebook + TV + Seasonality
That is, we can use the model Conversions ~ Intercept + Facebook + TV + Seasonality to estimate the effects of both TV and Facebook in conversions. Note that we should not include Search in the regression model!
Again, no need to be clever, just specify the causal model. One could argue that for digital channels (like Facebook) the media data is already driven by seasonality, so adding additional Fourier modes can be counterproductive. However, given a causal graph as above this is actually not the case. One can extend this type of analysis for additional external factors to be consider in the media mix model.
Remark: There are of course other strategies to model seasonality. Certain modelers suggest to add time-variant coefficients to encode seasonality via Gaussian processes (see for example the post You’re probably modeling seasonality the wrong way).
Remark: To estimate the cost of incremental sales by considering the funnels effects (causal graph) please refer to the excellent blog post Bayesian Media Mix Modeling using PyMC3, for Fun and Profit
For more examples and details about good and bad controls you can look into the article A Crash Course in Good and Bad Controls.
Adstock and Saturation Order
Note that the adstock and saturation transformations do not commute (i.e. the order matters). So which one to apply first? I recommend you look into Section 2.3 Combining the Carryover and the Shape Effect in Jin, Yuxue, et al. “Bayesian methods for media mix modeling with carryover and shape effects.” (2017). The rule of thumb is to apply:
- Adstock transformation first if: the media spend in each time period is relatively small compared to the cumulative spend across multiple time periods.
- Saturation transformation first if: the media spend is heavily concentrated in some single time periods with an on-and-off pattern.
ROAS and mROAS
One of the most important outputs of the model are the Return on Ad Spend (ROAS) and and the marginal ROAS (mROAS), see Section 4.1 in Jin, Yuxue, et al. “Bayesian methods for media mix modeling with carryover and shape effects.” (2017). In this post we describe how to extract them from the bayesian model in PyMC. Moreover, we compare the inferred with the true values which can be easily computed in an additive model.
In practice one can actually calibrate the model through the priors (this is one of the key benefits of going fully bayesian) using geo-lift tests, see for example the article Estimating Ad Effectiveness using Geo Experiments in a Time-Based Regression Framework (and for alternative methodologies see for example the blog post Synthetic Control in PyMC).
It is All about the Data
As any other data science project the data is the key factor of the success of an MMM project. As the main idea of an MMM is to estimate effects across many digital and offline channels, the data collection can be challenging (it usually is). Hence, the recommendation is to spend a significant par of the project collecting and understanding the data: Where is the data coming from? How is it transformed and stored? Outliers? Missing values?
Remark: The Analysts guide to MMM from Facebook’s Robyn gives nice tips about planing and executing an MMM project (steps, data collection, timeline, etc.).
Prepare Notebook
import pytensor.tensor as pt
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pymc.sampling_jax
import seaborn as sns
from scipy.stats import pearsonr
from sklearn.preprocessing import MaxAbsScaler
import xarray as xr
plt.style.use("bmh")
plt.rcParams["figure.figsize"] = [10, 6]
plt.rcParams["figure.dpi"] = 100
%load_ext rich
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"Read Data
We start by reading the data. This csv was generated in the post Media Effect Estimation with Orbit’s KTR Model, please refer to it for details. Here we give a quick overview of the data.
data_path = "https://raw.githubusercontent.com/juanitorduz/website_projects/master/data/ktr_data.csv"
data_df = pd.read_csv(data_path, parse_dates=["date"])
data_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 179 entries, 0 to 178
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 index 179 non-null int64
1 date 179 non-null datetime64[ns]
2 year 179 non-null int64
3 month 179 non-null int64
4 dayofyear 179 non-null int64
5 z 179 non-null float64
6 z_adstock 179 non-null float64
7 z_adstock_saturated 179 non-null float64
8 beta 179 non-null float64
9 z_effect 179 non-null float64
10 effect_ratio 179 non-null float64
11 effect_ratio_smooth 179 non-null float64
12 trend 179 non-null float64
13 cs 179 non-null float64
14 cc 179 non-null float64
15 seasonality 179 non-null float64
16 intercept 179 non-null float64
17 trend_plus_intercept 179 non-null float64
18 epsilon 179 non-null float64
19 y 179 non-null float64
dtypes: datetime64[ns](1), float64(15), int64(4)
memory usage: 28.1 KBLet us now plot the most relevant variables for the analysis:
fig, ax = plt.subplots(
nrows=3,
ncols=1,
figsize=(12, 9),
sharex=True,
sharey=False,
layout="constrained"
)
sns.lineplot(x="date", y="y", color="black", data=data_df, ax=ax[0])
ax[0].set(title="Sales (Target Variable)")
sns.lineplot(x="date", y="z_effect", color="C3", data=data_df, ax=ax[1])
ax[1].set(title="Media Cost Effect on Sales")
sns.lineplot(x="date", y="z", data=data_df, ax=ax[2])
ax[2].set(title="Raw Media Cost Data");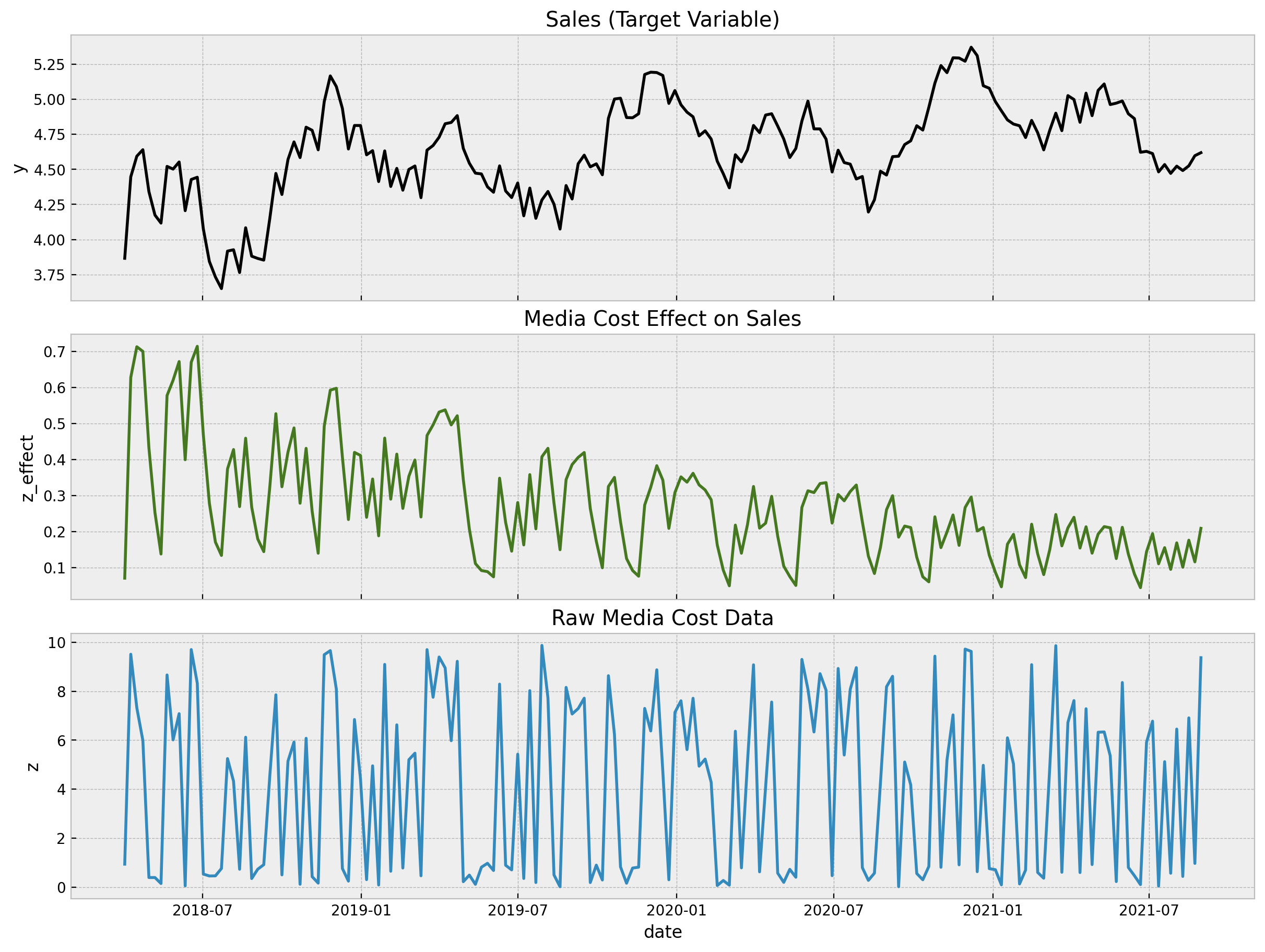
- The first plot is our target variable
y, which can represent sales data, for example. - The second plot is the
z_effectvariable, which is the simulated effect of the media spent variablezon the variabley. In practice we do not knowz_effect. We would like to infer it from the data! - The last plot represent the input data
zwhich is something we have control of.
Note that the variable y has a trend and strong (additive) yearly seasonality components.
Features
We of course do not want to use the trend os seasonal components from the data_df dataframe, as the whole point id to learn them tom the data. Hence, let us keep the variables we would actually have in when developing the model.
columns_to_keep = ["index", "date", "year", "month", "dayofyear", "z", "y"]
df = data_df[columns_to_keep].copy()Next, we generate input features to model the trend and seasonal components. We follow the strategy presented in the very comprehensive post Air passengers - Prophet-like model from the pymc-examples repository (please check it out!).
Trend
For the trend component we simply use a linear feature (which we scale between \(0\) and \(1\)).
t = (df.index - df.index.min()) / (df.index.max() - df.index.min())Seasonality
To model the seasonality, we use Fourier modes (similarly as in Prophet or Orbit).
n_order = 7
periods = df["dayofyear"] / 365.25
fourier_features = pd.DataFrame(
{
f"{func}_order_{order}": getattr(np, func)(2 * np.pi * periods * order)
for order in range(1, n_order + 1)
for func in ("sin", "cos")
}
)We can see how these cyclic features look like:
fig, ax = plt.subplots(nrows=2, sharex=True, layout="constrained")
fourier_features.filter(like="sin").plot(color="C0", alpha=0.15, ax=ax[0])
ax[0].get_legend().remove()
ax[0].set(title="Fourier Modes (Sin)", xlabel="index (week)")
fourier_features.filter(like="cos").plot(color="C1", alpha=0.15, ax=ax[1])
ax[1].get_legend().remove()
ax[1].set(title="Fourier Modes (Cos)", xlabel="index (week)");
Finally, we extract the target and features as numpy arrays.
date = df["date"].to_numpy()
date_index = df.index
y = df["y"].to_numpy()
z = df["z"].to_numpy()
t = t.values
n_obs = y.sizeScaling
We scale both the target variable y and the channel input z using a MaxAbsScaler. During the whole analysis we carefully study the effect of these scalers and describe how to recover back the predictions and effects in the original scale.
Remark: One would be tempted to use a MinMaxScaler here. However, this would lead to a problem when computing the
(m)ROAS (see more details below). The reason is that for the ROAS computation we want to set the media cost to \(0\) (in the raw data
scale!) and generate in-sample predictions. The problem comes when the media data never reaches \(0\). In this case,
when using a MaxAbsScaler, the zero value of the transformed variable represents the minimum value of the
original variable. Hence, when setting the media cost to \(0\), the transformed variable would be less than zero.
This itself not a problem, but since most og the times we are restricting the regression coefficients of the
media variables to be positive (e.g. via a pm.HalfNormal prior) then the media contribution of in the ROAS computation would be negative! This of course does not make sense. Hence, we use a MaxAbsScaler here, which
ensures that the zero in the transformed variable is the zero in the original variable.
endog_scaler = MaxAbsScaler()
endog_scaler.fit(y.reshape(-1, 1))
y_scaled = endog_scaler.transform(y.reshape(-1, 1)).flatten()
channel_scaler = MaxAbsScaler()
channel_scaler.fit(z.reshape(-1, 1))
z_scaled = channel_scaler.transform(z.reshape(-1, 1)).flatten()Models
In this section we fit \(3\) models, from simpler to complex:
1. Base Model: We fit a linear regression model with a single regressor z and controlling from trend ans seasonality.
Adstock-Saturation Model: We use the same model structure as the base model but we now apply the (geometric) adstock and saturation transformations to the
zvariable. We do not set a value for \(\alpha\) and \(\lambda\) as we learn them from the data. We do fix the variable \(\ell=12\) of the adstock transformation.Adstock-Saturation-Diminishing Returns Model: We use the same model structure as the Adstock-Saturation model but we allow a time-varying coefficient for (the transformed)
zby modeling it as a gaussian random walk.
Here are some comments on the models:
- We use a
pm.HalfNormaldistribution for the media coefficients to ensure they are positive. - We use a
pm.Laplacedistribution fot the fourier coefficient to add certain regularization (these features can easily lead to an overfit). - For the likelihood function we use a
pm.StudentTdistribution which is most robust against outliers.
Base Model
Let us start by defining the structure of the base model, which is the be the core of the models to come.
- Model Specification
coords = {"date": date, "fourier_mode": np.arange(2 * n_order)}
with pm.Model(coords=coords) as base_model:
# --- coords ---
base_model.add_coord(name="dat", values=date, mutable=True)
base_model.add_coord(name="fourier_mode", values=np.arange(2 * n_order), mutable=False)
# --- data containers ---
z_scaled_ = pm.MutableData(name="z_scaled", value=z_scaled, dims="date")
# --- priors ---
## intercept
a = pm.Normal(name="a", mu=0, sigma=4)
## trend
b_trend = pm.Normal(name="b_trend", mu=0, sigma=2)
## seasonality
b_fourier = pm.Laplace(name="b_fourier", mu=0, b=2, dims="fourier_mode")
## regressor
b_z = pm.HalfNormal(name="b_z", sigma=2)
## standard deviation of the normal likelihood
sigma = pm.HalfNormal(name="sigma", sigma=0.5)
# degrees of freedom of the t distribution
nu = pm.Gamma(name="nu", alpha=25, beta=2)
# --- model parametrization ---
trend = pm.Deterministic(name="trend", var=a + b_trend * t, dims="date")
seasonality = pm.Deterministic(
name="seasonality", var=pm.math.dot(fourier_features, b_fourier), dims="date"
)
z_effect = pm.Deterministic(name="z_effect", var=b_z * z_scaled_, dims="date")
mu = pm.Deterministic(name="mu", var=trend + seasonality + z_effect, dims="date")
# --- likelihood ---
pm.StudentT(name="likelihood", nu=nu, mu=mu, sigma=sigma, observed=y_scaled, dims="date")
# --- prior samples ---
base_model_prior_predictive = pm.sample_prior_predictive()
pm.model_to_graphviz(model=base_model)
- Prior Predictive Samples
Let us start by sampling from the model before looking into the data:
# useful way to color the distribution
palette = "viridis_r"
cmap = plt.get_cmap(palette)
percs = np.linspace(51, 99, 100)
colors = (percs - np.min(percs)) / (np.max(percs) - np.min(percs))
fig, ax = plt.subplots()
for i, p in enumerate(percs[::-1]):
upper = np.percentile(base_model_prior_predictive.prior_predictive["likelihood"], p, axis=1)
lower = np.percentile(
base_model_prior_predictive.prior_predictive["likelihood"], 100 - p, axis=1
)
color_val = colors[i]
ax.fill_between(
x=date,
y1=upper.flatten(),
y2=lower.flatten(),
color=cmap(color_val),
alpha=0.1,
)
sns.lineplot(x=date, y=y_scaled, color="black", label="target (scaled)", ax=ax)
ax.legend()
ax.set(title="Base Model - Prior Predictive Samples");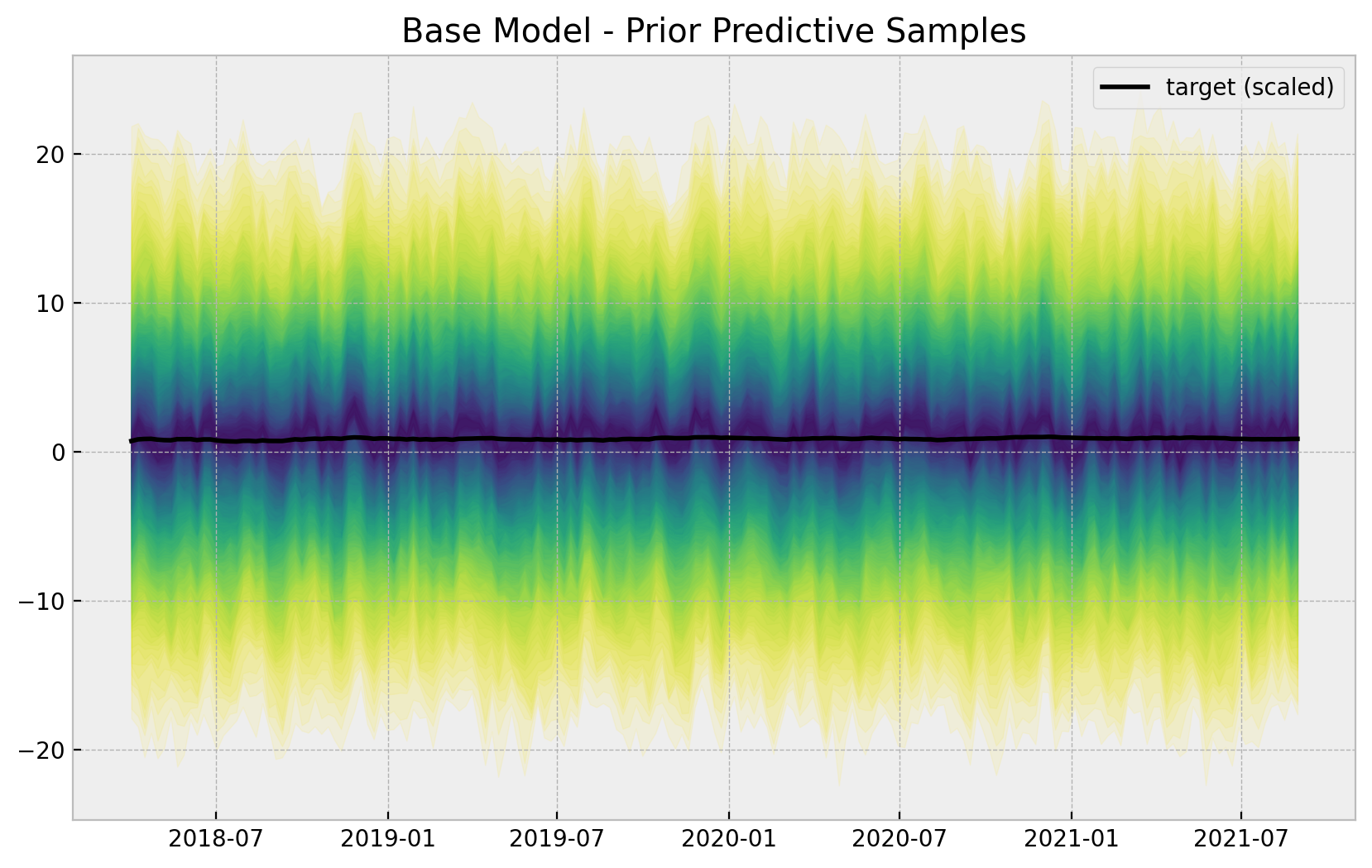
The priors do constrain the range of the generated time series. Nevertheless, they are not too restrictive.
Remark: Note that the prior predictive shows the possibility of having negative sales which makes no sense. A common approach is to model the logarithm of the sales instead. We do not do this here for the sake of simplicity (specially when interpreting the results).
- Fit Model
with base_model:
base_model_trace = pm.sample(
nuts_sampler="numpyro",
draws=6_000,
chains=4,
idata_kwargs={"log_likelihood": True},
)
base_model_posterior_predictive = pm.sample_posterior_predictive(
trace=base_model_trace
)Remark: We add the argument idata_kwargs={"log_likelihood": True} since we want to compare various models using az.compare. See this issue for more details.
- Model Diagnostics
az.summary(
data=base_model_trace,
var_names=["a", "b_trend", "b_z", "sigma", "nu"],
)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a | 0.788 | 0.003 | 0.782 | 0.794 | 0.000 | 0.000 | 10981.0 | 14592.0 | 1.0 |
| b_trend | 0.119 | 0.005 | 0.110 | 0.127 | 0.000 | 0.000 | 12503.0 | 14556.0 | 1.0 |
| b_z | 0.049 | 0.004 | 0.042 | 0.056 | 0.000 | 0.000 | 12070.0 | 13574.0 | 1.0 |
| sigma | 0.016 | 0.001 | 0.014 | 0.018 | 0.000 | 0.000 | 11428.0 | 12666.0 | 1.0 |
| nu | 12.470 | 2.395 | 8.091 | 16.988 | 0.022 | 0.016 | 11155.0 | 13065.0 | 1.0 |
axes = az.plot_trace(
data=base_model_trace,
var_names=["a", "b_trend", "b_fourier", "b_z", "sigma", "nu"],
compact=True,
backend_kwargs={
"figsize": (12, 9),
"layout": "constrained"
},
)
fig = axes[0][0].get_figure()
fig.suptitle("Base Model - Trace");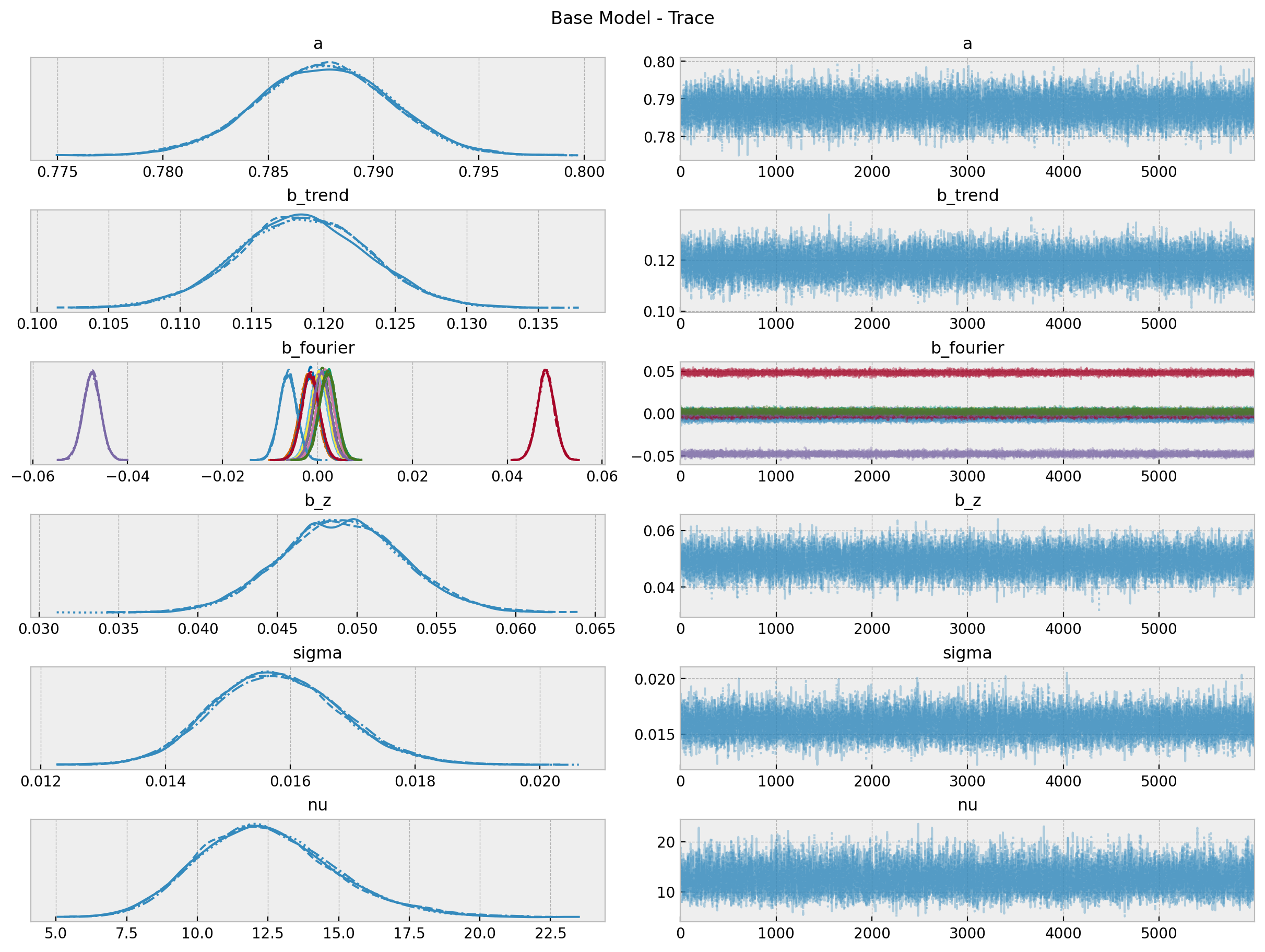
fig, ax = plt.subplots(figsize=(6, 4))
az.plot_forest(
data=base_model_trace,
var_names=["a", "b_trend", "b_z", "sigma"],
combined=True,
ax=ax
)
ax.set(
title="Base Model: 94.0% HDI",
xscale="log"
);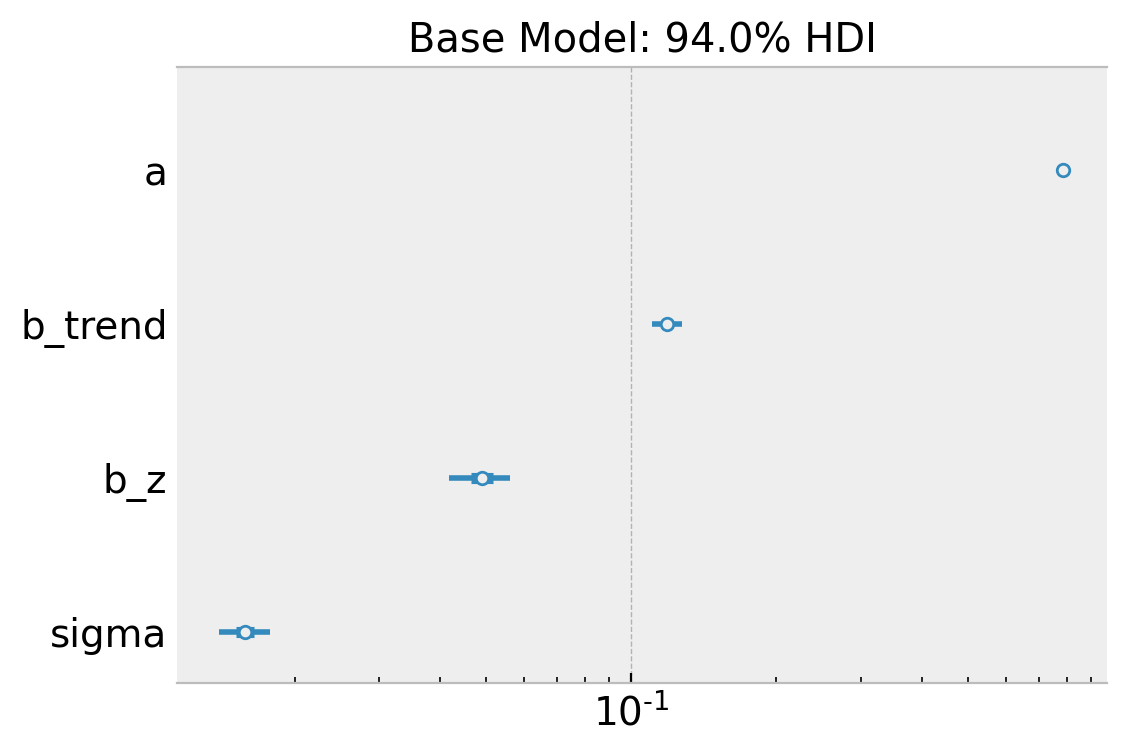
Overall, the model looks ok!
- Posterior Predictive Samples
posterior_predictive_likelihood = az.extract(
data=base_model_posterior_predictive,
group="posterior_predictive",
var_names="likelihood",
)
posterior_predictive_likelihood_inv = endog_scaler.inverse_transform(
X=posterior_predictive_likelihood
)
fig, ax = plt.subplots()
for i, p in enumerate(percs[::-1]):
upper = np.percentile(posterior_predictive_likelihood_inv, p, axis=1)
lower = np.percentile(posterior_predictive_likelihood_inv, 100 - p, axis=1)
color_val = colors[i]
ax.fill_between(
x=date,
y1=upper,
y2=lower,
color=cmap(color_val),
alpha=0.1,
)
sns.lineplot(
x=date,
y=posterior_predictive_likelihood_inv.mean(axis=1),
color="C2",
label="posterior predictive mean",
ax=ax,
)
sns.lineplot(
x=date,
y=y,
color="black",
label="target (scaled)",
ax=ax,
)
ax.legend(loc="upper left")
ax.set(title="Base Model - Posterior Predictive Samples");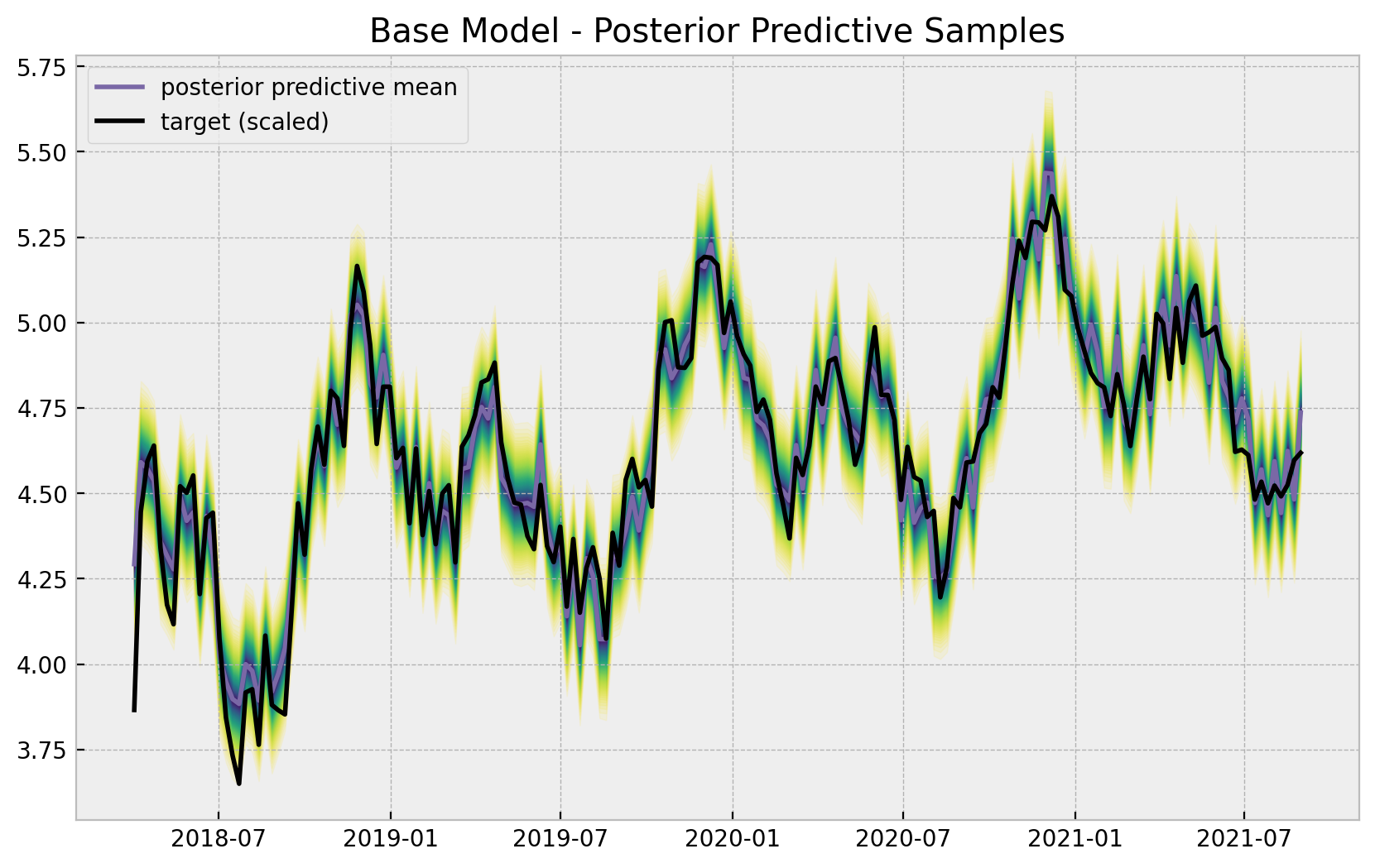
The base model does capture the trend and seasonality of the data. We can now plot the model components:
# compute HDI for all the model parameters
model_hdi = az.hdi(ary=base_model_trace)
fig, ax = plt.subplots()
for i, var_effect in enumerate(["z_effect", "trend", "seasonality"]):
ax.fill_between(
x=date,
y1=model_hdi[var_effect][:, 0],
y2=model_hdi[var_effect][:, 1],
color=f"C{i}",
alpha=0.3,
label=f"$94\%$ HDI ({var_effect})",
)
sns.lineplot(
x=date,
y=base_model_trace.posterior[var_effect]
.stack(sample=("chain", "draw"))
.mean(axis=1),
color=f"C{i}",
)
sns.lineplot(x=date, y=y_scaled, color="black", alpha=1.0, label="target (scaled)", ax=ax)
ax.legend(title="components", loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title="Base Model Components", ylabel="target (scaled)");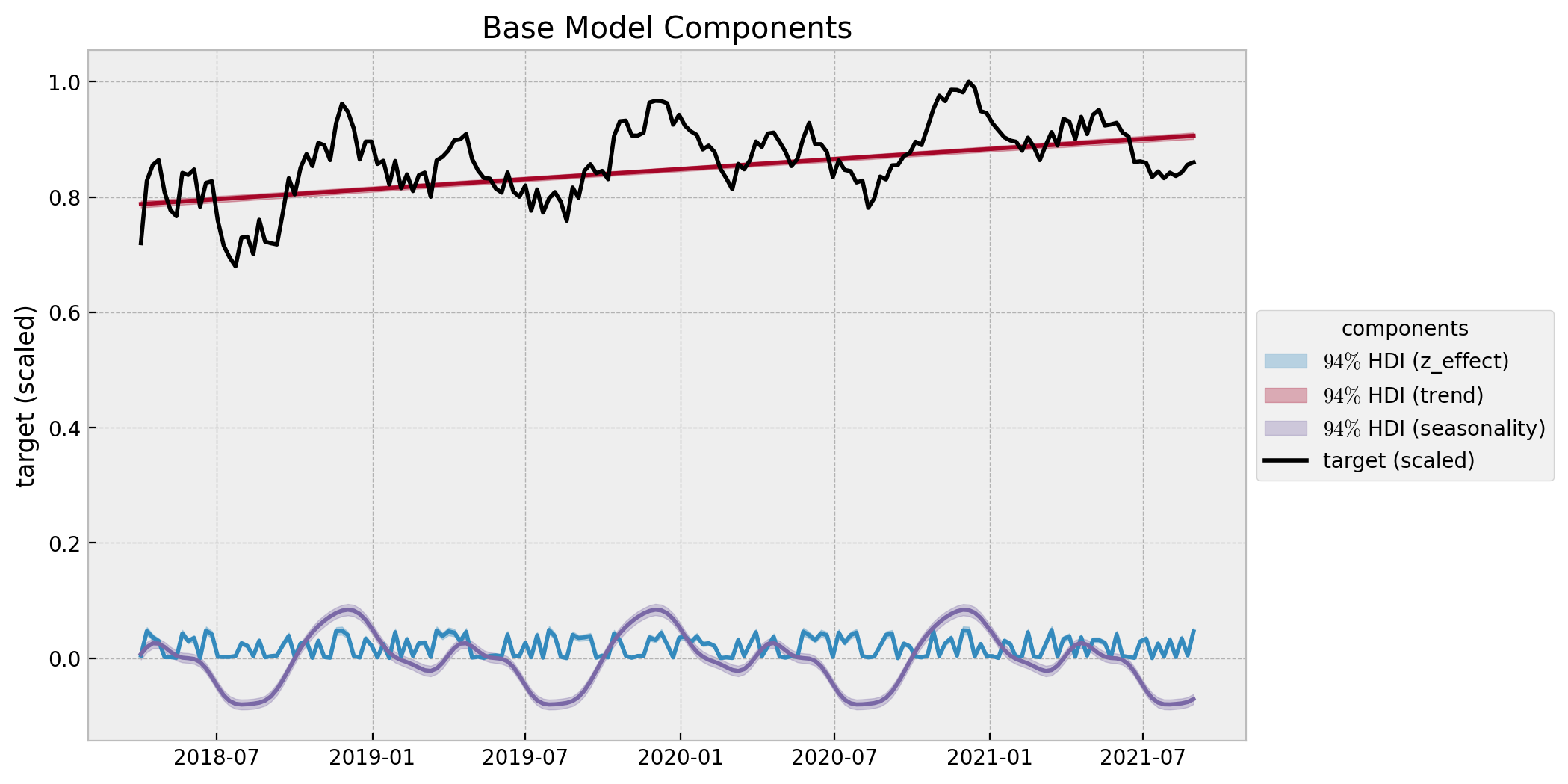
- Estimated
z_effect
Finally, let us look at the estimated effect of z on y. Let’s start by looking into the development over time.
z_effect_posterior_samples = xr.apply_ufunc(
lambda x: endog_scaler.inverse_transform(X=x.reshape(1, -1)),
base_model_trace.posterior["z_effect"],
input_core_dims=[["date"]],
output_core_dims=[["date"]],
vectorize=True,
)
z_effect_hdi = az.hdi(ary=z_effect_posterior_samples)["z_effect"]
fig, ax = plt.subplots()
ax.fill_between(
x=date,
y1=z_effect_hdi[:, 0],
y2=z_effect_hdi[:, 1],
color="C0",
alpha=0.5,
label="z_effect 94% HDI",
)
ax.axhline(
y=z_effect_posterior_samples.mean(),
color="C0",
linestyle="--",
label=f"posterior mean {z_effect_posterior_samples.mean().values: 0.3f}",
)
sns.lineplot(x="date", y="z_effect", color="C3", data=data_df, label="z_effect", ax=ax)
ax.legend(loc="upper right")
ax.set(title="Media Cost Effect on Sales Estimation - Base Model");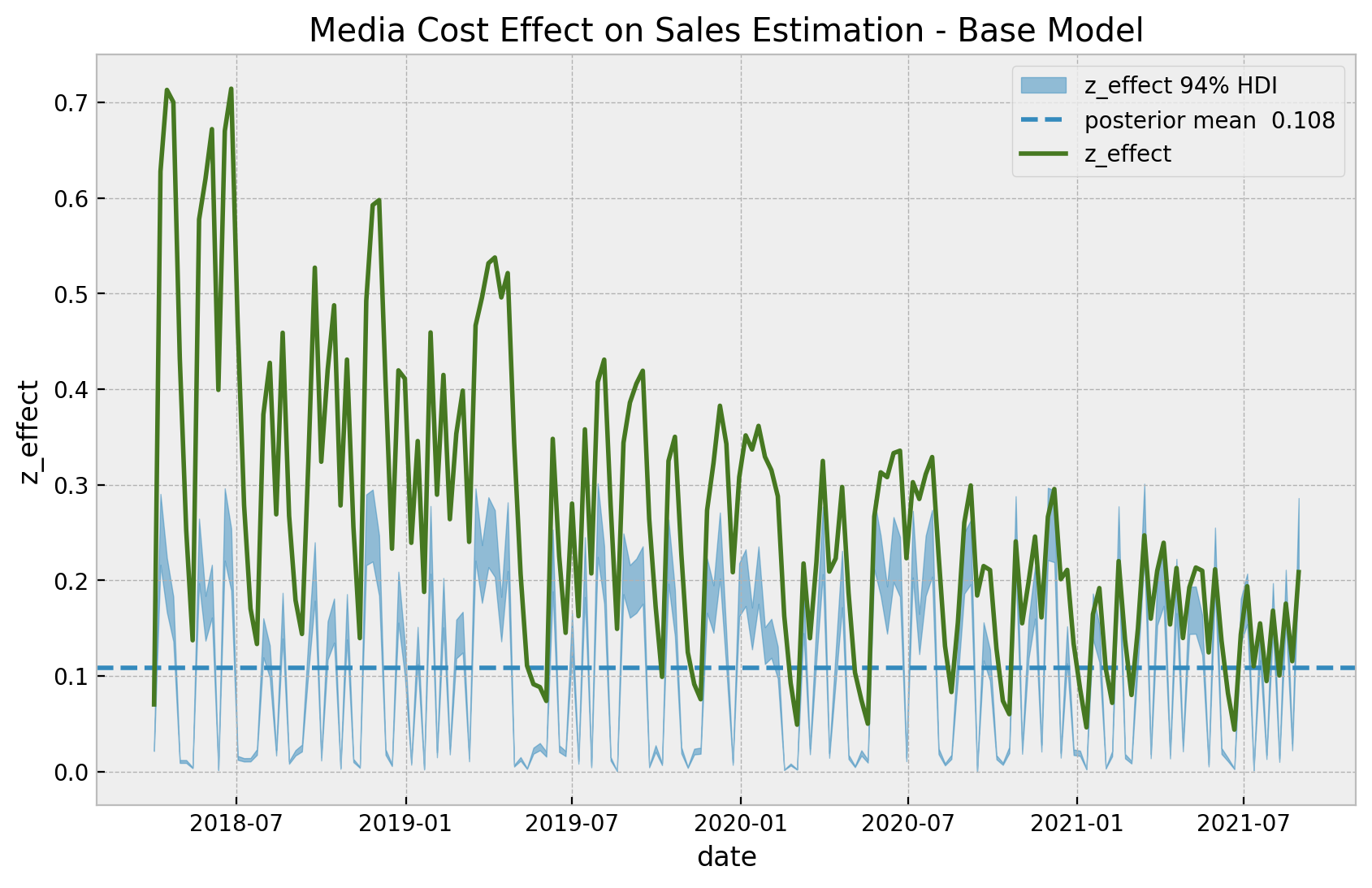
We clearly see that the effect of z is a linear function of z and does not depend on the time, as expected from the model specification. It is interesting to see that the variance of the estimated effect is similar to the real effect of the latest observations.
Next, we simply plot the estimated against the true values.
fig, ax = plt.subplots()
az.plot_hdi(
x=z,
y=z_effect_posterior_samples,
color="C0",
fill_kwargs={"alpha": 0.2, "label": "z_effect 94% HDI"},
ax=ax,
)
sns.scatterplot(
x="z",
y="z_effect_pred_mean",
color="C0",
size="index",
label="z_effect (pred mean)",
data=data_df.assign(
z_effect_pred_mean=z_effect_posterior_samples.mean(dim=("chain", "draw"))
),
ax=ax,
)
sns.scatterplot(
x="z",
y="z_effect",
color="C3",
size="index",
label="z_effect (true)",
data=data_df,
ax=ax,
)
h, l = ax.get_legend_handles_labels()
ax.legend(handles=h[:9], labels=l[:9], loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title="Base Model - Estimated Effect");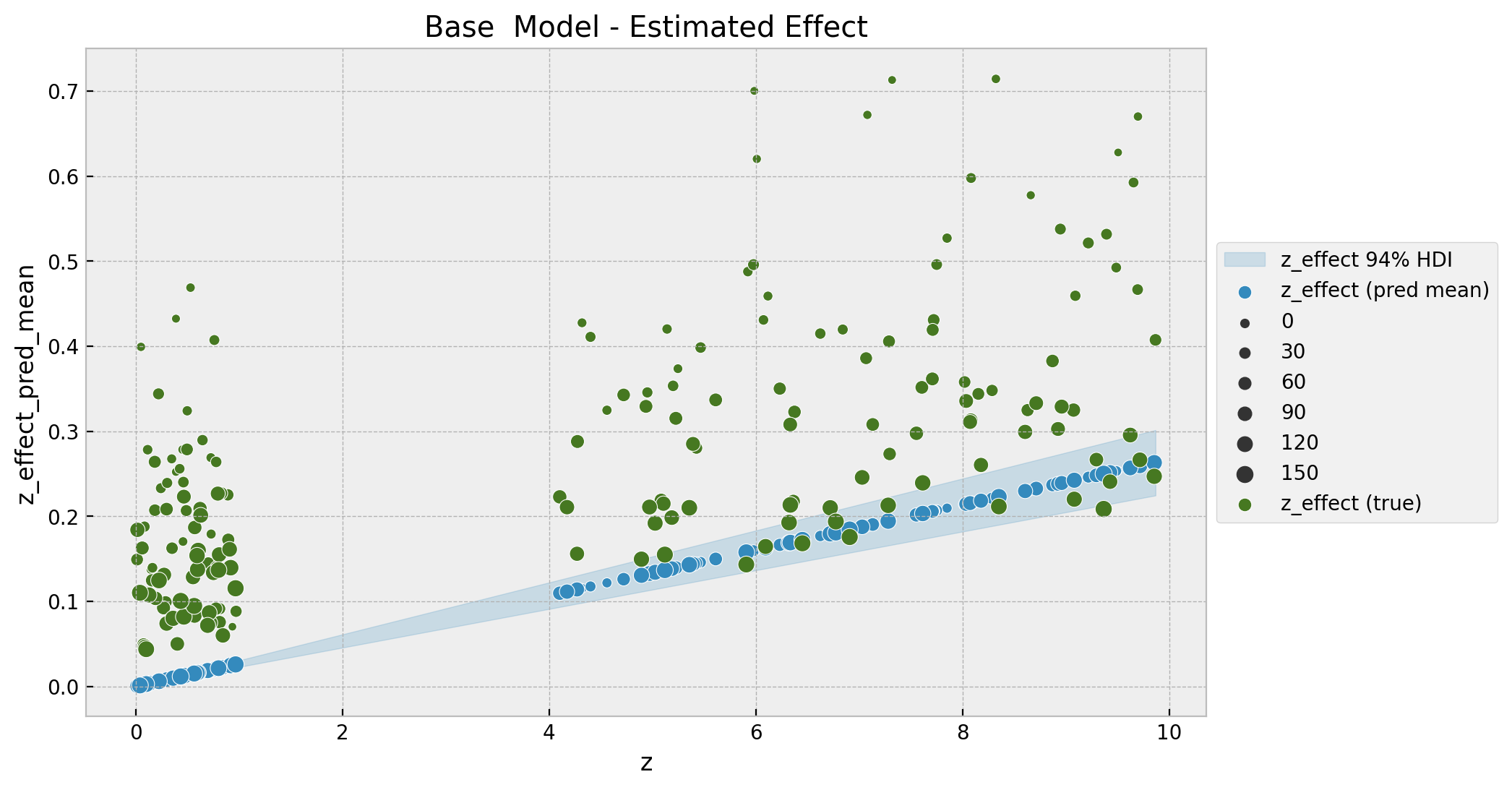
To encode the time component we map the size of the points to the index, which is a global time-component (number of weeks since the first observation). Note that the fitted values do not seem to match the data. This model is too simple to capture the non-linear interactions.
ROAS and mROAS
Estimating the effect as above is very important. Nevertheless, one is mainly interested in certain return on investment metrics. Here we describe how to compute two common ones: ROAS (Return on Ad Spend) and mROAS (marginal ROAS) as described in Section 4.1 in the paper Bayesian Methods for Media Mix Modeling with Carryover and Shape Effects.
- ROAS
From the reference above:
ROAS is the change in revenue (or sales) per dollar spent on the medium; it is usually calculated by setting spend of the medium to zero in the selected time period and comparing the predicted revenue against that of the current media spend.
We can express this mathematically as:
\[ ROAS = \frac{\sum^{n}_{t=0}\hat{f}(z_{t}, \xi_{t}) - \hat{f}(0, \xi_{t})}{\sum^{n}_{t=0} z_{t}} \]
where \(\hat{f}(z_{t}, \xi_{t})\) represents the posterior predictive distribution (and \(\xi_t\) additional control variables) and \(\hat{f}(0, \xi_{t})\) represents the posterior predictive distribution when setting \(z=0\). There is a caveat with this formula however. One has to be careful about the pre/during/post computation periods because of the carryover effects. Here, for simplicity will do it for the whole time-range. For more details, please check the reference above.
In this specific example where we have an additive model we can compute the ROAS’ denominator as:
\[y - (y - z_{\text{effect}}) = z_{\text{effect}}\]
Note that this is not true for a multiplicative model (when for example you are applying log transform to the target variable).
Remark: Actually, the ROAS denominator is not precisely \(y - (y - z_{\text{effect}}) = z_{\text{effect}}\) since we still need to pass this through the normal likelihood function to properly compute the predictions of the whole model. Still, this will serve as a way to verify the results as we will be comparing the expected values.
# true roas for z
roas_true = data_df["z_effect"].sum() / data_df["z"].sum()
roas_true0.06620312360383751
Now we estimate it from the data and the model.
base_model_trace_roas = base_model_trace.copy()
with base_model:
pm.set_data(new_data={"z_scaled": np.zeros_like(a=z_scaled)})
base_model_trace_roas.extend(
other=pm.sample_posterior_predictive(trace=base_model_trace_roas, var_names=["likelihood"])
)base_roas_numerator = (
endog_scaler.inverse_transform(
X=az.extract(
data=base_model_posterior_predictive,
group="posterior_predictive",
var_names=["likelihood"],
)
)
- endog_scaler.inverse_transform(
X=az.extract(
data=base_model_trace_roas,
group="posterior_predictive",
var_names=["likelihood"],
)
)
).sum(axis=0)
roas_denominator = z.sum()
base_roas = base_roas_numerator / roas_denominatorbase_roas_mean = base_roas.mean()
base_roas_hdi = az.hdi(ary=base_roas)
g = sns.displot(x=base_roas, kde=True, height=5, aspect=1.5)
ax = g.axes.flatten()[0]
ax.axvline(
x=base_roas_mean, color="C0", linestyle="--", label=f"mean = {base_roas_mean: 0.3f}"
)
ax.axvline(
x=base_roas_hdi[0],
color="C1",
linestyle="--",
label=f"HDI_lwr = {base_roas_hdi[0]: 0.3f}",
)
ax.axvline(
x=base_roas_hdi[1],
color="C2",
linestyle="--",
label=f"HDI_upr = {base_roas_hdi[1]: 0.3f}",
)
ax.axvline(x=roas_true, color="black", linestyle="--", label=f"true = {roas_true: 0.3f}")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title="Base Model ROAS");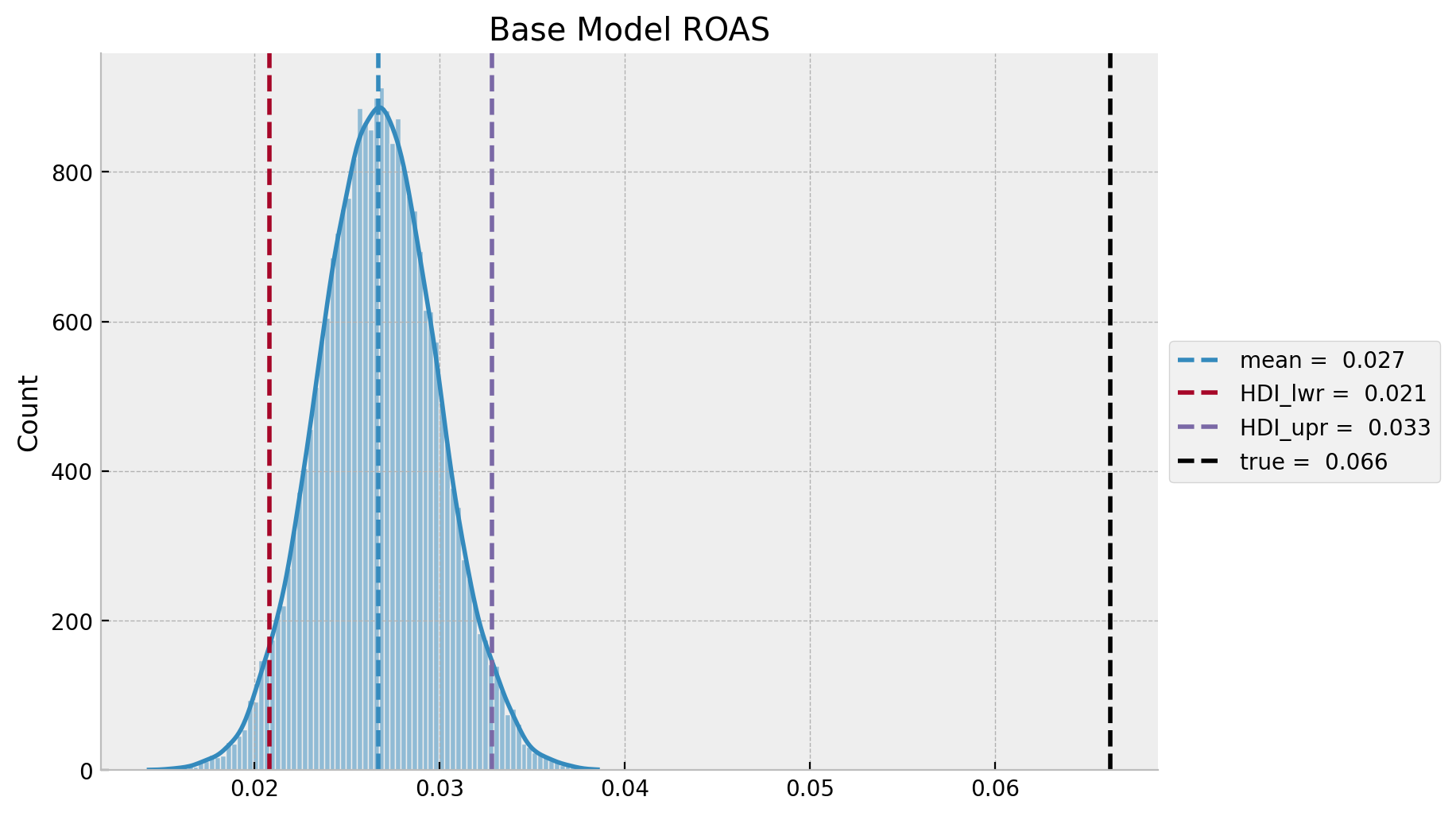
Observe that, as for the base model is under estimating the effect of \(z\) on \(y\), this translates into smaller predicted ROAS as compared to the true ROAS. This is consistent with the plot above.
- mROAS
mROAS for the m-th medium is the additional revenue generated by one-unit increase in spend, usually from the current spent level.
Let’s compute t by evaluating the a \(10\%\) increase in media spend \(z\) (we will leave the computation of the true mROAS for the next example).
eta: float = 0.10
base_model_trace_mroas = base_model_trace.copy()
with base_model:
pm.set_data(new_data={"z_scaled": (1 + eta) * z_scaled})
base_model_trace_mroas.extend(
other=pm.sample_posterior_predictive(trace=base_model_trace_mroas, var_names=["likelihood"])
)base_mroas_numerator = (
endog_scaler.inverse_transform(
X=az.extract(
data=base_model_trace_mroas,
group="posterior_predictive",
var_names=["likelihood"],
)
)
- endog_scaler.inverse_transform(
X=az.extract(
data=base_model_posterior_predictive,
group="posterior_predictive",
var_names=["likelihood"],
)
)
).sum(axis=0)
mroas_denominator = eta * z.sum()
base_mroas = base_mroas_numerator / mroas_denominator
base_mroas_mean = base_mroas.mean()
base_mroas_hdi = az.hdi(ary=base_mroas)
g = sns.displot(x=base_mroas, kde=True, height=5, aspect=1.5)
ax = g.axes.flatten()[0]
ax.axvline(
x=base_mroas_mean, color="C0", linestyle="--", label=f"mean = {base_mroas_mean: 0.3f}"
)
ax.axvline(
x=base_mroas_hdi[0],
color="C1",
linestyle="--",
label=f"HDI_lwr = {base_mroas_hdi[0]: 0.3f}",
)
ax.axvline(
x=base_mroas_hdi[1],
color="C2",
linestyle="--",
label=f"HDI_upr = {base_roas_hdi[1]: 0.3f}",
)
ax.axvline(x=0.0, color="gray", linestyle="--", label="zero")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title=f"Base Model MROAS ({eta:.0%} increase)");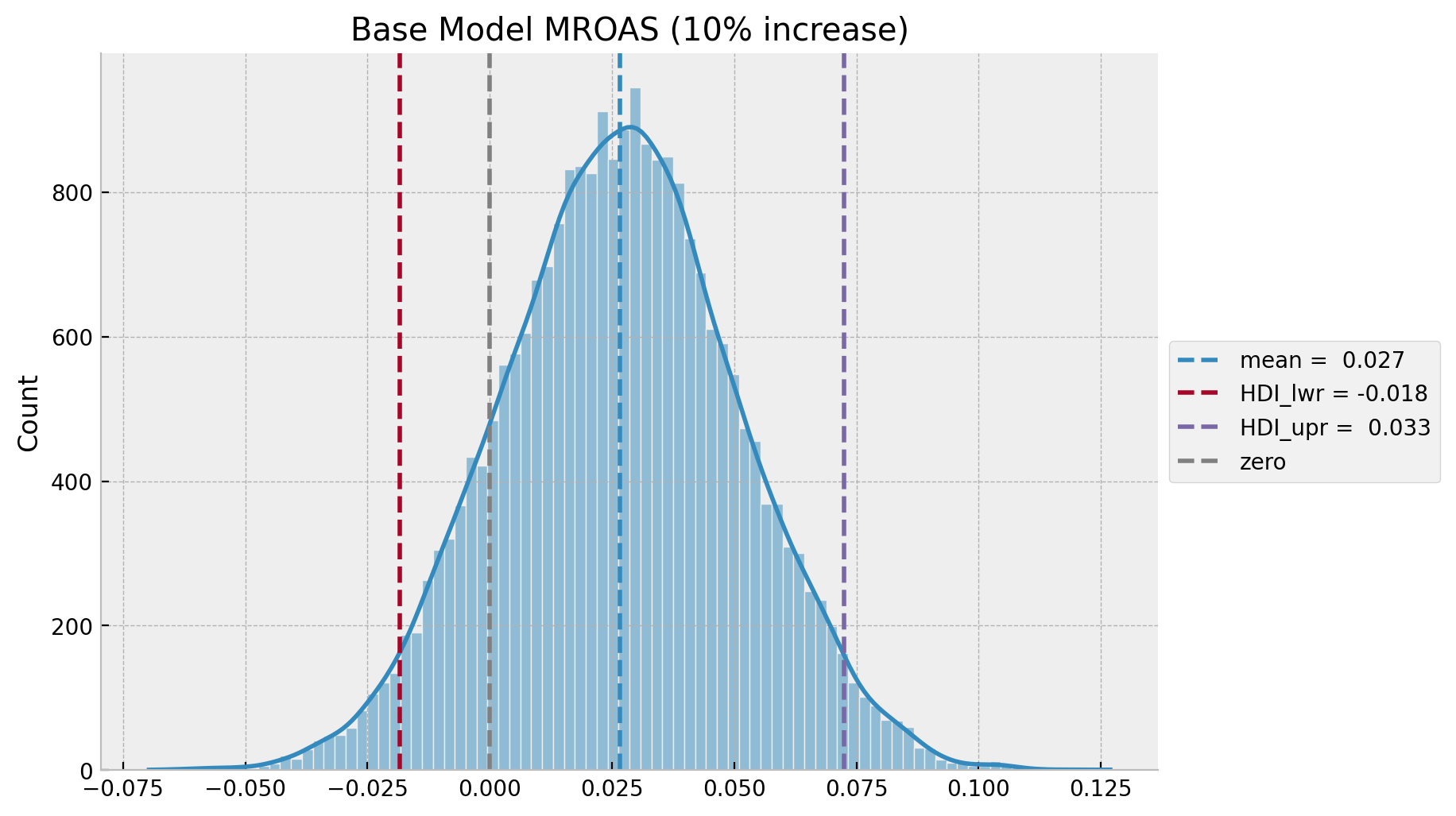
Adstock-Saturation Model
- Features
For the second model we need to express the (geometric) adstock and saturation transformations as tensor operations:
def geometric_adstock(x, alpha: float = 0.0, l_max: int = 12):
"""Geometric adstock transformation."""
cycles = [
pt.concatenate(
[pt.zeros(i), x[: x.shape[0] - i]]
)
for i in range(l_max)
]
x_cycle = pt.stack(cycles)
w = pt.as_tensor_variable([pt.power(alpha, i) for i in range(l_max)])
return pt.dot(w, x_cycle)
def logistic_saturation(x, lam: float = 0.5):
"""Logistic saturation transformation."""
return (1 - pt.exp(-lam * x)) / (1 + pt.exp(-lam * x))- Model Specification
As we want \(\alpha\) to be in the interval \((0, 1)\) we use a Beta distribution. Moreover, we choose \(\alpha \sim \text{Beta}(1, 1) = \text{Uniform}(0, 1)\) as prior. For \(\lambda\) we use a \(\text{Gamma}\) distribution as this parameters has to be positive.
with pm.Model(coords=coords) as adstock_saturation_model:
# --- data containers ---
z_scaled_ = pm.MutableData(name="z_scaled", value=z_scaled, dims="date")
# --- priors ---
## intercept
a = pm.Normal(name="a", mu=0, sigma=4)
## trend
b_trend = pm.Normal(name="b_trend", mu=0, sigma=2)
## seasonality
b_fourier = pm.Laplace(name="b_fourier", mu=0, b=2, dims="fourier_mode")
## adstock effect
alpha = pm.Beta(name="alpha", alpha=1, beta=1)
## saturation effect
lam = pm.Gamma(name="lam", alpha=3, beta=1)
## regressor
b_z = pm.HalfNormal(name="b_z", sigma=2)
## standard deviation of the normal likelihood
sigma = pm.HalfNormal(name="sigma", sigma=0.5)
# degrees of freedom of the t distribution
nu = pm.Gamma(name="nu", alpha=25, beta=2)
# --- model parametrization ---
trend = pm.Deterministic("trend", a + b_trend * t, dims="date")
seasonality = pm.Deterministic(
name="seasonality", var=pm.math.dot(fourier_features, b_fourier), dims="date"
)
z_adstock = pm.Deterministic(
name="z_adstock", var=geometric_adstock(x=z_scaled_, alpha=alpha, l_max=12), dims="date"
)
z_adstock_saturated = pm.Deterministic(
name="z_adstock_saturated",
var=logistic_saturation(x=z_adstock, lam=lam),
dims="date",
)
z_effect = pm.Deterministic(
name="z_effect", var=b_z * z_adstock_saturated, dims="date"
)
mu = pm.Deterministic(name="mu", var=trend + seasonality + z_effect, dims="date")
# --- likelihood ---
pm.StudentT(name="likelihood", nu=nu, mu=mu, sigma=sigma, observed=y_scaled, dims="date")
# --- prior samples
adstock_saturation_model_prior_predictive = pm.sample_prior_predictive()
pm.model_to_graphviz(model=adstock_saturation_model)
- Prior Predictive Samples
fig, ax = plt.subplots()
for i, p in enumerate(percs[::-1]):
upper = np.percentile(
adstock_saturation_model_prior_predictive.prior_predictive["likelihood"],
p,
axis=1,
)
lower = np.percentile(
adstock_saturation_model_prior_predictive.prior_predictive["likelihood"], 100 - p, axis=1
)
color_val = colors[i]
ax.fill_between(
x=date,
y1=upper.flatten(),
y2=lower.flatten(),
color=cmap(color_val),
alpha=0.1,
)
sns.lineplot(x=date, y=y_scaled, color="black", label="target (scaled)", ax=ax)
ax.legend()
ax.set(title="Adstock Saturation Model - Prior Predictive");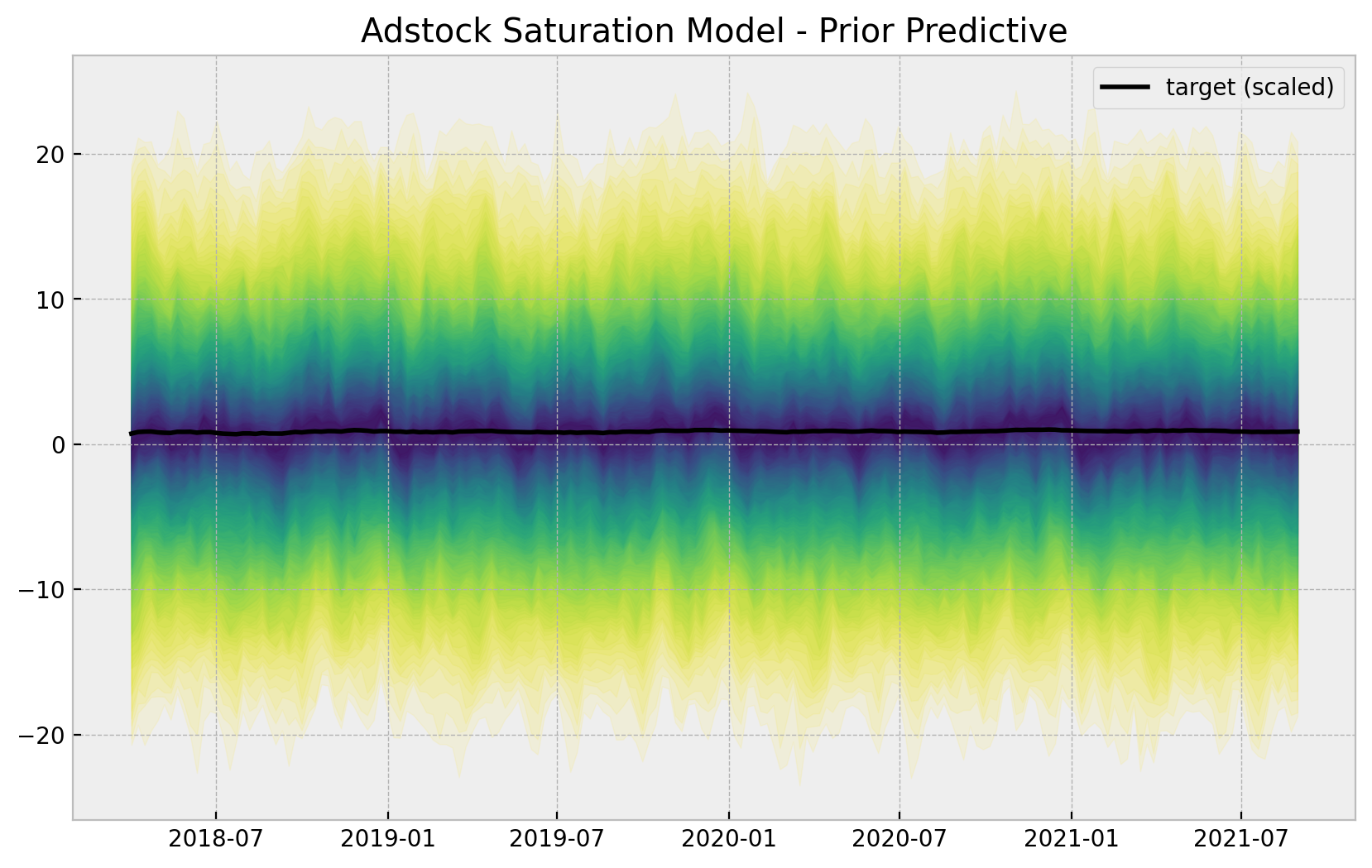
- Fit Model
with adstock_saturation_model:
adstock_saturation_model_trace = pm.sample(
nuts_sampler="numpyro",
draws=6_000,
chains=4,
idata_kwargs={"log_likelihood": True},
)
adstock_saturation_model_posterior_predictive = pm.sample_posterior_predictive(
trace=adstock_saturation_model_trace,
)- Model Diagnostics
az.summary(
data=adstock_saturation_model_trace,
var_names=["a", "b_trend", "b_z", "alpha", "lam", "sigma", "nu"]
)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a | 0.752 | 0.007 | 0.740 | 0.764 | 0.000 | 0.000 | 6114.0 | 9188.0 | 1.0 |
| b_trend | 0.117 | 0.003 | 0.111 | 0.124 | 0.000 | 0.000 | 16428.0 | 16438.0 | 1.0 |
| b_z | 0.119 | 0.025 | 0.091 | 0.146 | 0.001 | 0.000 | 4275.0 | 3289.0 | 1.0 |
| alpha | 0.531 | 0.035 | 0.465 | 0.595 | 0.000 | 0.000 | 7054.0 | 10414.0 | 1.0 |
| lam | 1.332 | 0.286 | 0.787 | 1.866 | 0.005 | 0.003 | 4289.0 | 3146.0 | 1.0 |
| sigma | 0.012 | 0.001 | 0.010 | 0.013 | 0.000 | 0.000 | 8559.0 | 12215.0 | 1.0 |
| nu | 13.300 | 2.461 | 8.934 | 18.128 | 0.026 | 0.018 | 8892.0 | 10523.0 | 1.0 |
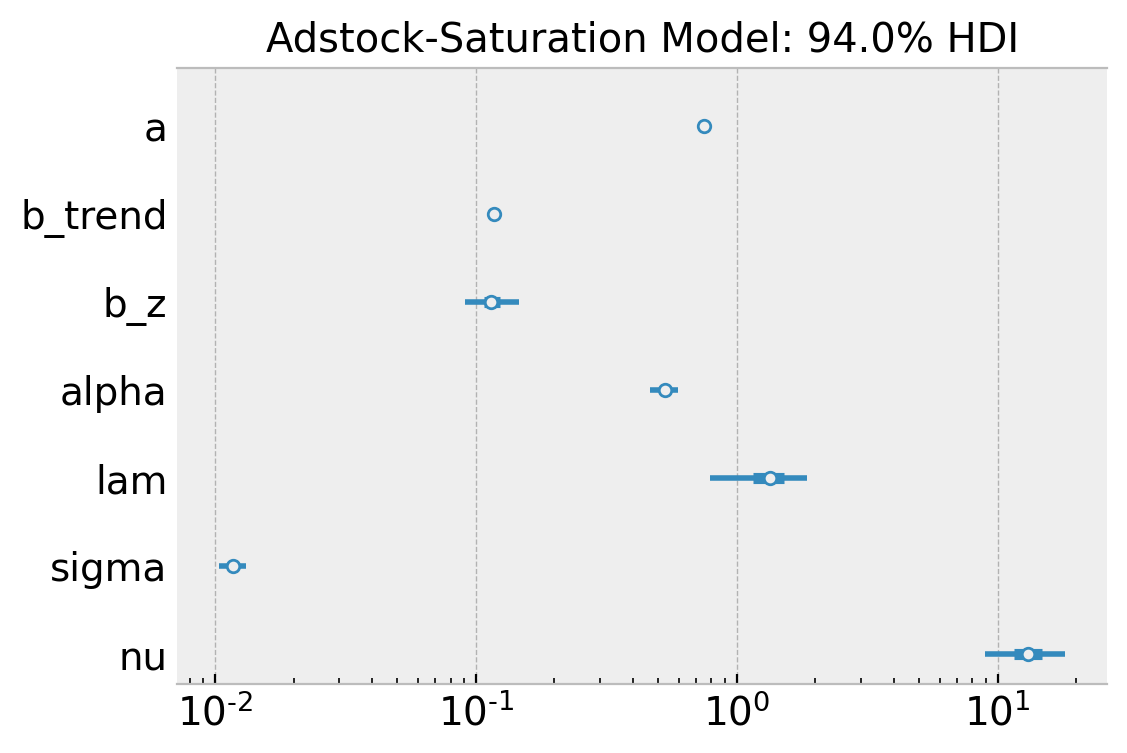
We will see later that the values of \(\alpha\) and \(\lambda\) are very close to the true ones (\(0.5\) and \(0.15\) respectively) up to a scale defined by the channel scaler. Moreover, the true values (up to this scale) are included in the posterior distributions \(94\%\) HDI.
axes = az.plot_trace(
data=adstock_saturation_model_trace,
var_names=["a", "b_trend", "b_fourier", "b_z", "alpha", "lam", "sigma", "nu"],
compact=True,
backend_kwargs={
"figsize": (12, 12),
"layout": "constrained"
},
)
fig = axes[0][0].get_figure()
fig.suptitle("Adstock-Saturation Model - Trace");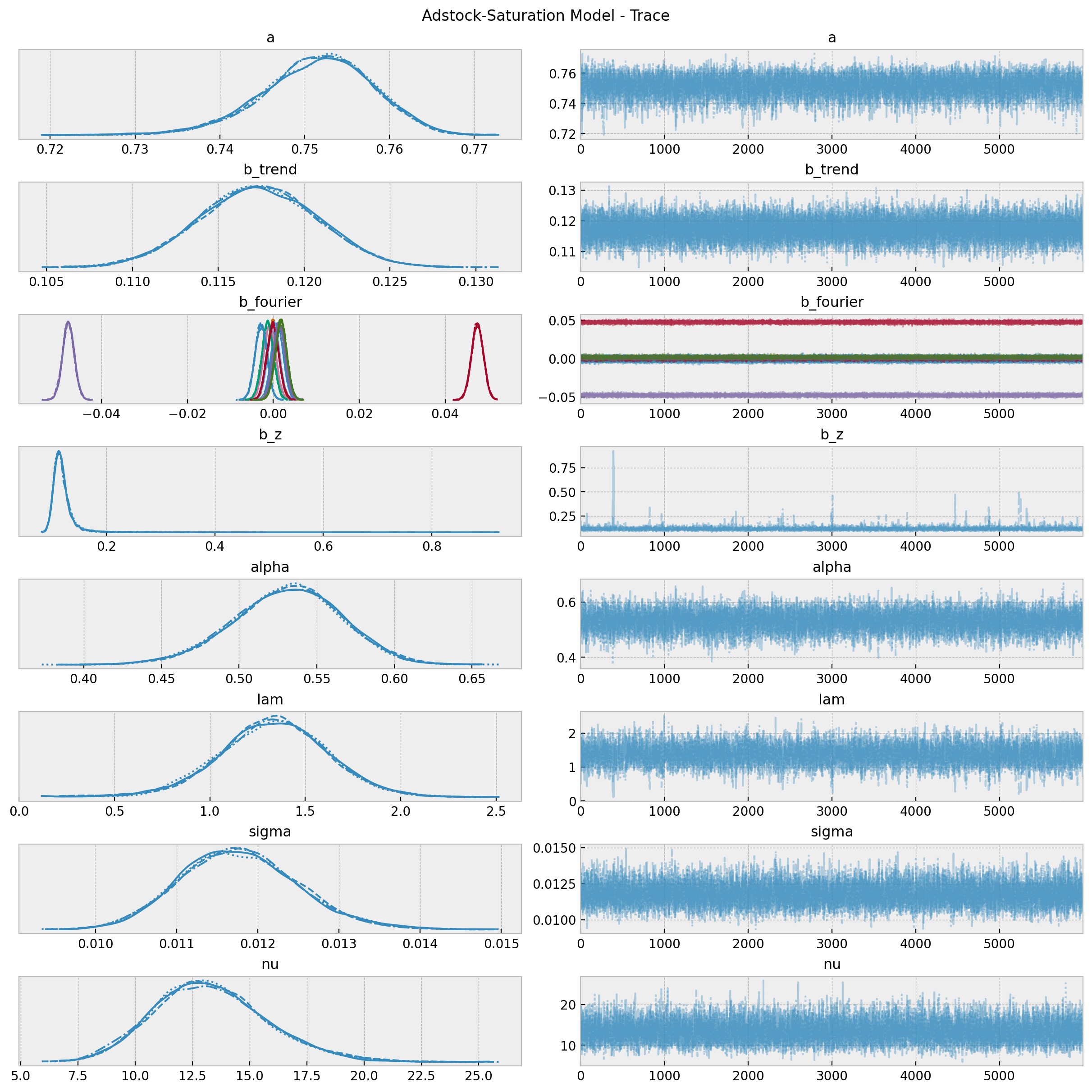
fig, ax = plt.subplots(figsize=(6, 4))
az.plot_forest(
data=adstock_saturation_model_trace,
var_names=["a", "b_trend", "b_z", "alpha", "lam", "sigma", "nu"],
combined=True,
ax=ax
)
ax.set(
title="Adstock-Saturation Model: 94.0% HDI",
xscale="log"
);
- Posterior Predictive Samples
posterior_predictive_likelihood = az.extract(
data=adstock_saturation_model_posterior_predictive,
group="posterior_predictive",
var_names="likelihood",
)
posterior_predictive_likelihood_inv = endog_scaler.inverse_transform(
X=posterior_predictive_likelihood
)
fig, ax = plt.subplots()
for i, p in enumerate(percs[::-1]):
upper = np.percentile(posterior_predictive_likelihood_inv, p, axis=1)
lower = np.percentile(posterior_predictive_likelihood_inv, 100 - p, axis=1)
color_val = colors[i]
ax.fill_between(
x=date,
y1=upper,
y2=lower,
color=cmap(color_val),
alpha=0.1,
)
sns.lineplot(
x=date,
y=posterior_predictive_likelihood_inv.mean(axis=1),
color="C2",
label="posterior predictive mean",
ax=ax,
)
sns.lineplot(
x=date,
y=y,
color="black",
label="target",
ax=ax,
)
ax.legend(loc="upper left")
ax.set(title="Adstock-Saturation Model - Posterior Predictive Samples");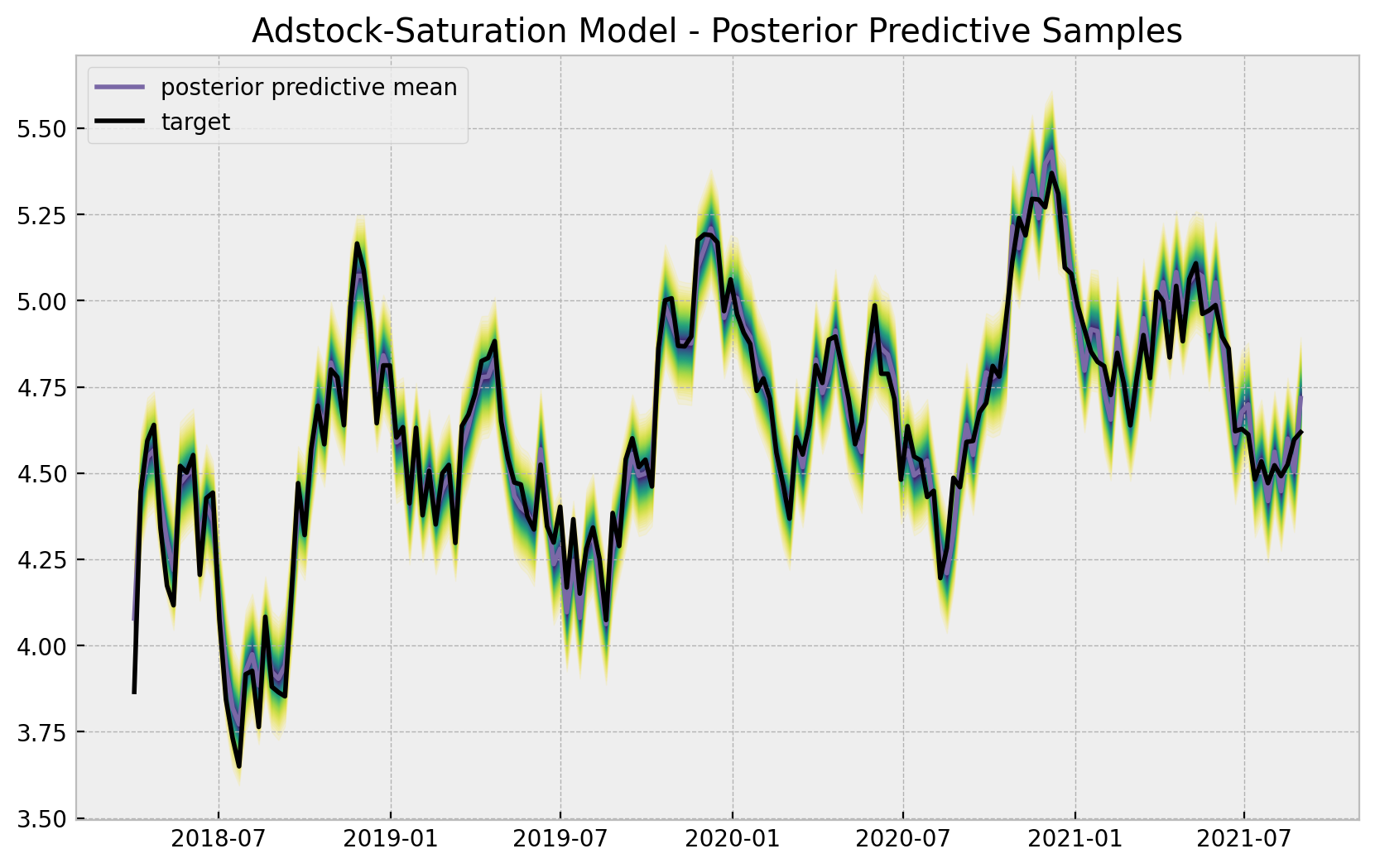
# compute HDI for all the model parameters
model_hdi = az.hdi(ary=adstock_saturation_model_trace)
fig, ax = plt.subplots()
for i, var_effect in enumerate(["z_effect", "trend", "seasonality"]):
ax.fill_between(
x=date,
y1=model_hdi[var_effect][:, 0],
y2=model_hdi[var_effect][:, 1],
color=f"C{i}",
alpha=0.3,
label=f"$94\%$ HDI ({var_effect})",
)
sns.lineplot(
x=date,
y=adstock_saturation_model_trace.posterior[var_effect]
.stack(sample=("chain", "draw"))
.mean(axis=1),
color=f"C{i}",
)
sns.lineplot(x=date, y=y_scaled, color="black", alpha=1.0, label="target (scaled)", ax=ax)
ax.legend(title="components", loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title="Adstock-Saturation Model Components", ylabel="target (scaled)");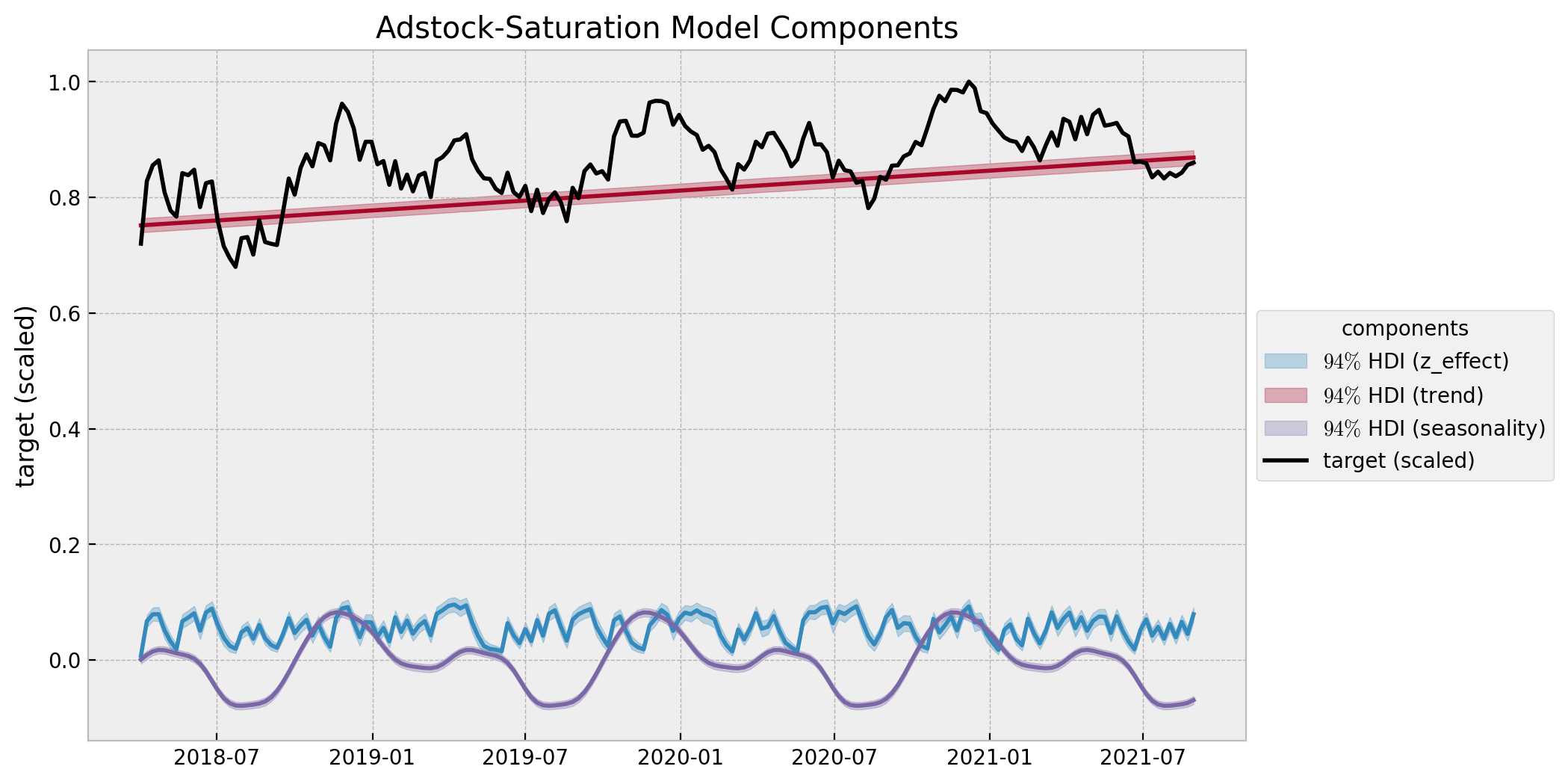
- Estimated
z_effect
z_effect_posterior_samples = xr.apply_ufunc(
lambda x: endog_scaler.inverse_transform(X=x.reshape(1, -1)),
adstock_saturation_model_trace.posterior["z_effect"],
input_core_dims=[["date"]],
output_core_dims=[["date"]],
vectorize=True,
)
z_effect_hdi = az.hdi(ary=z_effect_posterior_samples)["z_effect"]
fig, ax = plt.subplots()
ax.fill_between(
x=date,
y1=z_effect_hdi[:, 0],
y2=z_effect_hdi[:, 1],
color="C0",
alpha=0.5,
label="z_effect 94% HDI",
)
ax.axhline(
y=z_effect_posterior_samples.mean(),
color="C0",
linestyle="--",
label=f"posterior mean {z_effect_posterior_samples.mean().values: 0.3f}",
)
sns.lineplot(x="date", y="z_effect", color="C3", data=data_df, label="z_effect", ax=ax)
ax.legend(loc="upper right")
ax.set(title="Media Cost Effect on Sales Estimation - Adstock-Saturation");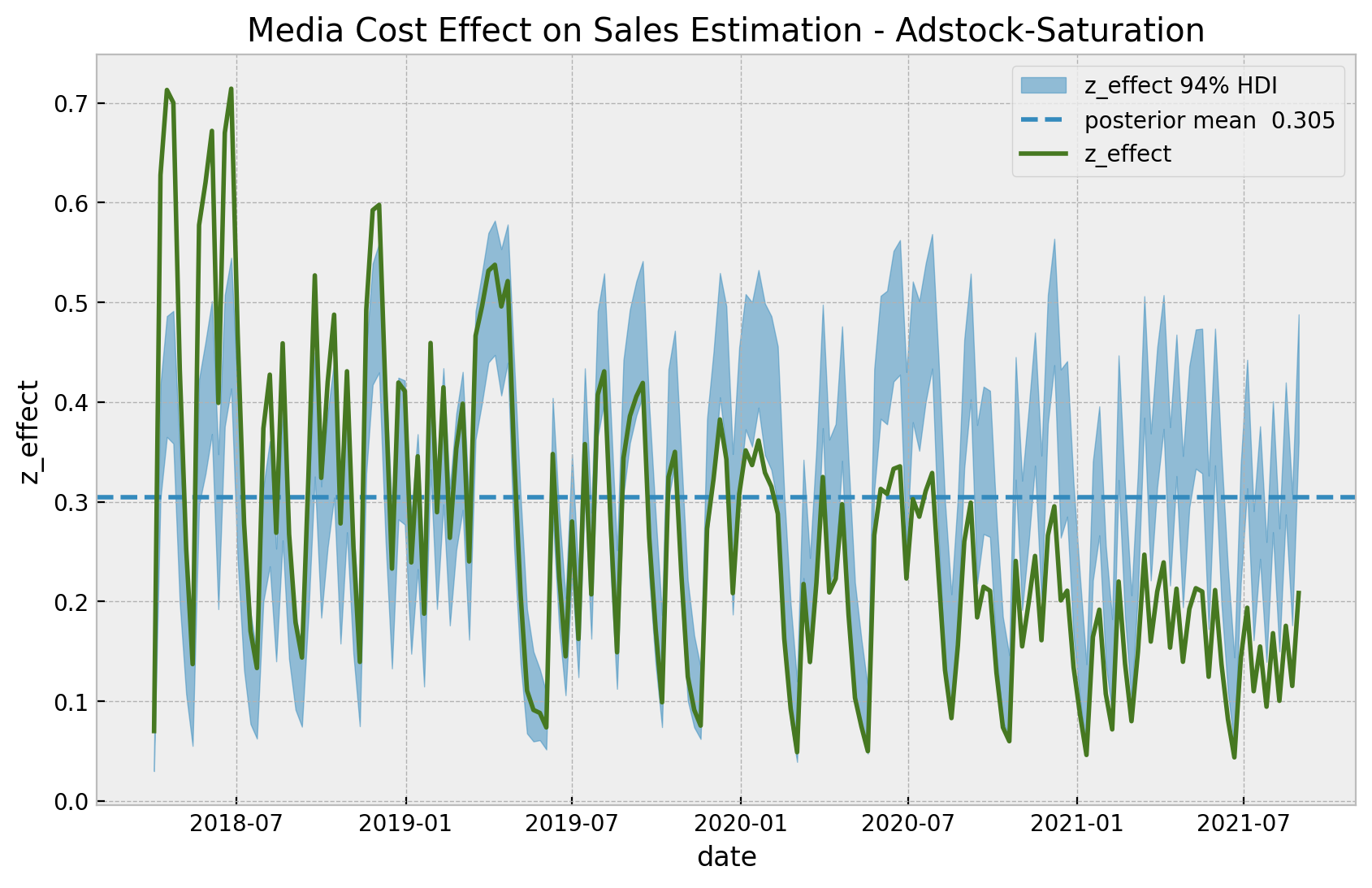
This model captures more variance in the effect of z than the base model. This shows that the adstock and saturation transformations do make the difference. Note however that the diminishing returns effect is not present in this model, as the regression coefficient is not time-varying.
We continue by looking into the estimated against the true values for this adstock-saturation model. We would expect to find a non-linear patter because of the composition of these two transformations.
fig, ax = plt.subplots()
az.plot_hdi(
x=z,
y=z_effect_posterior_samples,
color="C0",
fill_kwargs={"alpha": 0.2, "label": "z_effect 94% HDI"},
ax=ax,
)
sns.scatterplot(
x="z",
y="z_effect_pred_mean",
color="C0",
size="index",
label="z_effect (pred mean)",
data=data_df.assign(
z_effect_pred_mean=z_effect_posterior_samples.mean(dim=("chain", "draw"))
),
ax=ax,
)
sns.scatterplot(
x="z",
y="z_effect",
color="C3",
size="index",
label="z_effect (true)",
data=data_df,
ax=ax,
)
h, l = ax.get_legend_handles_labels()
ax.legend(handles=h[:9], labels=l[:9], loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title="Adstock-Saturation Model - Estimated Effect");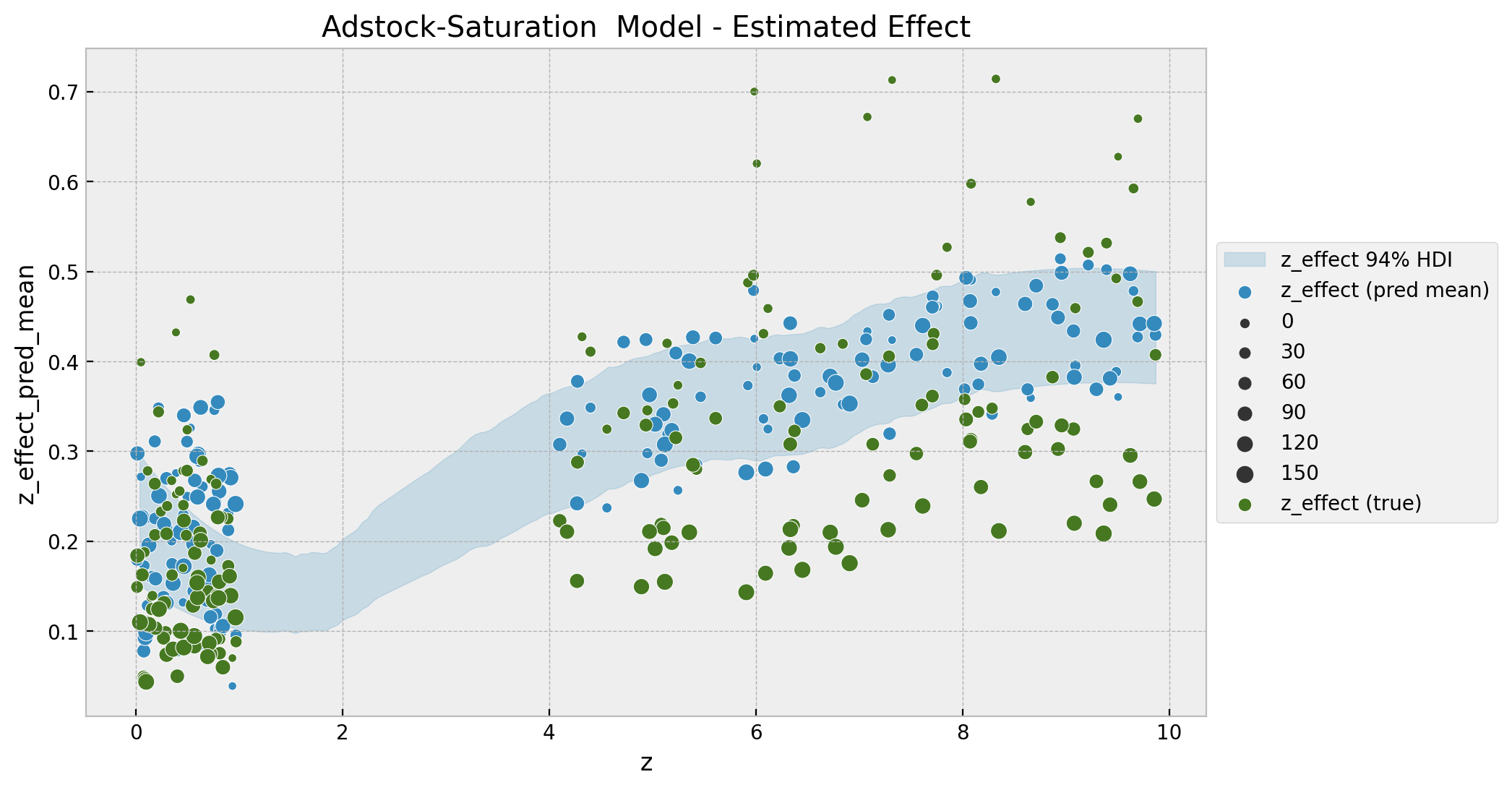
As for the base-model, we encode the time component as the size of the points. Note that we indeed see a better fit and a non-linear pattern. For low values of z the effect seems constant whereas for larger values we see a non-linear pattern which saturates as expected.
We will deep-dive in the adstock and saturation transformations in the next example.
Remark: One can easily vectorize the adstock transformation above to include various channels without using a for loop. Namely,
def geometric_adstock_vectorized(x, alpha, l_max: int = 12):
"""Vectorized geometric adstock transformation."""
cycles = [
pt.concatenate(tensor_list=[pt.zeros(shape=x.shape)[:i], x[: x.shape[0] - i]])
for i in range(l_max)
]
x_cycle = pt.stack(cycles)
x_cycle = pt.transpose(x=x_cycle, axes=[1, 2, 0])
w = pt.as_tensor_variable([pt.power(alpha, i) for i in range(l_max)])
w = pt.transpose(w)[None, ...]
return pt.sum(pt.mul(x_cycle, w), axis=2)Here alpha is a tensor where each dimension corresponds to a channel. Moreover, one can normalize the weights as
w / pt.sum(w, axis=2, keepdims=True)ROAS and mROAS
- ROAS
adstock_saturation_model_trace_roas = adstock_saturation_model_trace.copy()
with adstock_saturation_model:
pm.set_data(new_data={"z_scaled": np.zeros_like(a=z_scaled)})
adstock_saturation_model_trace_roas.extend(
other=pm.sample_posterior_predictive(trace=adstock_saturation_model_trace_roas, var_names=["likelihood"])
)adstock_saturation_roas_numerator = (
endog_scaler.inverse_transform(
X=az.extract(
data=adstock_saturation_model_posterior_predictive,
group="posterior_predictive",
var_names=["likelihood"],
)
)
- endog_scaler.inverse_transform(
X=az.extract(
data=adstock_saturation_model_trace_roas,
group="posterior_predictive",
var_names=["likelihood"],
)
)
).sum(axis=0)
roas_denominator = z.sum()
adstock_saturation_roas = adstock_saturation_roas_numerator / roas_denominatoradstock_saturation_roas_mean = adstock_saturation_roas.mean()
adstock_saturation_roas_hdi = az.hdi(ary=adstock_saturation_roas)
g = sns.displot(x=adstock_saturation_roas, kde=True, height=5, aspect=1.5)
ax = g.axes.flatten()[0]
ax.axvline(
x=adstock_saturation_roas_mean, color="C0", linestyle="--", label=f"mean = {adstock_saturation_roas_mean: 0.3f}"
)
ax.axvline(
x=adstock_saturation_roas_hdi[0],
color="C1",
linestyle="--",
label=f"HDI_lwr = {adstock_saturation_roas_hdi[0]: 0.3f}",
)
ax.axvline(
x=adstock_saturation_roas_hdi[1],
color="C2",
linestyle="--",
label=f"HDI_upr = {adstock_saturation_roas_hdi[1]: 0.3f}",
)
ax.axvline(x=roas_true, color="black", linestyle="--", label=f"true = {roas_true: 0.3f}")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title="Adstock Saturation Model ROAS");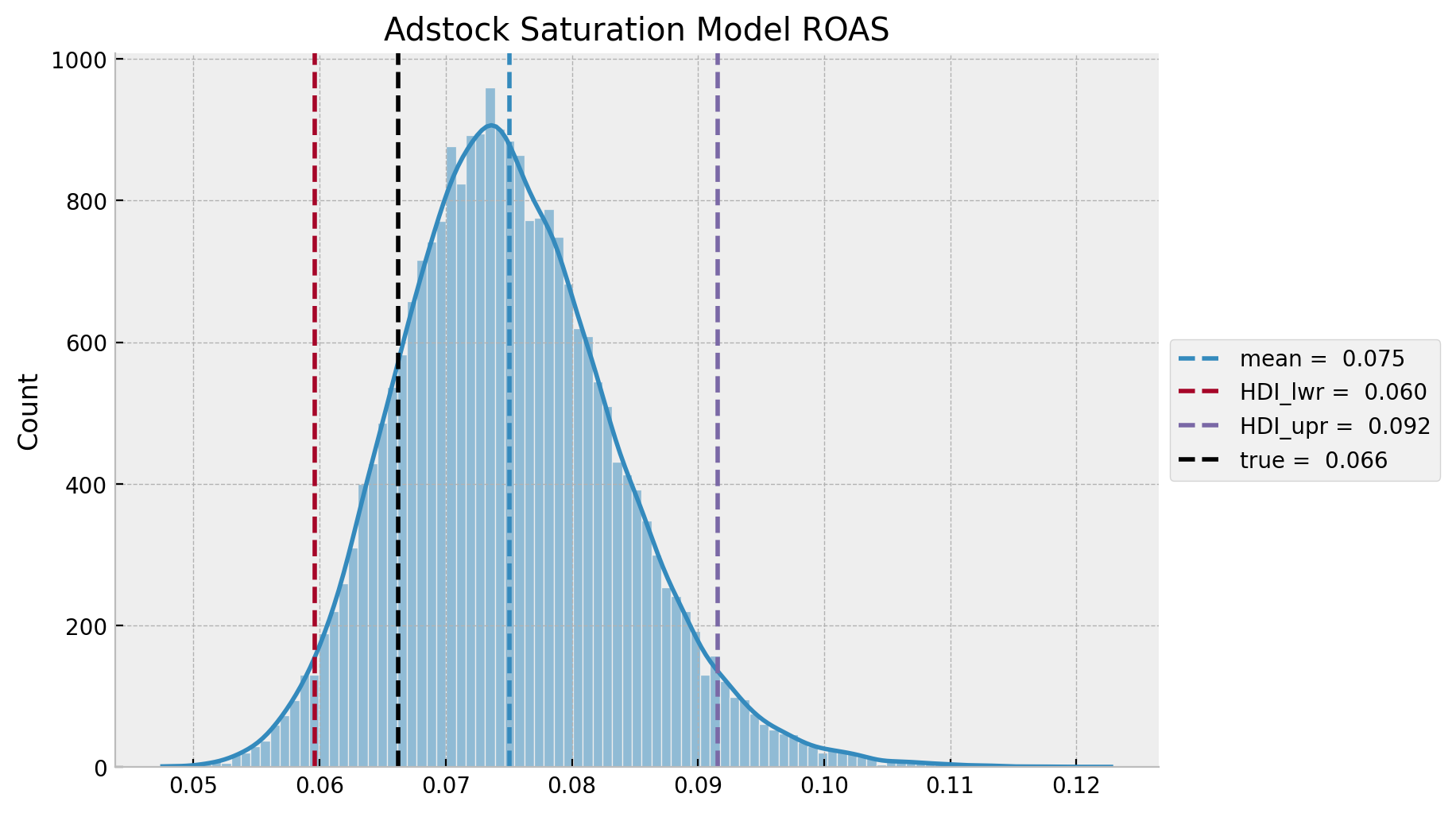
In this case, as for the adstock saturation model is over estimating the effect of \(z\) on \(y\), this translates into a smaller predicted ROAS as compared to the true ROAS.
- mROAS
Let’s compute the true mROAS. We first need to estimate the effect of \(z\) on \(y\) by increasing it by \(10%\) and then pushing it through the data transformations using the true values of the parameters (see the blog post (Media Effect Estimation with Orbit’s KTR Model)[https://juanitorduz.github.io/orbit_mmm/] to see the data generation process). Then we subtract the initial effect (again, note that this just works for additive models!).
b_z_true = (np.arange(start=0.0, stop=1.0, step=1/n_obs) + 1) ** (-1.8)
z_effect_eta = b_z_true * logistic_saturation(
x=geometric_adstock(x=(1 + eta) * z, alpha=0.5, l_max=12),
lam=0.15
).eval()
mroas_true = (z_effect_eta - data_df["z_effect"]).sum() / ( eta * z.sum())
mroas_true0.045259246530653344
Now, let use compute it from the model.
eta: float = 0.10
adstock_saturation_model_trace_mroas = adstock_saturation_model_trace.copy()
with adstock_saturation_model:
pm.set_data(new_data={"z_scaled": (1 + eta) * z_scaled})
adstock_saturation_model_trace_mroas.extend(
other=pm.sample_posterior_predictive(trace=adstock_saturation_model_trace_mroas, var_names=["likelihood"])
)adstock_saturation_mroas_numerator = (
endog_scaler.inverse_transform(
X=az.extract(
data=adstock_saturation_model_trace_mroas,
group="posterior_predictive",
var_names=["likelihood"],
)
)
- endog_scaler.inverse_transform(
X=az.extract(
data=adstock_saturation_model_posterior_predictive,
group="posterior_predictive",
var_names=["likelihood"],
)
)
).sum(axis=0)
mroas_denominator = eta * z.sum()
adstock_saturation_mroas = adstock_saturation_mroas_numerator / mroas_denominatoradstock_saturation_mroas_mean = adstock_saturation_mroas.mean()
adstock_saturation_mroas_hdi = az.hdi(ary=adstock_saturation_mroas)
g = sns.displot(x=adstock_saturation_mroas, kde=True, height=5, aspect=1.5)
ax = g.axes.flatten()[0]
ax.axvline(
x=adstock_saturation_mroas_mean, color="C0", linestyle="--", label=f"mean = {adstock_saturation_mroas_mean: 0.3f}"
)
ax.axvline(
x=adstock_saturation_mroas_hdi[0],
color="C1",
linestyle="--",
label=f"HDI_lwr = {adstock_saturation_mroas_hdi[0]: 0.3f}",
)
ax.axvline(
x=adstock_saturation_mroas_hdi[1],
color="C2",
linestyle="--",
label=f"HDI_upr = {adstock_saturation_roas_hdi[1]: 0.3f}",
)
ax.axvline(x=mroas_true, color="black", linestyle="--", label=f"true = {roas_true: 0.3f}")
ax.axvline(x=0.0, color="gray", linestyle="--", label="zero")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title=f"Adstock Saturation Model MROAS ({eta:.0%} increase)");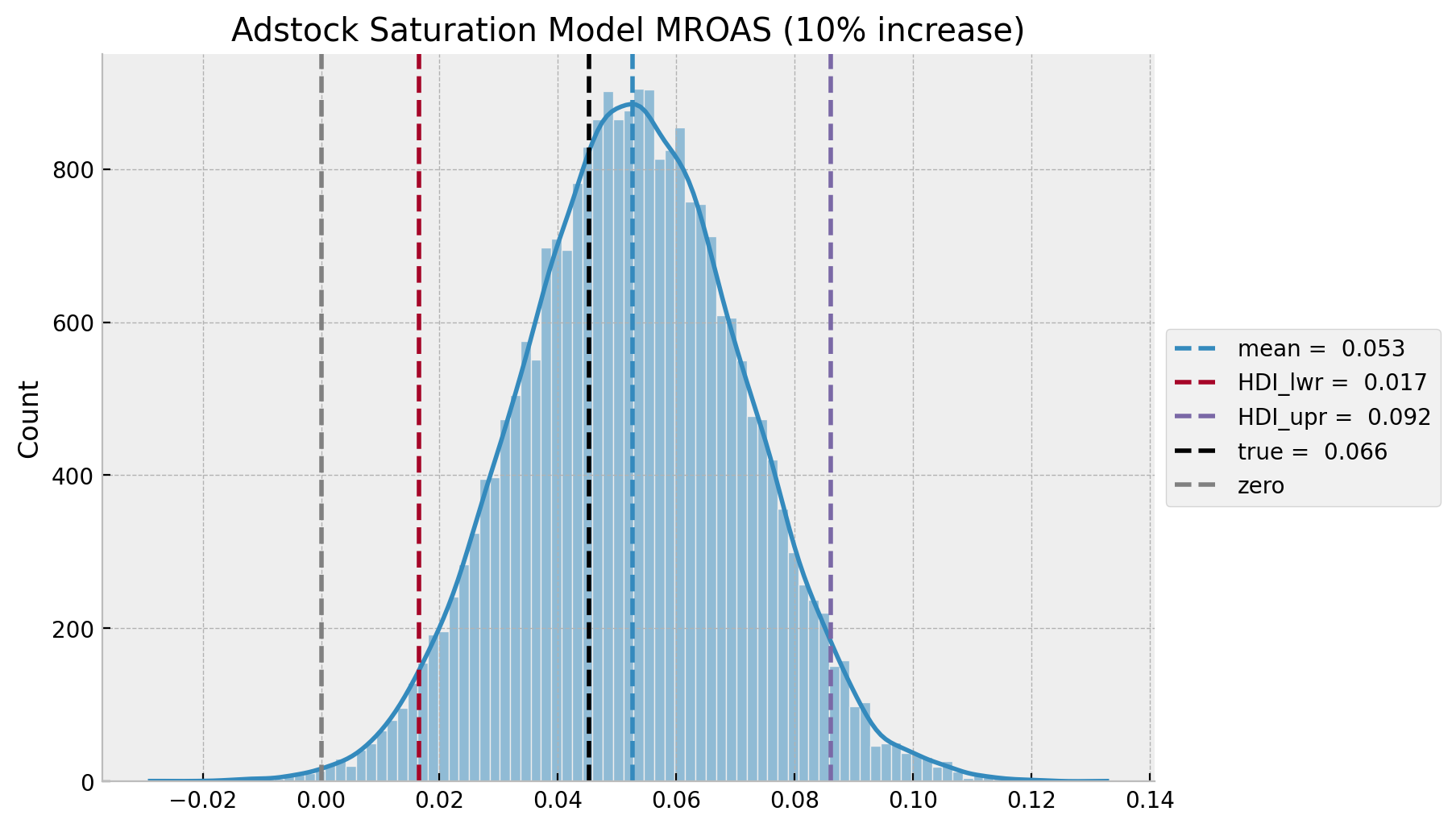
Adstock-Saturation-Diminishing-Returns (ASDR) Model
In this final model we add a time-varying coefficient for the adstock and saturation transformations (plus controlling for the trend and seasonality). Note that, we ensure the time varying coefficients are all positive by adding an exp transformation to the output of the Gaussian random walk.
- Model Specification
with pm.Model(coords=coords) as asdr_model:
# --- data containers ---
z_scaled_ = pm.MutableData(name="z_scaled", value=z_scaled, dims="date")
# --- priors ---
## intercept
a = pm.Normal(name="a", mu=0, sigma=4)
## trend
b_trend = pm.Normal(name="b_trend", mu=0, sigma=2)
## seasonality
b_fourier = pm.Laplace(name="b_fourier", mu=0, b=2, dims="fourier_mode")
## adstock effect
alpha = pm.Beta(name="alpha", alpha=1, beta=1)
## saturation effect
lam = pm.Gamma(name="lam", alpha=1, beta=1)
## gaussian random walk standard deviation
sigma_slope = pm.HalfNormal(name="sigma_slope", sigma=0.05)
## standard deviation of the normal likelihood
sigma = pm.HalfNormal(name="sigma", sigma=0.5)
# degrees of freedom of the t distribution
nu = pm.Gamma(name="nu", alpha=10, beta=1)
# --- model parametrization ---
trend = pm.Deterministic(name="trend", var=a + b_trend * t, dims="date")
seasonality = pm.Deterministic(
name="seasonality", var=pm.math.dot(fourier_features, b_fourier), dims="date"
)
slopes = pm.GaussianRandomWalk(
name="slopes",
sigma=sigma_slope,
init_dist=pm.distributions.continuous.Normal.dist(
name="init_dist", mu=0, sigma=2
),
dims="date",
)
z_adstock = pm.Deterministic(
name="z_adstock", var=geometric_adstock(x=z_scaled_, alpha=alpha, l_max=12), dims="date"
)
z_adstock_saturated = pm.Deterministic(
name="z_adstock_saturated",
var=logistic_saturation(x=z_adstock, lam=lam),
dims="date",
)
z_effect = pm.Deterministic(
name="z_effect", var=pm.math.exp(slopes) * z_adstock_saturated, dims="date"
)
mu = pm.Deterministic(name="mu", var=trend + seasonality + z_effect, dims="date")
# --- likelihood ---
pm.StudentT(name="likelihood", nu=nu, mu=mu, sigma=sigma, observed=y_scaled, dims="date")
# --- prior samples ---
asdr_model_prior_predictive = pm.sample_prior_predictive()
pm.model_to_graphviz(model=asdr_model)
fig, ax = plt.subplots()
for i, p in enumerate(percs[::-1]):
upper = np.percentile(
asdr_model_prior_predictive.prior_predictive["likelihood"],
p,
axis=1,
)
lower = np.percentile(
asdr_model_prior_predictive.prior_predictive["likelihood"], 100 - p, axis=1
)
color_val = colors[i]
ax.fill_between(
x=date,
y1=upper.flatten(),
y2=lower.flatten(),
color=cmap(color_val),
alpha=0.1,
)
sns.lineplot(x=date, y=y_scaled, color="black", label="target (scaled)", ax=ax)
ax.legend()
ax.set(title="Adstock-Saturation-Diminishing-Returns Model - Prior Predictive Samples");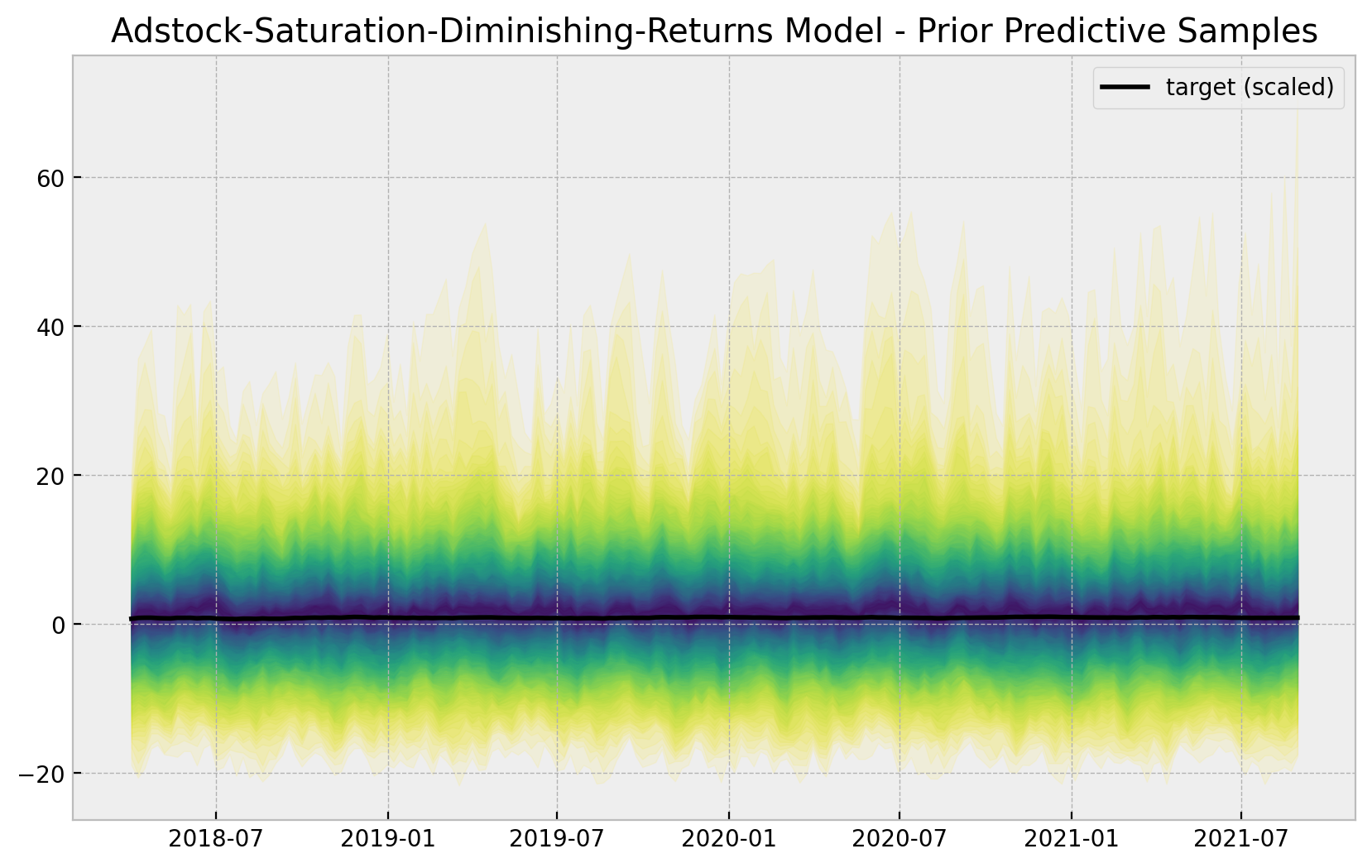
- Model Fit
with asdr_model:
asdr_model_trace = pm.sample(
nuts_sampler="numpyro",
draws=6_000,
chains=4,
idata_kwargs={"log_likelihood": True},
)
asdr_model_posterior_predictive = pm.sample_posterior_predictive(
trace=asdr_model_trace
)- Model Diagnostics
az.summary(
data=asdr_model_trace,
var_names=["a", "b_trend", "sigma_slope", "alpha", "lam", "sigma", "nu"]
)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
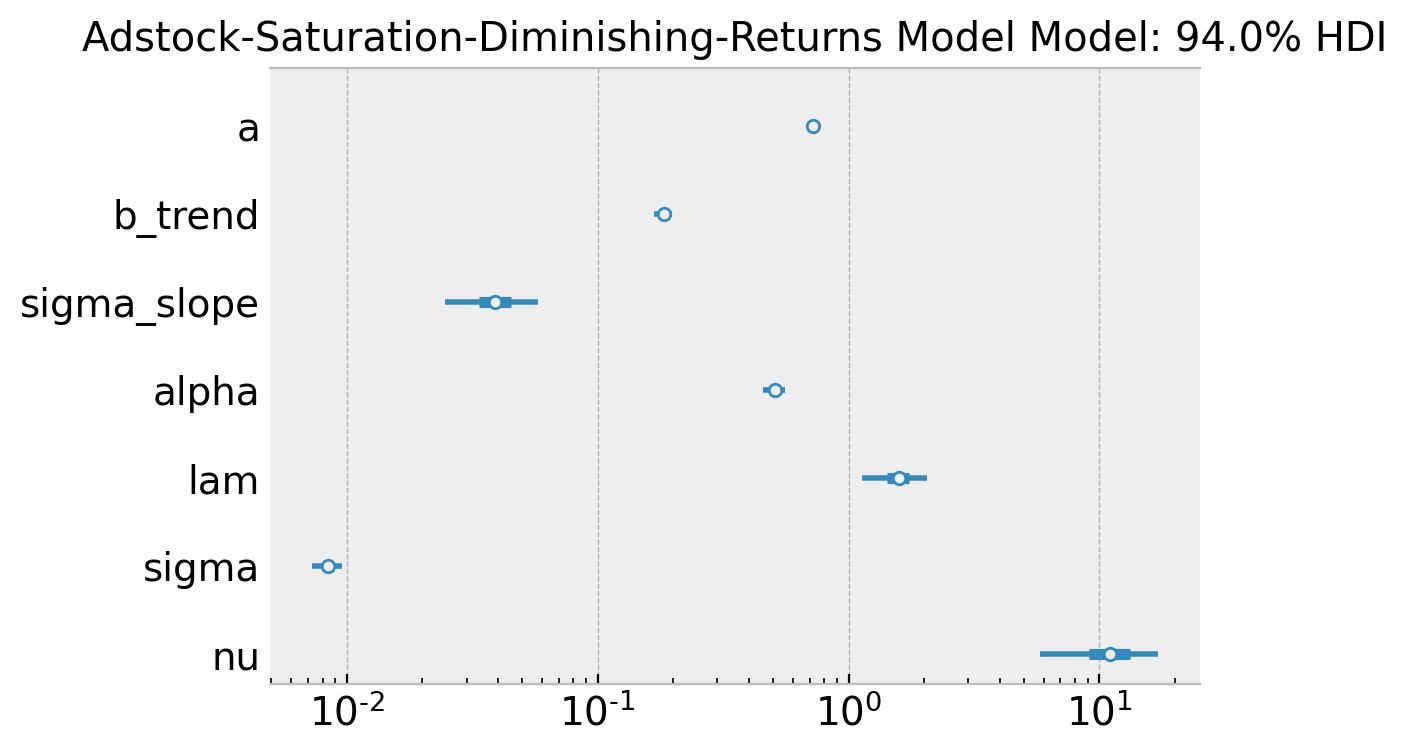
| a | 0.720 | 0.006 | 0.708 | 0.732 | 0.000 | 0.000 | 11466.0 | 15495.0 | 1.0 |
| b_trend | 0.184 | 0.008 | 0.168 | 0.198 | 0.000 | 0.000 | 3348.0 | 6134.0 | 1.0 |
| sigma_slope | 0.040 | 0.009 | 0.025 | 0.058 | 0.000 | 0.000 | 717.0 | 1619.0 | 1.0 |
| alpha | 0.509 | 0.028 | 0.455 | 0.560 | 0.000 | 0.000 | 4477.0 | 10449.0 | 1.0 |
| lam | 1.589 | 0.248 | 1.129 | 2.048 | 0.005 | 0.004 | 2450.0 | 3531.0 | 1.0 |
| sigma | 0.008 | 0.001 | 0.007 | 0.010 | 0.000 | 0.000 | 13002.0 | 18058.0 | 1.0 |
| nu | 11.355 | 3.099 | 5.825 | 17.072 | 0.017 | 0.012 | 33564.0 | 18162.0 | 1.0 |
As in the second model, the true values of \(\alpha\) and \(\lambda\) are included in the posterior distributions \(94\%\) hdi (up to a scale as we will see below).
axes = az.plot_trace(
data=asdr_model_trace,
var_names=[
"a",
"b_trend",
"sigma_slope",
"b_fourier",
"alpha",
"lam",
"sigma",
"nu",
],
compact=True,
backend_kwargs={"figsize": (12, 12), "layout": "constrained"},
)
fig = axes[0][0].get_figure()
fig.suptitle("Adstock-Saturation-Diminishing-Returns Model - Trace");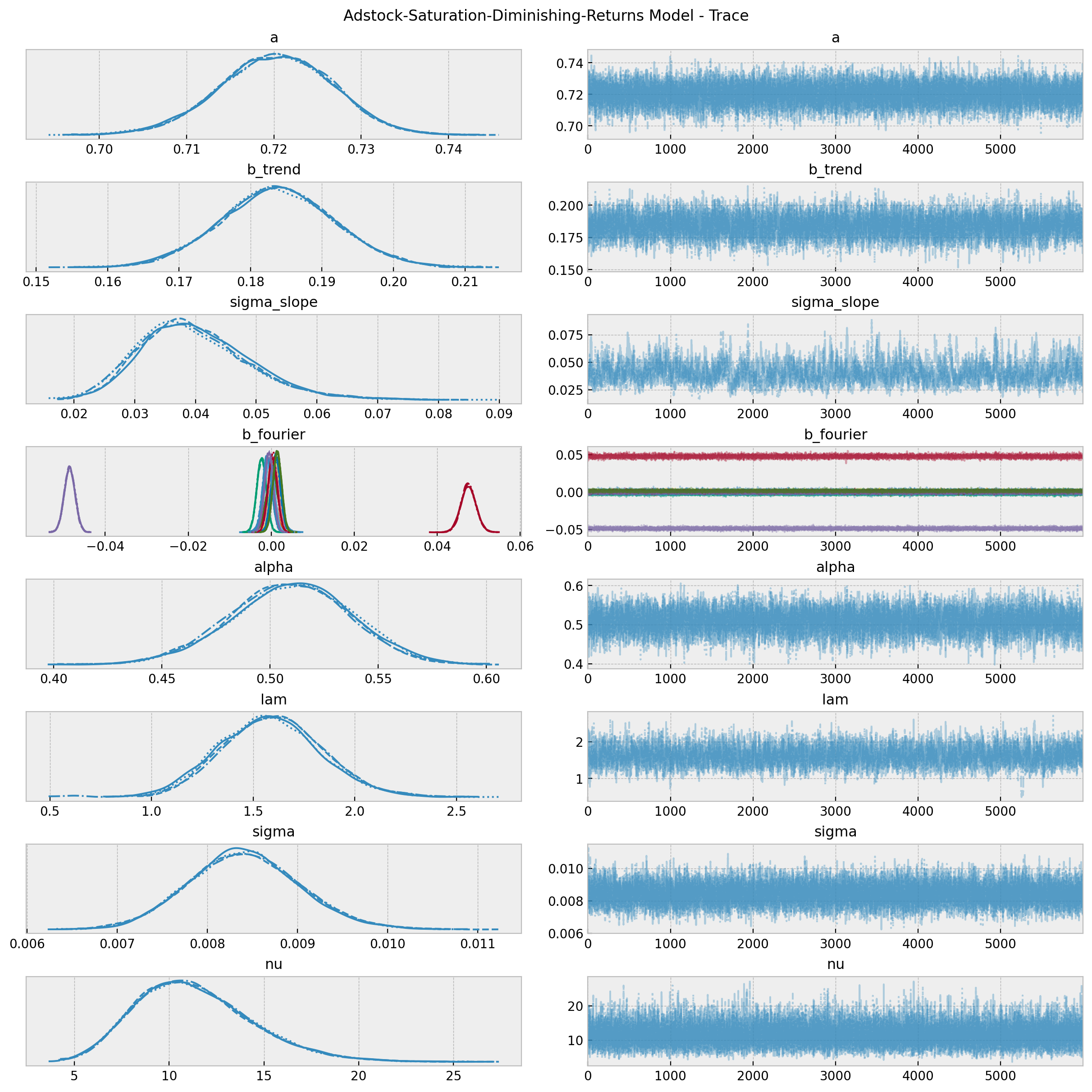
fig, ax = plt.subplots(figsize=(6, 4))
az.plot_forest(
data=asdr_model_trace,
var_names=["a", "b_trend", "sigma_slope", "alpha", "lam", "sigma", "nu"],
combined=True,
ax=ax
)
ax.set(
title="Adstock-Saturation-Diminishing-Returns Model Model: 94.0% HDI",
xscale="log"
);
- Posterior Predictive Samples
posterior_predictive_likelihood = az.extract(
data=asdr_model_posterior_predictive,
group="posterior_predictive",
var_names="likelihood",
)
posterior_predictive_likelihood_inv = endog_scaler.inverse_transform(
X=posterior_predictive_likelihood
)
fig, ax = plt.subplots()
for i, p in enumerate(percs[::-1]):
upper = np.percentile(posterior_predictive_likelihood_inv, p, axis=1)
lower = np.percentile(posterior_predictive_likelihood_inv, 100 - p, axis=1)
color_val = colors[i]
ax.fill_between(
x=date,
y1=upper,
y2=lower,
color=cmap(color_val),
alpha=0.1,
)
sns.lineplot(
x=date,
y=posterior_predictive_likelihood_inv.mean(axis=1),
color="C2",
label="posterior predictive mean",
ax=ax,
)
sns.lineplot(
x=date,
y=y,
color="black",
label="target",
ax=ax,
)
ax.legend(loc="upper left")
ax.set(title="Adstock-Saturation-Diminishing-Returns Model - Posterior Predictive");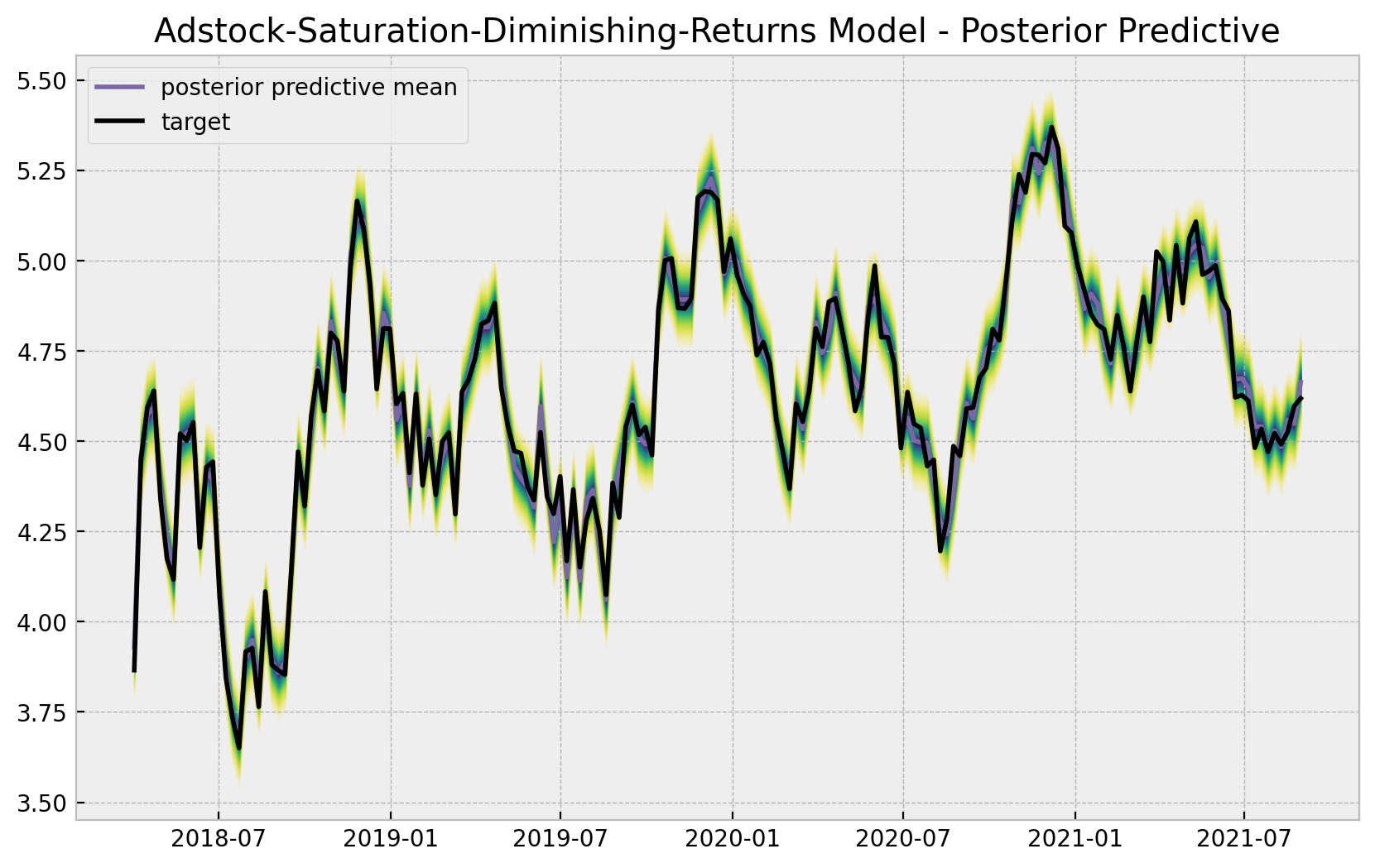
# compute HDI for all the model parameters
model_hdi = az.hdi(ary=asdr_model_trace)
fig, ax = plt.subplots()
for i, var_effect in enumerate(["z_effect", "trend", "seasonality"]):
ax.fill_between(
x=date,
y1=model_hdi[var_effect][:, 0],
y2=model_hdi[var_effect][:, 1],
color=f"C{i}",
alpha=0.3,
label=f"$94\%$ HDI ({var_effect})",
)
sns.lineplot(
x=date,
y=asdr_model_trace.posterior[var_effect]
.stack(sample=("chain", "draw"))
.mean(axis=1),
color=f"C{i}",
)
sns.lineplot(
x=date, y=y_scaled, color="black", alpha=1.0, label="target (scaled)", ax=ax
)
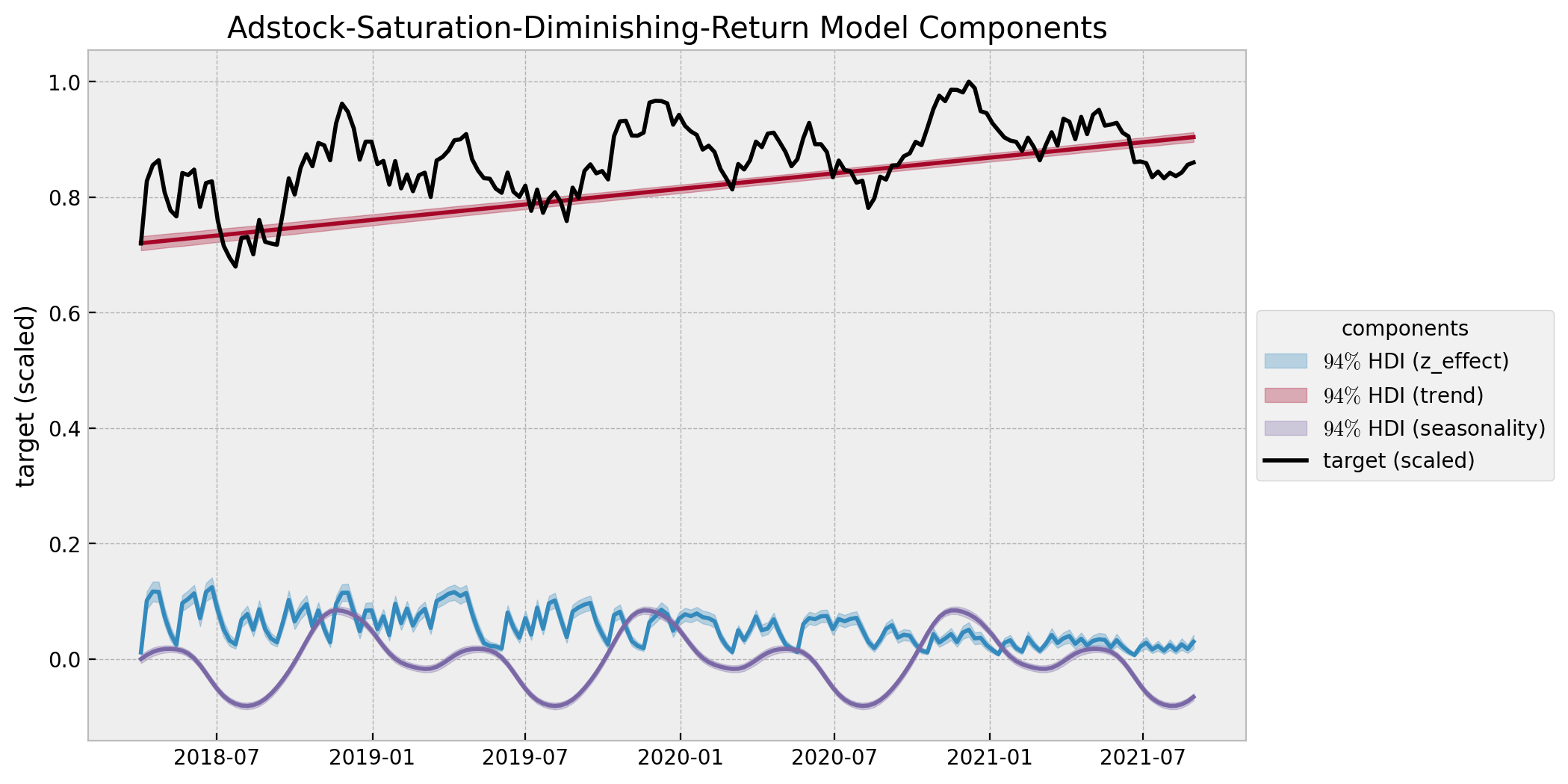
ax.legend(title="components", loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(
title="Adstock-Saturation-Diminishing-Return Model Components",
ylabel="target (scaled)",
);
Now we want to deep dive into the parameters \(\alpha\) and \(\lambda\) of the adstock and saturation transformations respectively. First, let us look into their joint posterior distributions.
alpha_true = 0.5
lam_true = 0.15
lam_true_scaled = 0.15 * channel_scaler.scale_.item()
fig, ax = plt.subplots(figsize=(6, 5))
az.plot_pair(
data=asdr_model_trace,
var_names=["alpha", "lam"],
kind="kde",
divergences=True,
ax=ax
)
ax.axhline(lam_true_scaled, color="C1", linestyle="--", label="$\lambda_{true} (scaled)$")
ax.axvline(alpha_true, color="C4", linestyle="--", label="$\\alpha_{true}$")
ax.legend(title="true params", loc="upper right")
ax.set(
title="Adstock-Saturation-Diminishing-Returns Model",
xlabel="$\\alpha$",
ylabel="$\lambda$"
);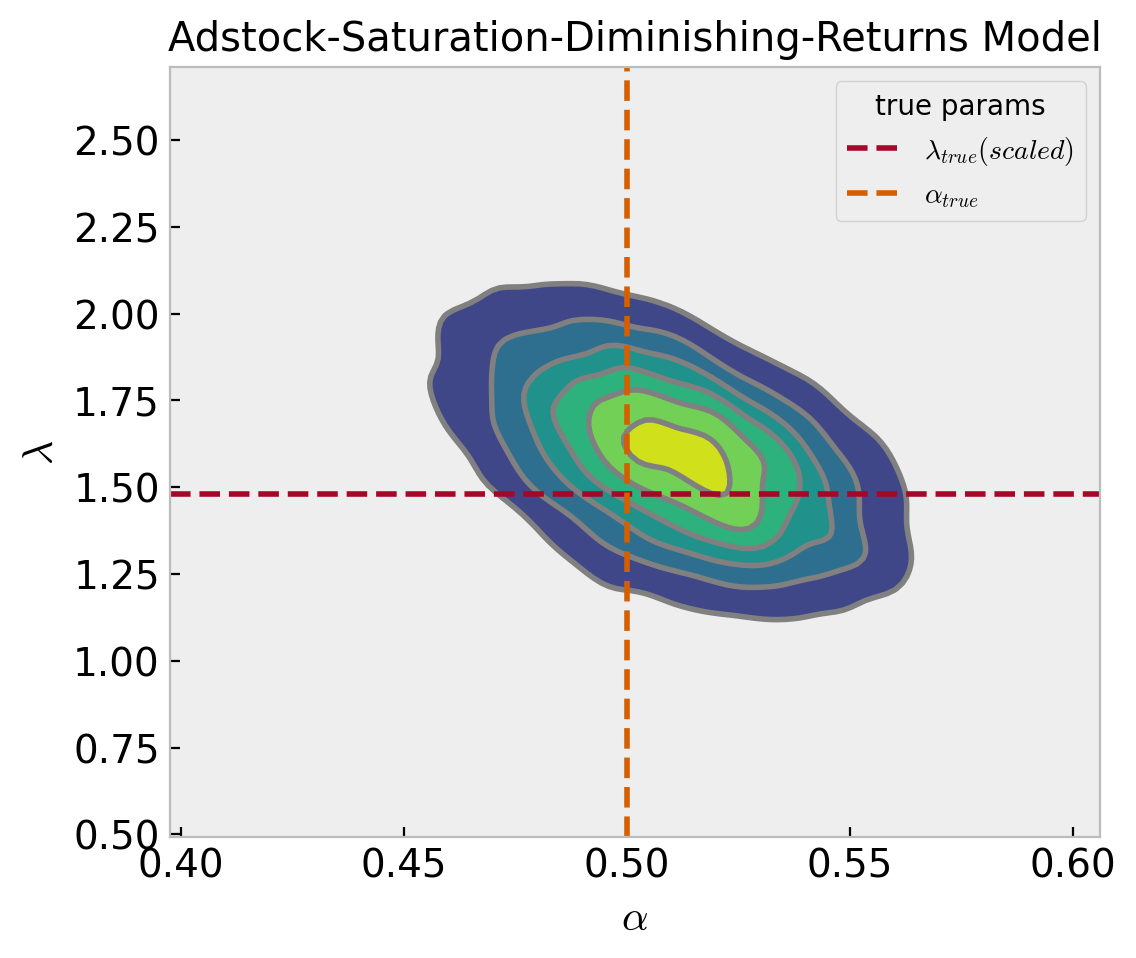
The true values are quite close to the posterior mode. Note that there seems to be a weak negative correlation between these two parameters.
corr, _ = pearsonr(
x=asdr_model_trace.posterior["alpha"].stack(sample=("chain", "draw")).to_numpy(),
y=asdr_model_trace.posterior["lam"].stack(sample=("chain", "draw")).to_numpy()
)
print(f"Correlation between alpha and lambda {corr: 0.3f}");Correlation between alpha and lambda -0.481- \(\alpha\) deep dive
Now, we can look into the posterior distribution of the of z when applying the geometric_adstock transformation for all the \(\alpha\) posterior samples.
alpha_posterior = az.extract(data=asdr_model_trace, group="posterior", var_names="alpha")
alpha_posterior_samples = alpha_posterior.to_numpy()[:100]
# pass z through the adstock transformation
geometric_adstock_posterior_samples = np.array([
geometric_adstock(x=z, alpha=x).eval()
for x in alpha_posterior_samples
])Let us compare the estimates against the true values.
geometric_adstock_hdi = az.hdi(ary=geometric_adstock_posterior_samples)
yerr = geometric_adstock_hdi[:, 1] - geometric_adstock_hdi[:, 0]
fig, ax = plt.subplots(figsize=(8, 7))
markers, caps, bars = ax.errorbar(
x=data_df["z_adstock"],
y=geometric_adstock_posterior_samples.mean(axis=0),
yerr=yerr/2,
color="C0",
fmt='o',
ms=1,
capsize=5,
label="$94\%$ HDI",
)
[bar.set_alpha(0.3) for bar in bars]
ax.axline(
xy1=(10, 10),
slope=1.0,
color="black",
linestyle="--",
label="diagonal"
)
ax.legend()
ax.set(
title="Adstock-Saturation-Diminishing-Returns Model - $\\alpha$ Estimation",
xlabel="z_adstock (true)",
ylabel="z_adstock (pred)",
);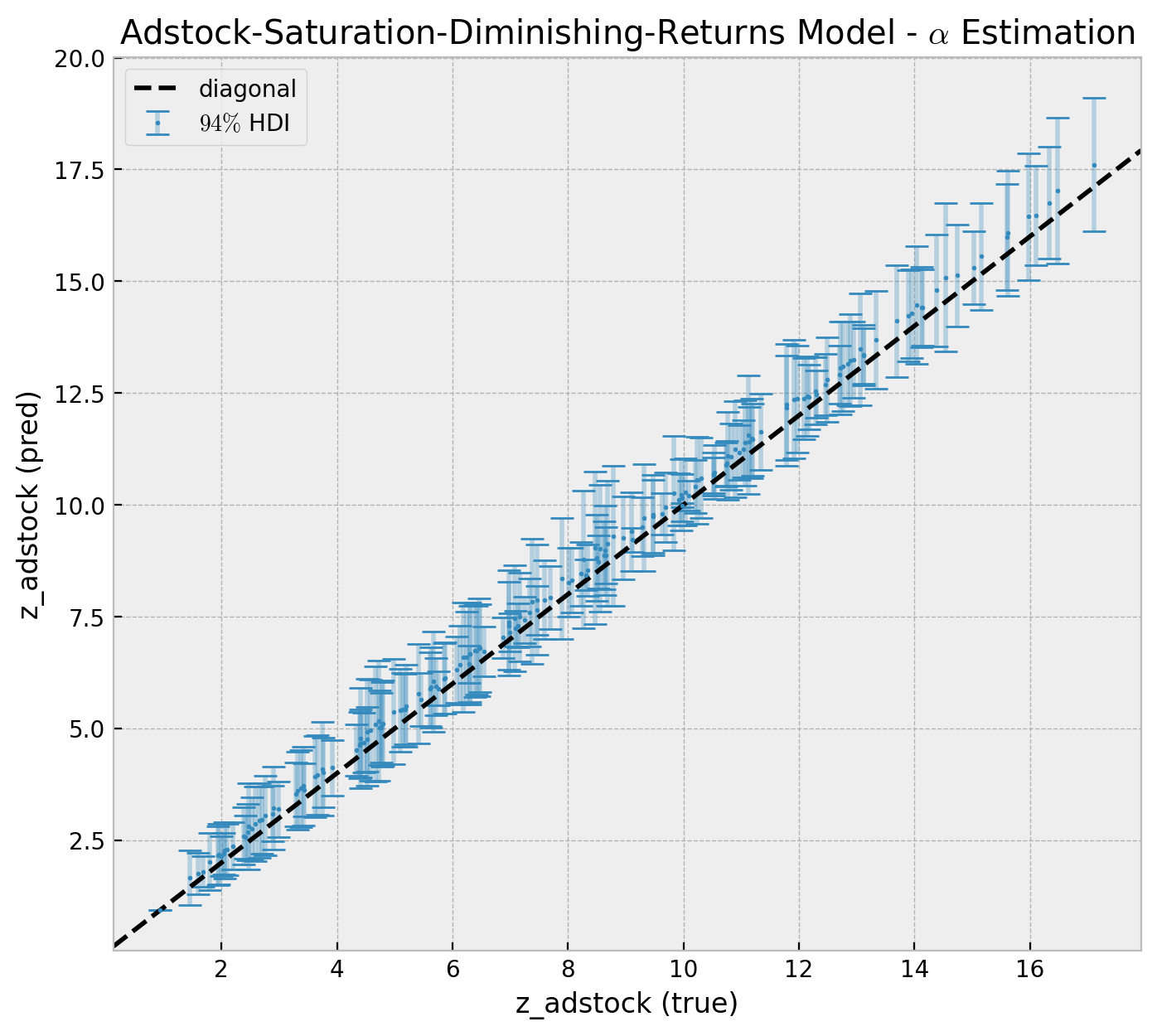
We see that the model is capturing the adstock transformation (within the model uncertainty limits). Note how the hdi intervals increase as a function of z_adstock (true).
- \(\lambda\) deep dive
Next we look into the \(\lambda\) parameter. We follow the a similar strategy as above.
lam_posterior = (
az.extract(data=asdr_model_trace, group="posterior", var_names="lam")
/ channel_scaler.scale_.item()
)
lam_posterior_samples = lam_posterior.to_numpy()[:100]
logistic_saturation_posterior_samples = np.array(
[
logistic_saturation(x=x, lam=lam_posterior_samples).eval()
for x in data_df["z_adstock"].values
]
)We can now plot the estimated saturation curve against the true one.
logistic_saturation_hdi = az.hdi(ary=logistic_saturation_posterior_samples.T)
yerr = logistic_saturation_hdi[:, 1] - logistic_saturation_hdi[:, 0]
fig, ax = plt.subplots(figsize=(7, 6))
latex_function = r"$x\longmapsto \frac{1 - e^{-\lambda x}}{1 + e^{-\lambda x}}$"
markers, caps, bars = ax.errorbar(
x=data_df["z_adstock"],
y=logistic_saturation_posterior_samples.mean(axis=1),
yerr=yerr/2,
color="C0",
fmt='o',
ms=3,
capsize=5,
label="$94\%$ HDI",
)
[bar.set_alpha(0.3) for bar in bars]
sns.lineplot(
x="z_adstock",
y="z_adstock_saturated",
color="C2",
label=latex_function,
data=data_df,
ax=ax
)
ax.legend(loc="lower right", prop={"size": 15})
ax.set(
title="Adstock-Saturation-Diminishing-Returns Model - $\lambda$ Estimation",
xlabel="z_adstock (true)",
ylabel="z_adstock_saturaded (pred)",
);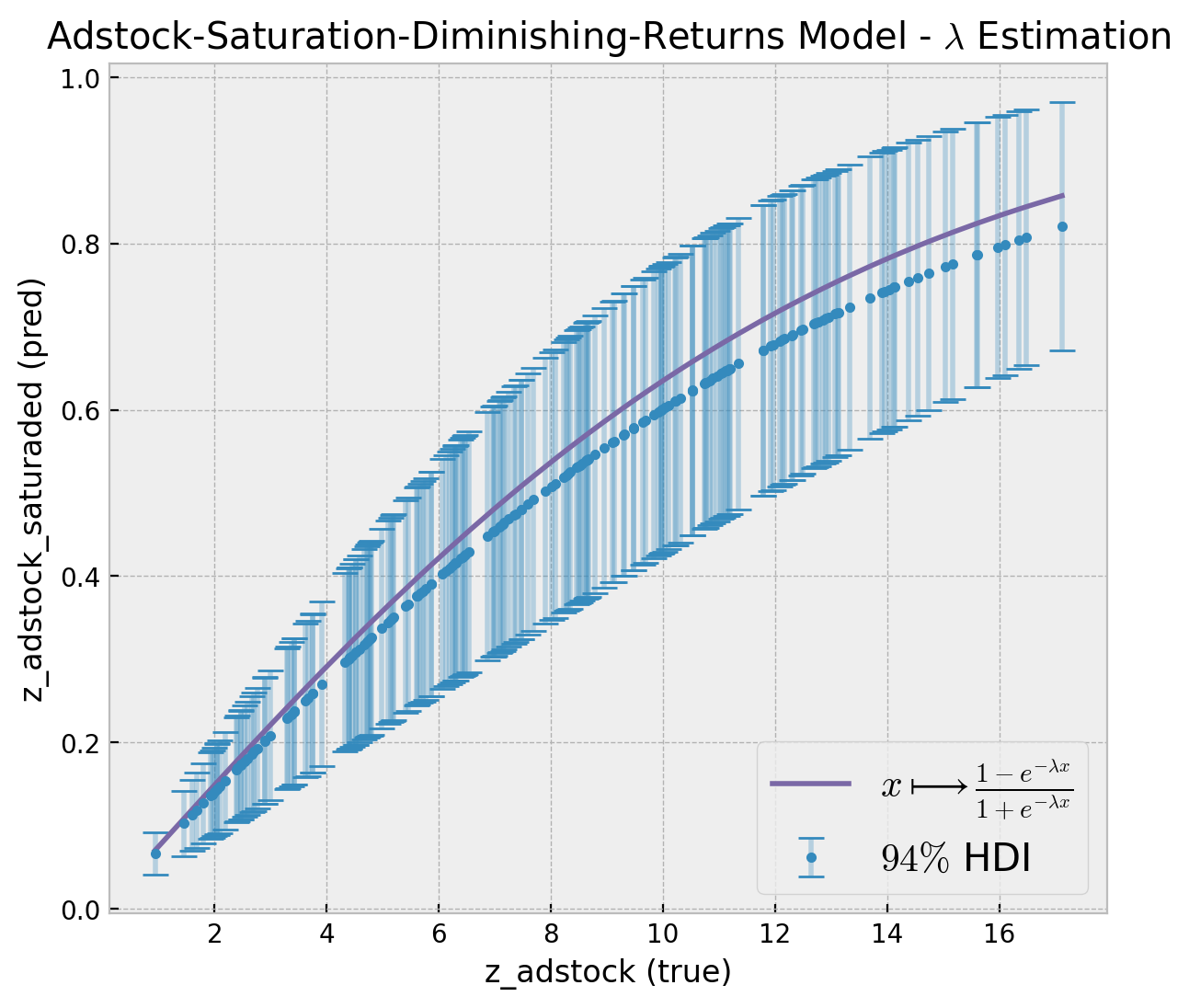
The true saturation curve lies within the \(94\%\) hdi estimated by the model.
- Transformation Deep-Dive
model_hdi_inv = az.hdi(ary=asdr_model_trace)
fig, axes = plt.subplots(
nrows=4, ncols=1, figsize=(12, 9), sharex=True, sharey=False, layout="constrained"
)
sns.lineplot(
x=date,
y=z,
color="black",
ax=axes[0],
)
axes[0].set(title="z")
for i, var_name in enumerate(["z_adstock", "z_adstock_saturated", "z_effect"]):
var_name_posterior = endog_scaler.inverse_transform(
X=az.extract(data=asdr_model_trace, group="posterior", var_names=var_name)
)
var_name_hdi =az.hdi(ary=var_name_posterior.T)
ax = axes[i + 1]
sns.lineplot(
x=date,
y=var_name_posterior.mean(axis=1),
color=f"C{i}",
ax=ax,
)
ax.fill_between(
x=date,
y1=var_name_hdi[:, 0],
y2=var_name_hdi[:, 1],
color=f"C{i}",
alpha=0.5,
)
ax.set(title=var_name)
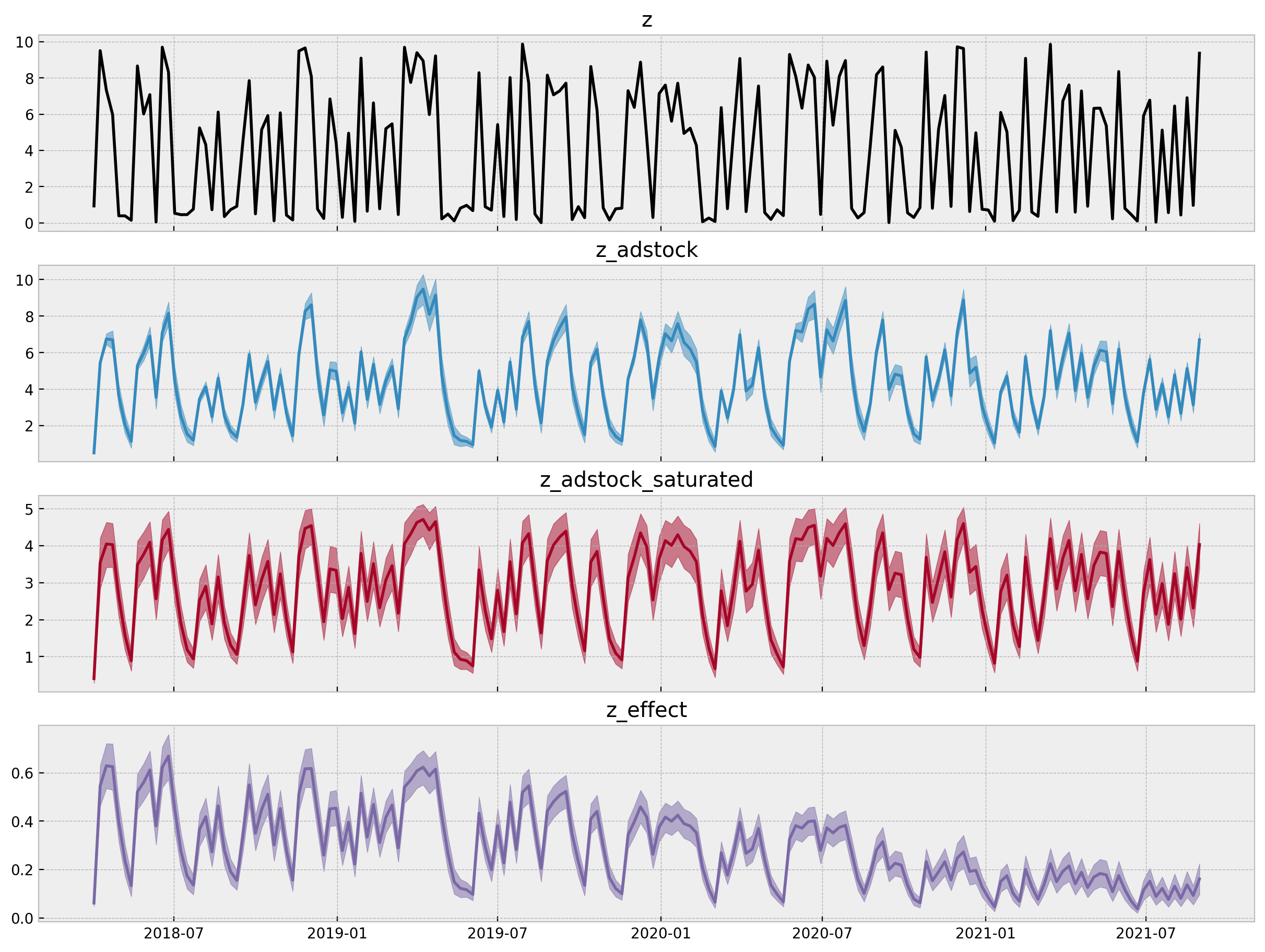
- Estimated
z_effect
Let us look into the estimated effect of z on y inferred by the model against the true one from the data generation process.
z_effect_posterior_samples = xr.apply_ufunc(
lambda x: endog_scaler.inverse_transform(X=x.reshape(1, -1)),
asdr_model_trace.posterior["z_effect"],
input_core_dims=[["date"]],
output_core_dims=[["date"]],
vectorize=True,
)
z_effect_hdi = az.hdi(ary=z_effect_posterior_samples)["z_effect"]
fig, ax = plt.subplots()
ax.fill_between(
x=date,
y1=z_effect_hdi[:, 0],
y2=z_effect_hdi[:, 1],
color="C0",
alpha=0.5,
label="z_effect 94% HDI",
)
ax.axhline(
y=z_effect_posterior_samples.mean(),
color="C0",
linestyle="--",
label=f"posterior mean {z_effect_posterior_samples.mean().values: 0.3f}",
)
sns.lineplot(x="date", y="z_effect", color="C3", data=data_df, label="z_effect", ax=ax)
ax.legend(loc="upper right")
ax.set(
title="Media Cost Effect Estimation - Adstock-Saturation-Diminishing-Returns Model"
);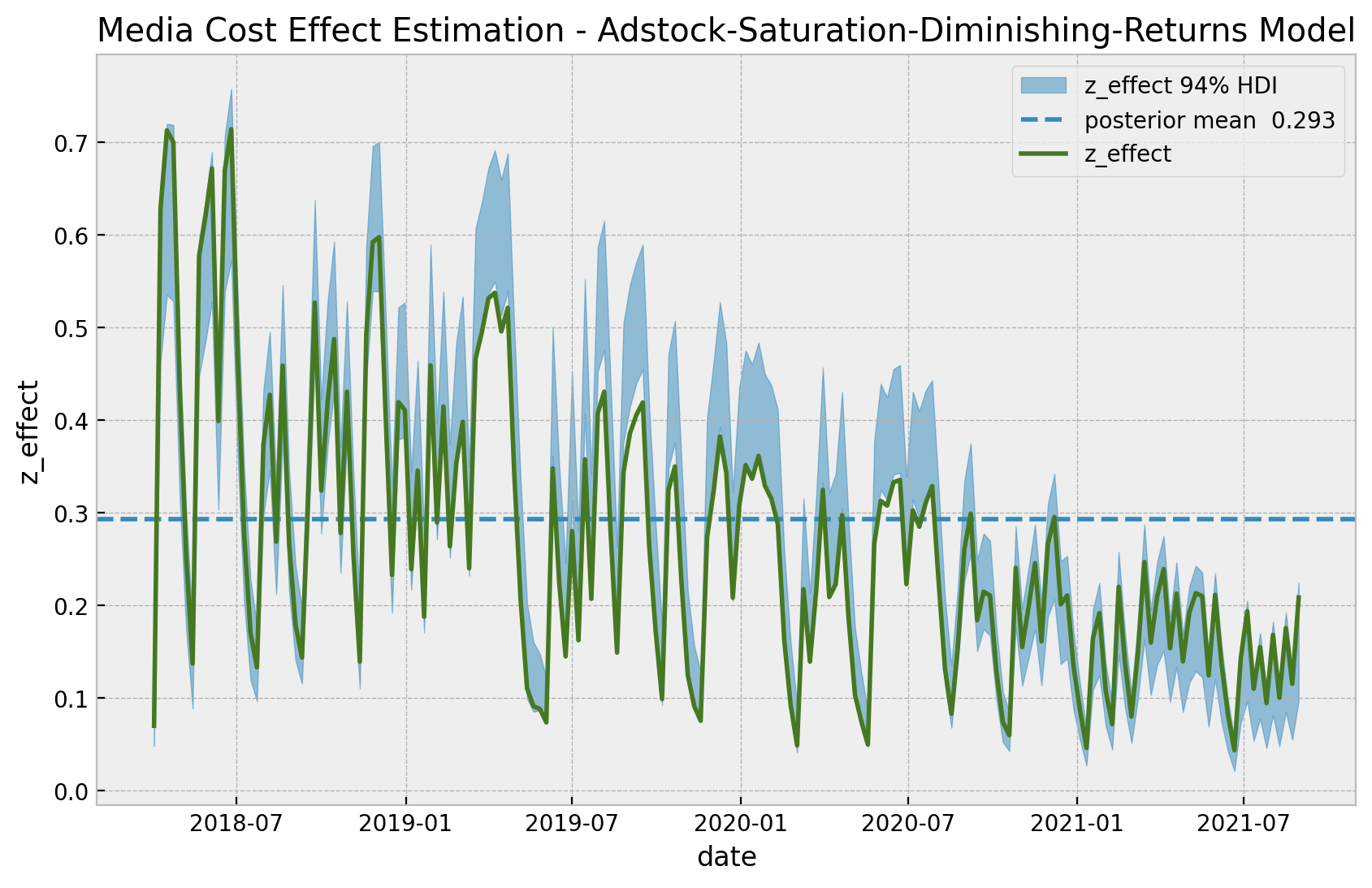
As expected, we get a very good fit. In particular, the model is capturing the time-varying effect as a result of the gaussian random walk component. As above, we can now look into the estimated vs true scatter plot.
fig, ax = plt.subplots()
az.plot_hdi(
x=z,
y=z_effect_posterior_samples,
color="C0",
fill_kwargs={"alpha": 0.2, "label": "z_effect 94% HDI"},
ax=ax,
)
sns.scatterplot(
x="z",
y="z_effect_pred_mean",
color="C0",
size="index",
label="z_effect (pred mean)",
data=data_df.assign(
z_effect_pred_mean=z_effect_posterior_samples.mean(dim=("chain", "draw"))
),
ax=ax,
)
sns.scatterplot(
x="z", y="z_effect", color="C3", size="index", label="z_effect (true)", data=data_df
)
h, l = ax.get_legend_handles_labels()
ax.legend(handles=h[:9], labels=l[:9], loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title="Adstock-Saturation-Diminishing-Returns Model - Estimated Effect");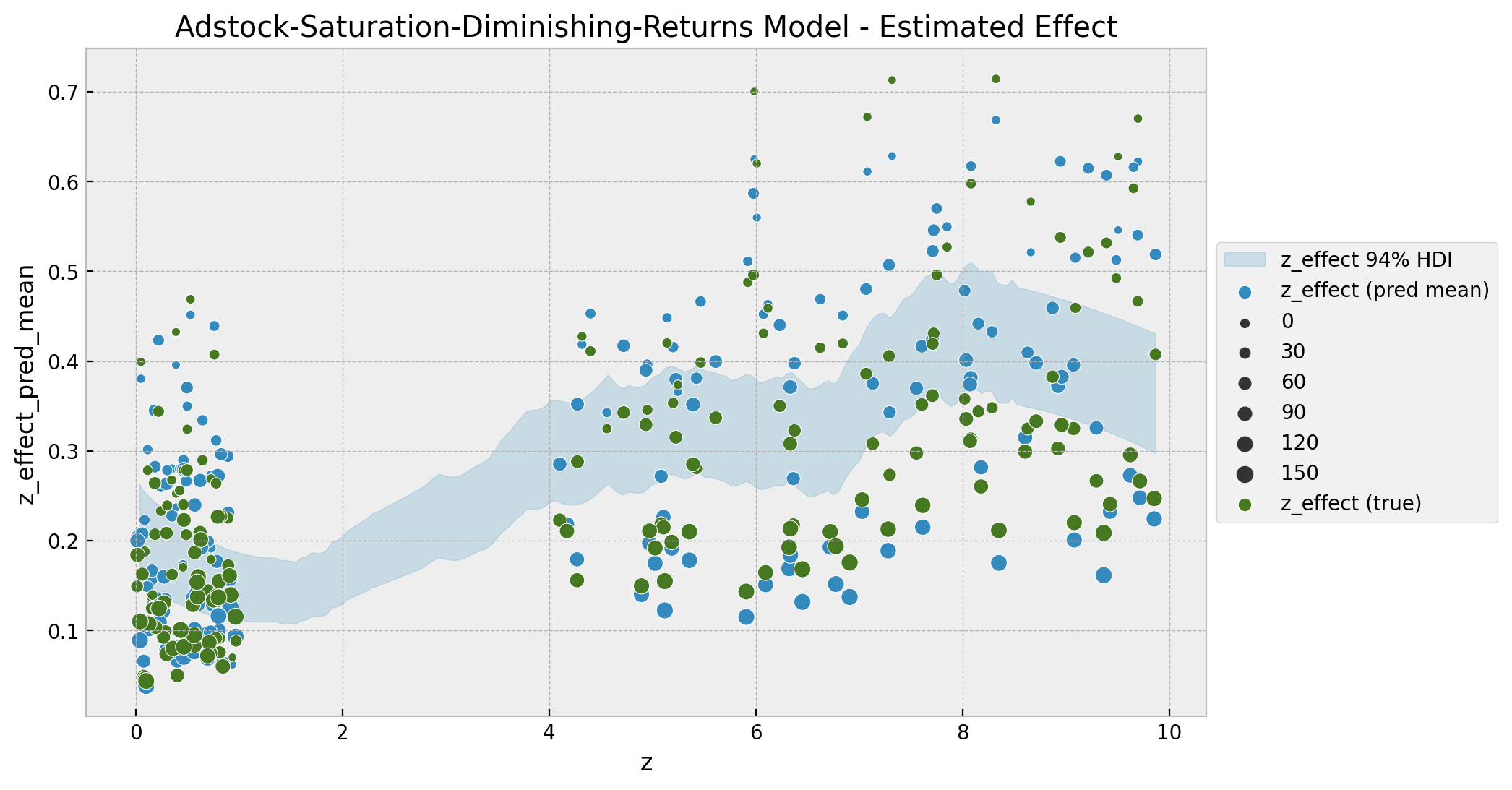
It is interesting to see that the non-linear pattern does not look precisely as a logistic saturation. One of the main reasons for this is the diminishing returns in the time component. We can better see the logistic-like saturation if we factor the time component, for example by splitting by year:
z_effect_hdi = az.hdi(ary=z_effect_posterior_samples)["z_effect"]
data_df = data_df.assign(
z_effect_pred_mean=z_effect_posterior_samples.mean(dim=("chain", "draw")),
z_effect_hdi_lower=z_effect_hdi[:, 0],
z_effect_hdi_upper=z_effect_hdi[:, 1],
)fig, axes = plt.subplots(
nrows=2, ncols=2, figsize=(10, 9), sharex=True, sharey=True, layout="constrained"
)
axes = axes.flatten()
for i, year in enumerate(data_df["year"].sort_values().unique()):
ax = axes[i]
mask = f"year == {year}"
yerr = (
data_df.query(mask)["z_effect_hdi_upper"]
- data_df.query(mask)["z_effect_hdi_lower"]
)
markers, caps, bars = ax.errorbar(
x=data_df.query(mask)["z"],
y=data_df.query(mask)["z_effect_pred_mean"],
yerr=yerr / 2,
color="C0",
fmt="o",
ms=0,
capsize=5,
label="estimated effect",
)
[bar.set_alpha(0.3) for bar in bars]
sns.regplot(
x="z",
y="z_effect_pred_mean",
order=2,
color="C0",
label="pred mean effect",
data=data_df.query(mask),
ax=ax,
)
sns.regplot(
x="z",
y="z_effect",
order=2,
color="C3",
label="true effect",
data=data_df.query(mask),
ax=ax,
)
if i == 0:
ax.legend(loc="upper center", bbox_to_anchor=(0.5, 1.2), ncol=3)
else:
ax.legend().remove()
ax.set(title=f"{year}")
fig.suptitle("Media Cost Effect Estimation - ASDR Model", y=1.05);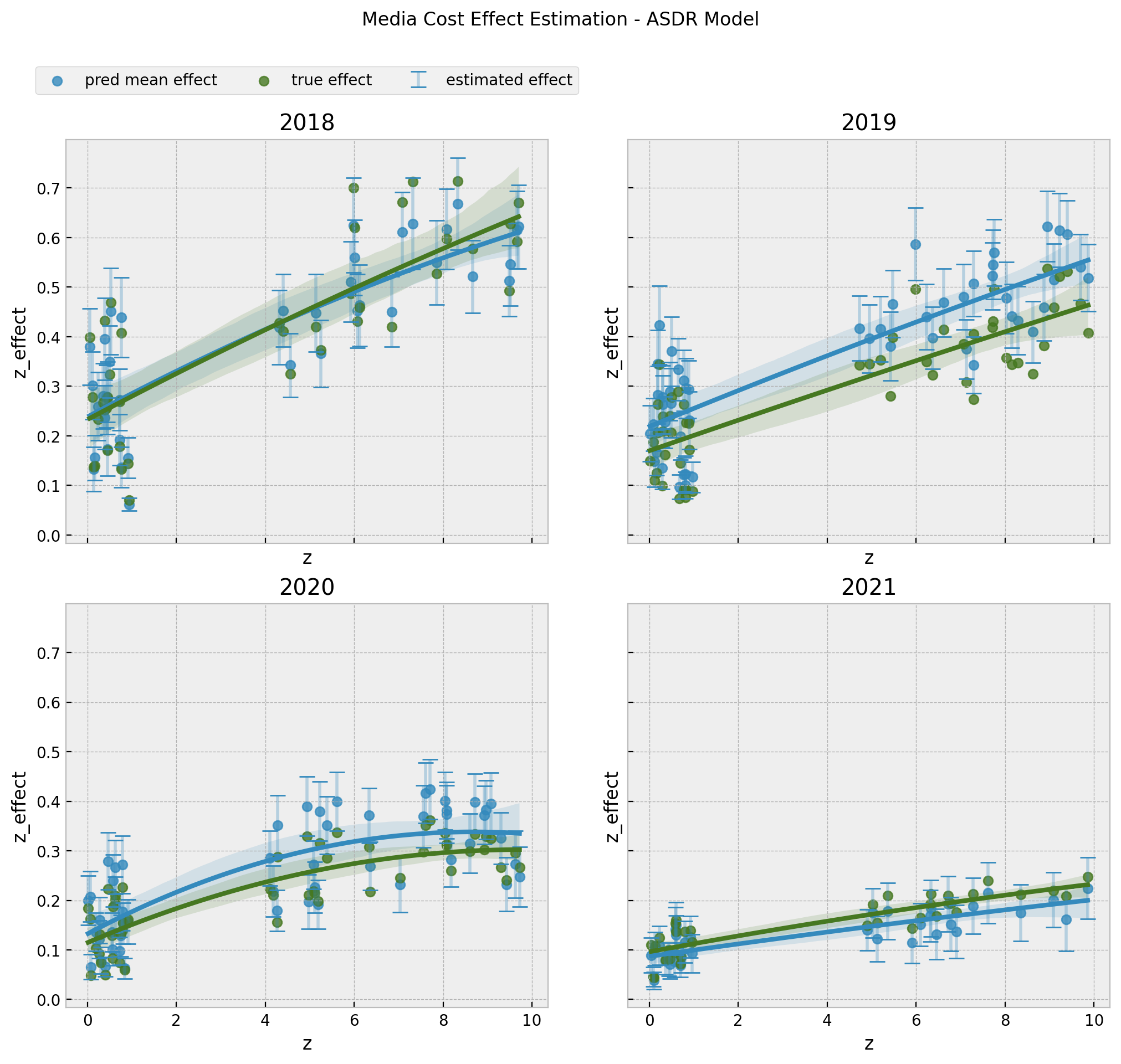
The results look very good 🚀! These are exactly the curves we would need for decision making and budget allocation.
Remark: Note that this plot looks very similar to the one obtained in the post Media Effect Estimation with Orbit’s KTR Model. The main difference is that in the previous post we could only estimated the effect of z_adstock on y while in this one we estimate the effect of z on y directly by learning the adstock effect from the data.
ROAS and mROAS
- ROAS
asdr_model_trace_roas = asdr_model_trace.copy()
with asdr_model:
pm.set_data(new_data={"z_scaled": np.zeros_like(a=z_scaled)})
asdr_model_trace_roas.extend(
other=pm.sample_posterior_predictive(trace=asdr_model_trace_roas, var_names=["likelihood"])
)asdr_roas_numerator = (
endog_scaler.inverse_transform(
X=az.extract(
data=asdr_model_posterior_predictive,
group="posterior_predictive",
var_names=["likelihood"],
)
)
- endog_scaler.inverse_transform(
X=az.extract(
data=asdr_model_trace_roas,
group="posterior_predictive",
var_names=["likelihood"],
)
)
).sum(axis=0)
roas_denominator = z.sum()
asdr_roas = asdr_roas_numerator / roas_denominator
asdr_roas_mean = np.median(asdr_roas)
asdr_roas_hdi = az.hdi(ary=asdr_roas)
g = sns.displot(x=asdr_roas, kde=True, height=5, aspect=1.5)
ax = g.axes.flatten()[0]
ax.axvline(
x=asdr_roas_mean, color="C0", linestyle="--", label=f"mean = {asdr_roas_mean: 0.3f}"
)
ax.axvline(
x=asdr_roas_hdi[0],
color="C1",
linestyle="--",
label=f"HDI_lwr = {asdr_roas_hdi[0]: 0.3f}",
)
ax.axvline(
x=asdr_roas_hdi[1],
color="C2",
linestyle="--",
label=f"HDI_upr = {asdr_roas_hdi[1]: 0.3f}",
)
ax.axvline(x=roas_true, color="black", linestyle="--", label=f"true = {roas_true: 0.3f}")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title="Adstock-Saturation-Diminishing-Returns Model ROAS");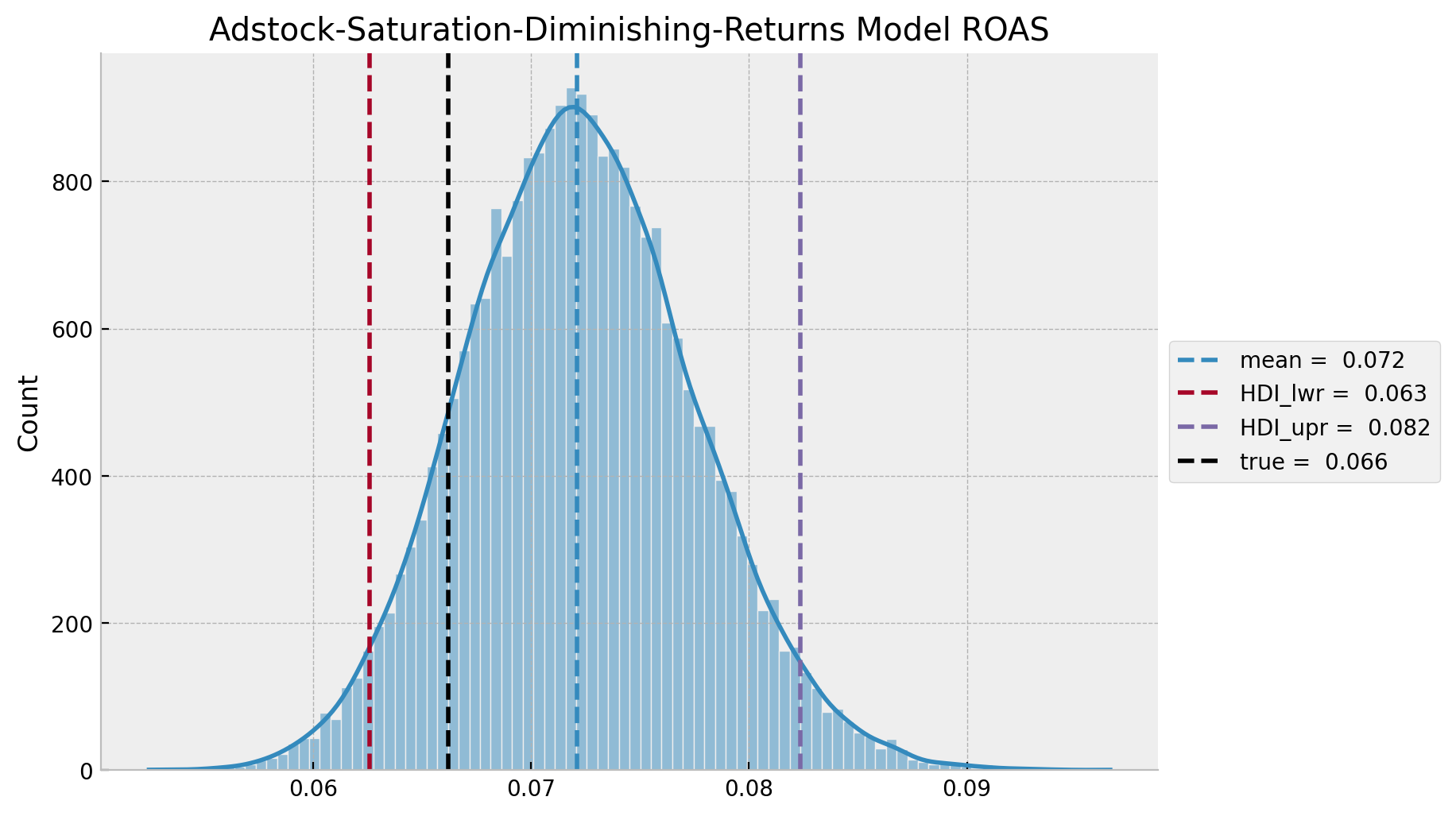
As expected, the true and predicted values are very close! Also, the HDI is much smaller than the adstock-saturation model.
- mROAS
eta: float = 0.10
asdr_model_trace_mroas = asdr_model_trace.copy()
with asdr_model:
pm.set_data(new_data={"z_scaled": (1 + eta) * z_scaled})
asdr_model_trace_mroas.extend(
other=pm.sample_posterior_predictive(trace=asdr_model_trace_mroas, var_names=["likelihood"])
)asdr_mroas_numerator = (
endog_scaler.inverse_transform(
X=az.extract(
data=asdr_model_trace_mroas,
group="posterior_predictive",
var_names=["likelihood"],
)
)
- endog_scaler.inverse_transform(
X=az.extract(
data=asdr_model_posterior_predictive,
group="posterior_predictive",
var_names=["likelihood"],
)
)
).sum(axis=0)
mroas_denominator = eta * z.sum()
asdr_mroas = asdr_mroas_numerator / mroas_denominatorasdr_mroas_mean = asdr_mroas.mean()
asdr_mroas_hdi = az.hdi(ary=asdr_mroas)
g = sns.displot(x=asdr_mroas, kde=True, height=5, aspect=1.5)
ax = g.axes.flatten()[0]
ax.axvline(
x=asdr_mroas_mean, color="C0", linestyle="--", label=f"mean = {asdr_mroas_mean: 0.3f}"
)
ax.axvline(
x=asdr_mroas_hdi[0],
color="C1",
linestyle="--",
label=f"HDI_lwr = {asdr_mroas_hdi[0]: 0.3f}",
)
ax.axvline(
x=asdr_mroas_hdi[1],
color="C2",
linestyle="--",
label=f"HDI_upr = {asdr_roas_hdi[1]: 0.3f}",
)
ax.axvline(x=0.0, color="gray", linestyle="--", label="zero")
ax.axvline(x=mroas_true, color="black", linestyle="--", label=f"true = {mroas_true: 0.3f}")
ax.legend(loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(title=f"Adstock-Saturation-Diminishing-Returns Model MROAS ({eta:.0%} increase)");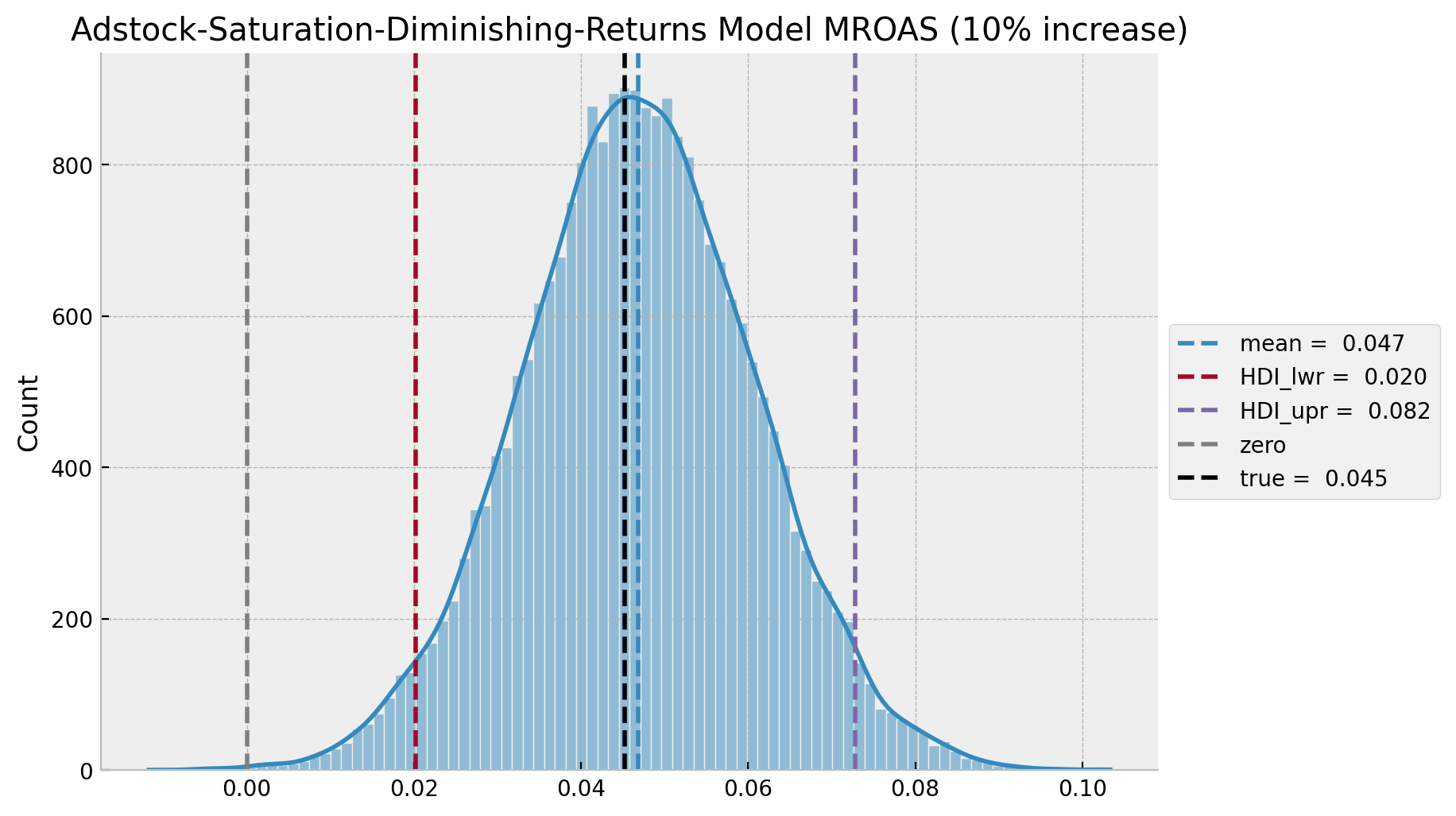
The estimated mROAS mean and the true values aver almost the same!
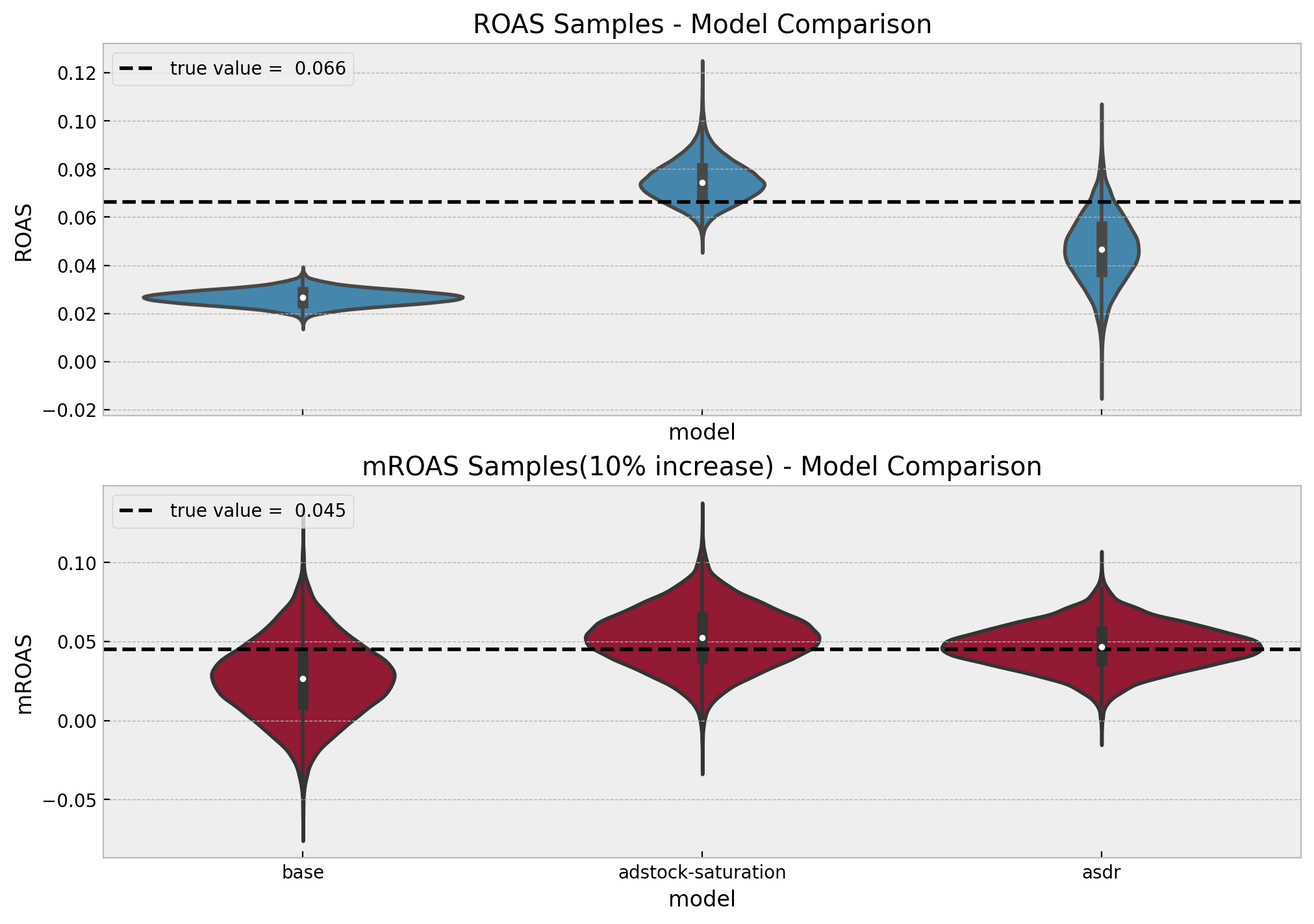
Model Comparison
To end this notebook, let us compare the three models.
dataset_dict = {
"base_model": base_model_trace,
"adstock_saturation_model": adstock_saturation_model_trace,
"asdr_model": asdr_model_trace,
}
az.compare(compare_dict=dataset_dict, ic="loo", method="stacking", scale="log")| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| asdr_model | 0 | 565.150979 | 36.346577 | 0.000000 | 0.984025 | 9.062507 | 0.000000 | False | log |
| adstock_saturation_model | 1 | 518.390205 | 20.722418 | 46.760774 | 0.015975 | 8.762302 | 8.842153 | False | log |
| base_model | 2 | 464.316965 | 18.135413 | 100.834014 | 0.000000 | 10.852874 | 12.764730 | False | log |
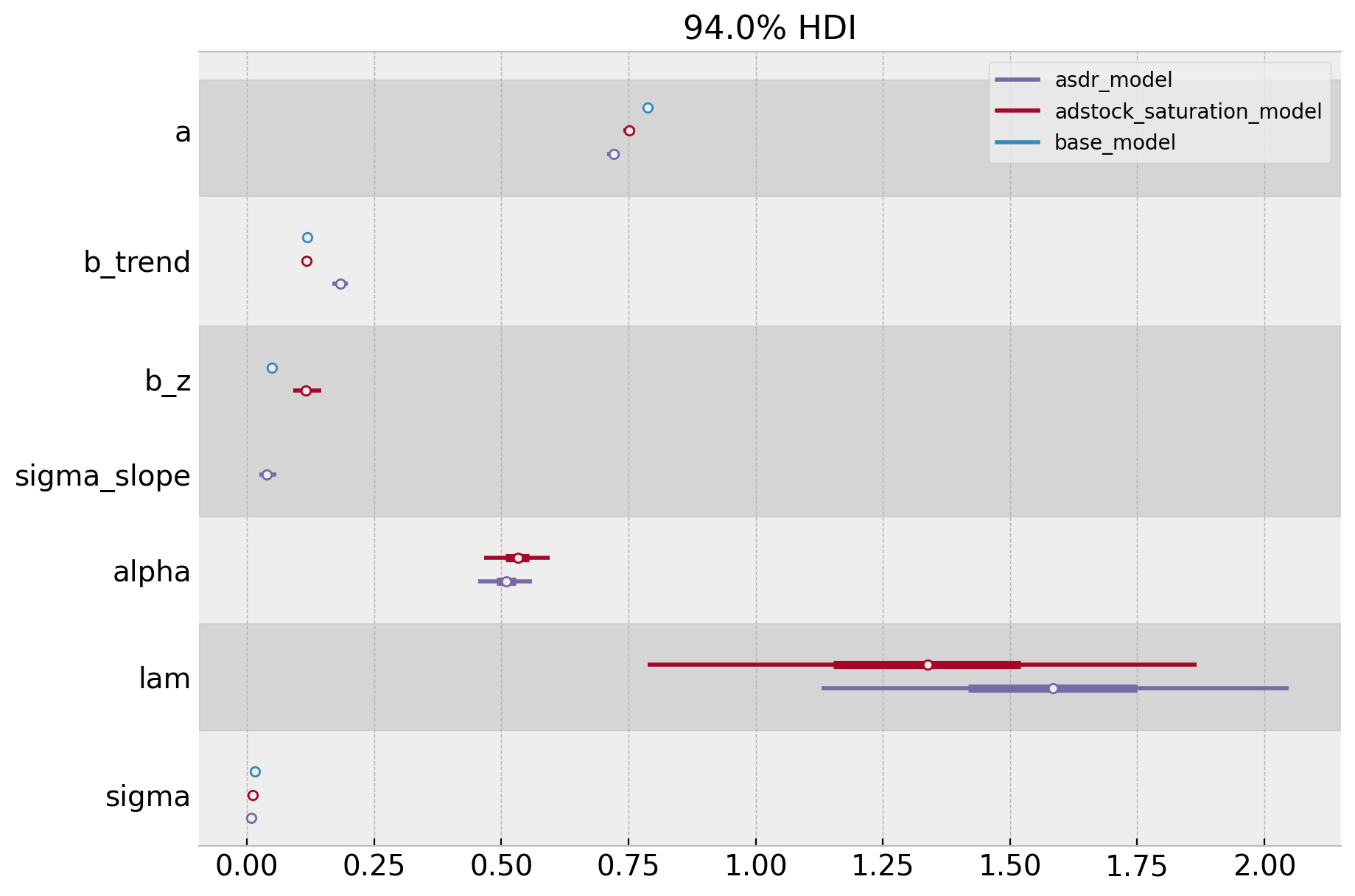
We clearly see that the asdr_model is the best one (no surprise here). Let’s finally compare the posterior distributions for the three models.
axes = az.plot_forest(
data=[base_model_trace, adstock_saturation_model_trace, asdr_model_trace],
model_names=["base_model", "adstock_saturation_model", "asdr_model"],
var_names=["a", "b_trend", "b_z", "sigma_slope", "alpha", "lam", "sigma"],
combined=True,
figsize=(10, 7),
);
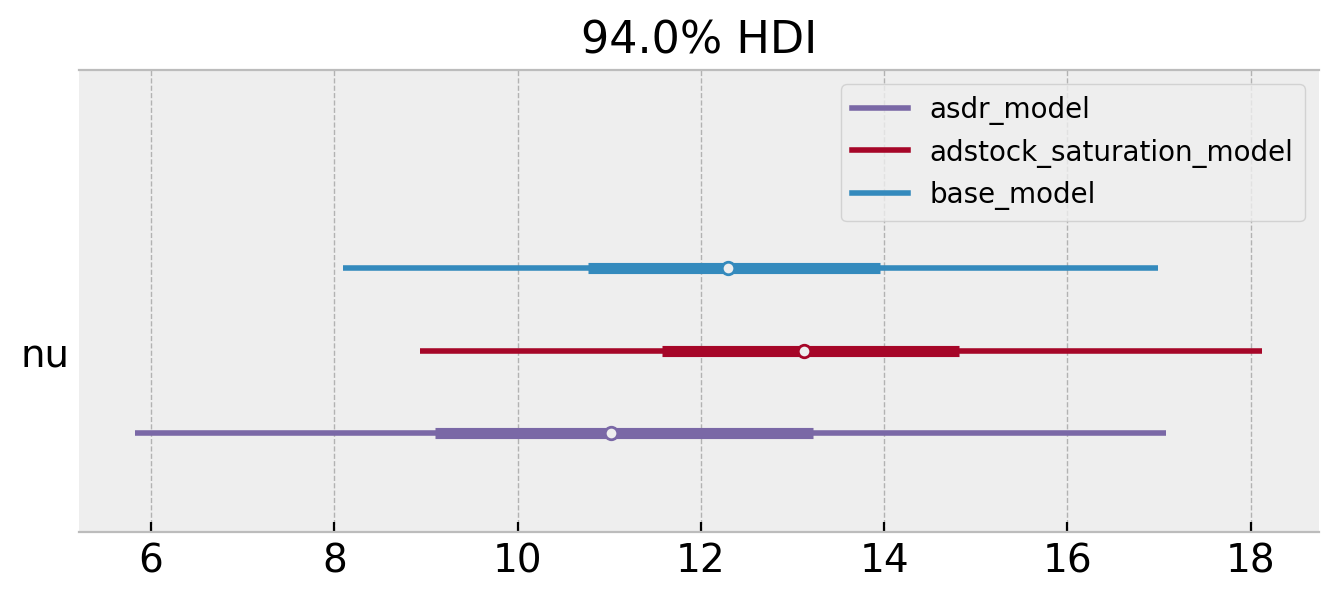
axes = az.plot_forest(
data=[base_model_trace, adstock_saturation_model_trace, asdr_model_trace],
model_names=["base_model", "adstock_saturation_model", "asdr_model"],
var_names=["nu"],
combined=True,
figsize=(8, 3),
);
Finally, let’s compare the estimated ROAS and mROAS of all models. First we collect the samples:
roas_samples_df = (
pd.DataFrame(
data={
"base": base_roas,
"adstock-saturation": adstock_saturation_roas,
"asdr": asdr_mroas,
}
)
.melt()
.assign(metric="ROAS")
)
mroas_samples_df = (
pd.DataFrame(
data={
"base": base_mroas,
"adstock-saturation": adstock_saturation_mroas,
"asdr": asdr_mroas,
}
)
.melt()
.assign(metric="mROAS")
)Now we generate the plots:
fig, axes = plt.subplots(
nrows=2, ncols=1, sharex=True, sharey=False, figsize=(10, 7), layout="constrained"
)
sns.violinplot(x="variable", y="value", color="C0", data=roas_samples_df, ax=axes[0])
axes[0].axhline(
y=roas_true, color="black", linestyle="--", label=f"true value = {roas_true: 0.3f}"
)
axes[0].legend(loc="upper left")
axes[0].set(title="ROAS Samples - Model Comparison", xlabel="model", ylabel="ROAS")
sns.violinplot(x="variable", y="value", color="C1", data=mroas_samples_df, ax=axes[1])
axes[1].axhline(
y=mroas_true,
color="black",
linestyle="--",
label=f"true value = {mroas_true: 0.3f}",
)
axes[1].legend(loc="upper left")
axes[1].set(
title=f"mROAS Samples({eta:.0%} increase) - Model Comparison",
xlabel="model",
ylabel="mROAS",
);