In this notebook, we want to explore some ideas on hierarchical Hilbert Space Gaussian Processes following the fantastic exposition of the PyMC example notebook: “Gaussian Processes: HSGP Advanced Usage” by Bill Engels, Alexandre Andorra and Maxim Kochurov. I can only recommend to read the notebook and the references therein! For an introduction to Hilbert Space Gaussian Processes, please see my introductory blog post: “A Conceptual and Practical Introduction to Hilbert Space GPs Approximation Methods”.
Motivation: In many applications, one is interested in understanding the dynamic effect of one variable on another. For example, in marketing, one is interested in efficiency across many channels on sales (or conversions) as a function of time. For such a purpose, one typically uses a time-varying regression model with time-varying coefficients (for a simple example, see “Time-Varying Regression Coefficients via Hilbert Space Gaussian Process Approximation”). The main challenge is that, if not done carefully, the model will easily overfit the data. One can use a hierarchical model with a global component and a group-specific component to overcome this. The global component will capture the overall trend, while the group-specific component will capture the idiosyncratic behavior of each group. As a side effect, we will gain some regularization effect that will help to avoid overfitting. For the marketing example above, PyMC Labs has successfully applied this approach in the context of media mix modeling: “Bayesian Media Mix Models: Modelling changes in marketing effectiveness over time”. This hierarchical approach was motivated by the work “Hierarchical Bayesian modeling of gene expression time series across irregularly sampled replicates and clusters”. Here is a schematic diagram of the hierarchical approach (taken from the paper):
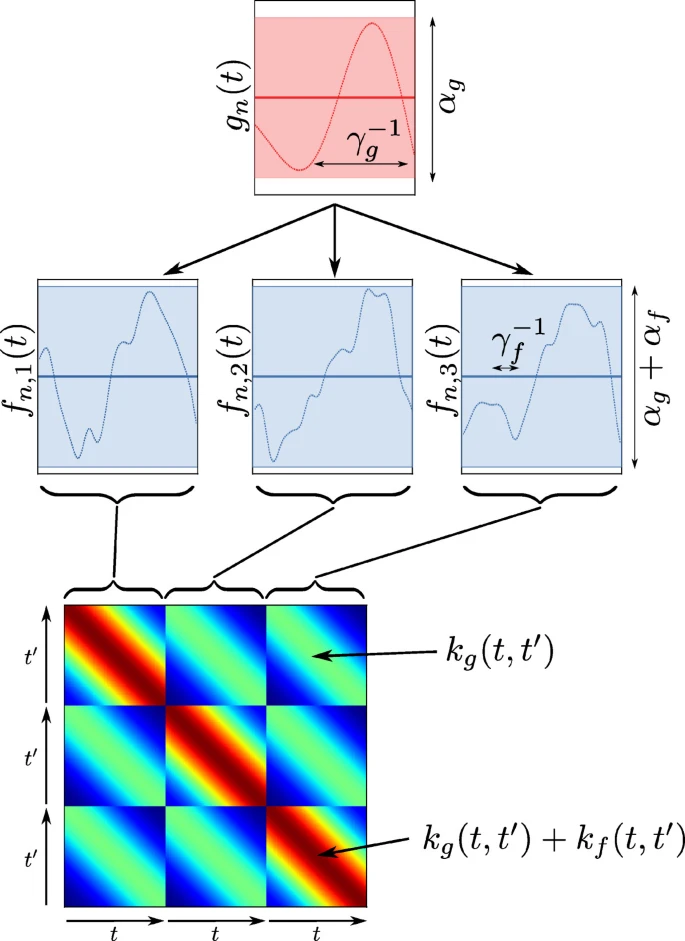
The main idea is to model a global Gaussian process and for the group-level estimates one model the offsets against this global mean.
To my knowledge (please correct me if I am wrong), the PyMC example notebook “Gaussian Processes: HSGP Advanced Usage” is the first reference with complete code to fit a hierarchical Hilbert Space Gaussian Process (well, maybe the initial gist). Here, we use very similar techniques with NumPyro using the (relatively) new Hilbert Space Gaussian Process module. For both the PyMC and NumPyro implementations, one of the key ingredients is vectorizing the spectral density expressions (as we need to fit many groups). While in the PyMC notebook, the vectorization is done by hand, in the NumPyro implementation, the vectorization is done using the vmap function. Nevertheless, both approaches are equivalent. Hence, we can focus on the concepts and worry less about the implementation details.
With these new explicit code references, we expect to demystify the implementation of the hierarchical Hilbert Space Gaussian Process so that the community can benefit from this approach for real applications. That being said, as we will see below, this approach has its challenges. As in many applications with Gaussian processes, specifying sensitive priors and ensuring parameter identifiability is not a trivial task. Here is where the application should drive the model specification (where the thinking happens!).
Prepare Notebook
import arviz as az
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
import numpyro
import numpyro.distributions as dist
from jax import random, vmap
from jax.nn import softplus
from jaxtyping import Array, Float32, UInt32
from numpyro.contrib.hsgp.approximation import hsgp_squared_exponential
from numpyro.contrib.hsgp.laplacian import eigenfunctions
from numpyro.contrib.hsgp.spectral_densities import (
diag_spectral_density_squared_exponential,
)
from numpyro.handlers import condition, scope
from numpyro.infer import MCMC, NUTS, Predictive
from xarray import DataArray # noqa: F401
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
numpyro.set_host_device_count(n=4)
rng_key = random.PRNGKey(seed=42)
%load_ext autoreload
%autoreload 2
%load_ext jaxtyping
%jaxtyping.typechecker beartype.beartype
%config InlineBackend.figure_format = "retina"Generate Synthetic Data
We start by generating some synthetic data. We do not do a full parameter recovery as in the PyMC notebook. Instead, we simple generate synthetic data, fit and asses the quality of the model. We will use a single group-specific latent function for each group. The mean function is a sum of two sine waves.
def generate_single_group_data(
rng_key: UInt32[Array, "2"], x: Float32[Array, " n"]
) -> Float32[Array, " n"]:
"""Generate one dimensional data for a single group.
Parameters
----------
rng_key : UInt32[Array, "2"]
JAX random key.
x : Float32[Array, " n"]
Input domain data.
Returns
-------
Float32[Array, " n"]
Output data.
"""
a1, a2, a3, a4 = random.uniform(rng_key, minval=4, maxval=7, shape=(4,))
return (
jnp.sin((a1 * jnp.pi) * x)
+ jnp.cos((a2 * jnp.pi) * x)
- jnp.sin((a3 * 2 * jnp.pi) * x)
+ jnp.cos((a4 * 1.5 * jnp.pi) * x)
)
def dgg(
rng_key: UInt32[Array, "2"], x: Float32[Array, " n"]
) -> tuple[Float32[Array, " n"], Float32[Array, " n"], Float32[Array, " n"]]:
"""Data generation function.
We generate data for a single group by adding noise to the mean latent function.
y = f + f_g + noise
where:
- f is the mean function (GP)
- f_g is the group-specific latent function (GP)
- noise is i.i.d. Gaussian noise
Parameters
----------
rng_key : UInt32[Array, "2"]
JAX random key.
x : Float32[Array, " n"]
Input domain data.
Returns
-------
tuple[Float32[Array, " n"], Float32[Array, " n"], Float32[Array, " n"]]
Group-specific latent function, mean function and observed data.
"""
n = x.shape[0]
f_g = generate_single_group_data(rng_key, x)
f = jnp.sin((4 * jnp.pi) * x) + jnp.sin((1 * jnp.pi) * x)
noise = random.normal(rng_key, shape=(n,)) * 0.5
y = f + f_g + noise
return f_g, f, y
# Number of observations and groups
n = 200
n_groups = 5
# Input domain data
x = jnp.linspace(0.1, 1, n)
# Generate data
rng_key, rng_subkey = random.split(rng_key)
# Generate data for each group
f_g, f, y = vmap(dgg)(
random.split(rng_subkey, n_groups), jnp.tile(x, reps=(n_groups, 1))
)
# Check shapes
assert f_g.shape == (n_groups, n)
assert f.shape == (n_groups, n)
assert y.shape == (n_groups, n)Let’s visualize the raw data.
fig, ax = plt.subplots()
for g in range(n_groups):
ax.plot(x, y[g], c=f"C{g}", label=f"group {g}")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.05), ncol=n_groups)
ax.set_title("Observed data", fontsize=18, fontweight="bold");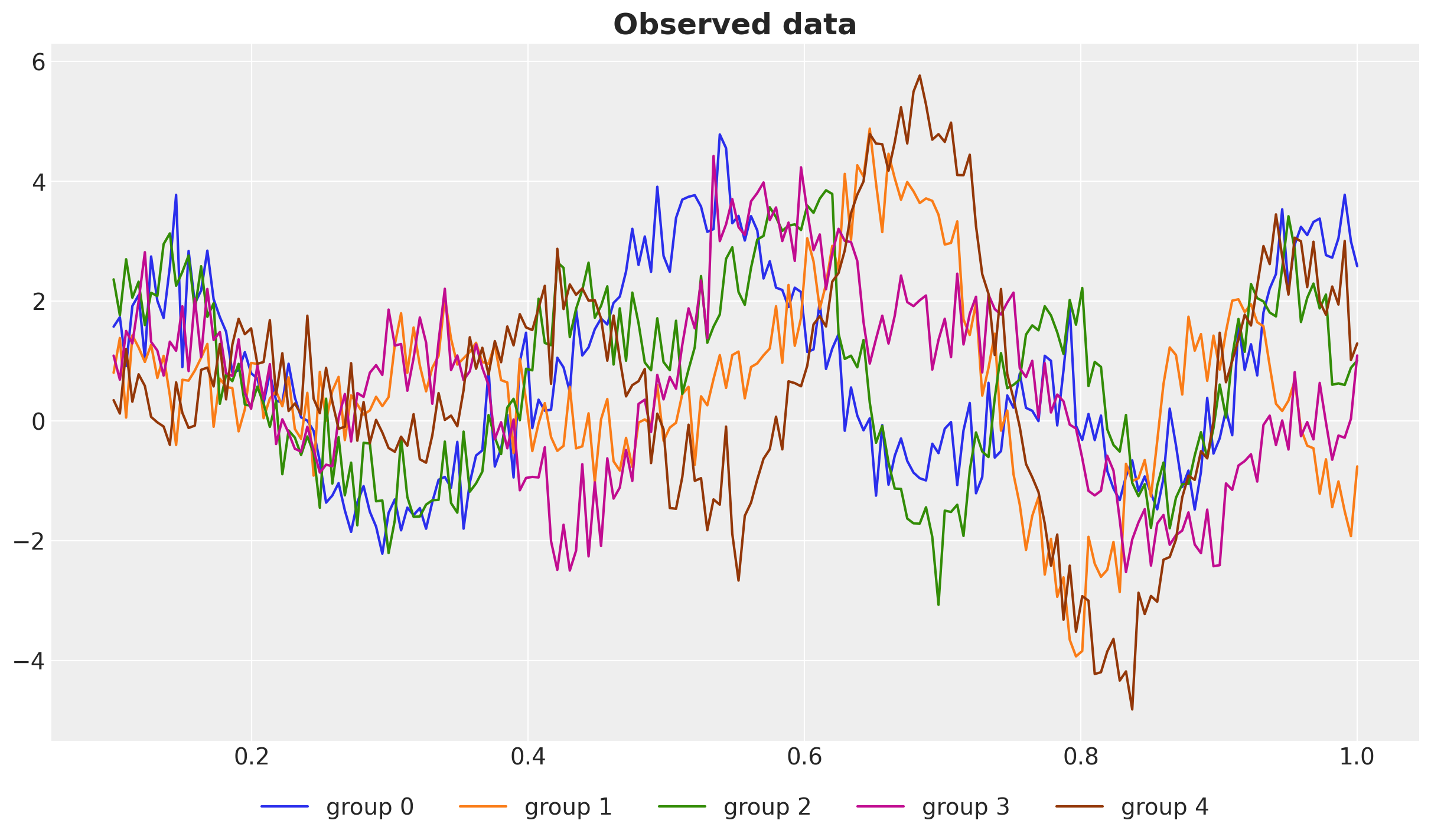
We see that each group has different dynamics, but they some how follow a global pattern. This hidden pattern is the latent mean function that we would like to recover using the hierarchical structure.
Next, let’s visualize the group-specific latent functions.
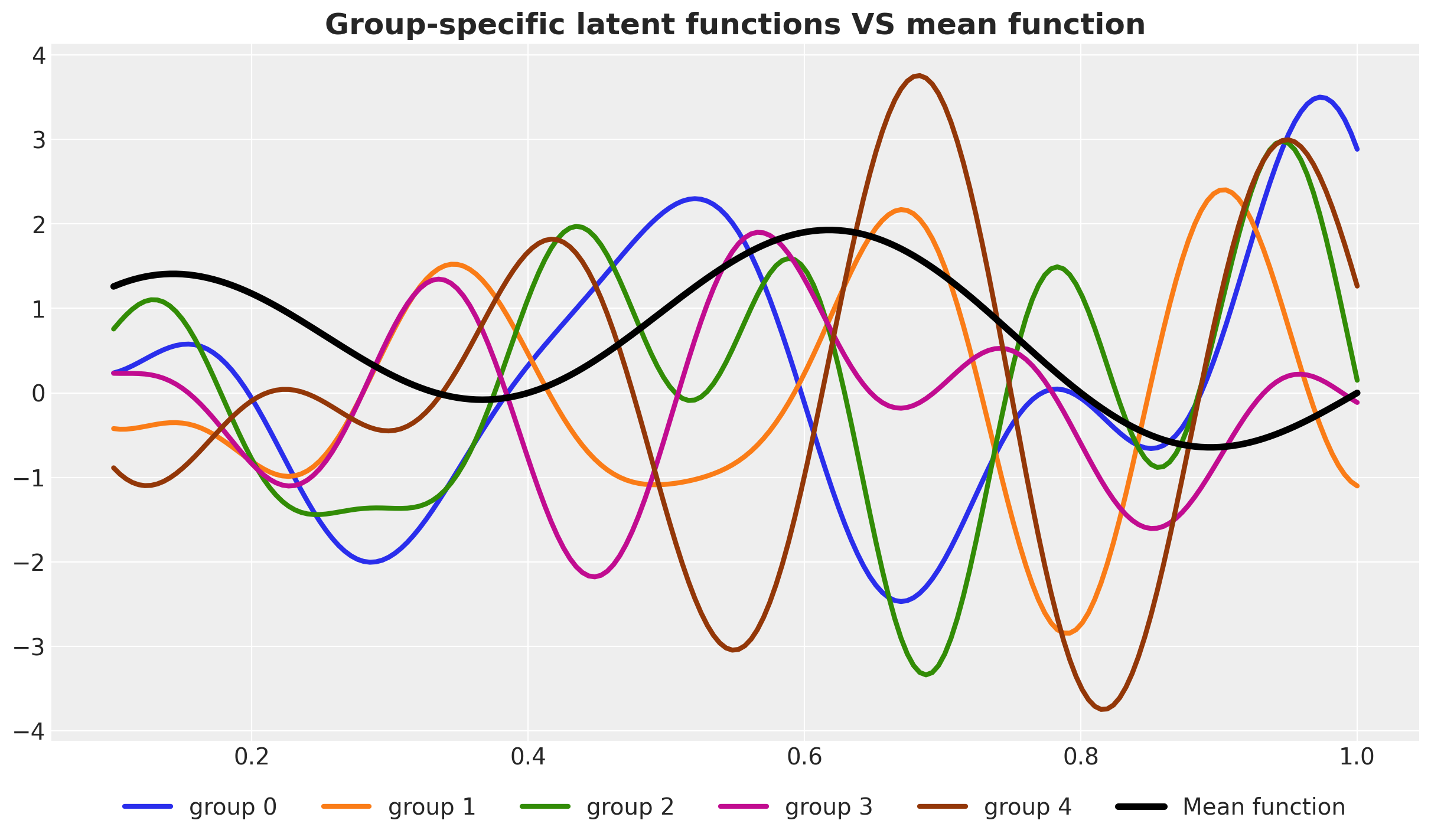
fig, ax = plt.subplots()
for g in range(n_groups):
ax.plot(x, f_g[g], lw=3, c=f"C{g}", label=f"group {g}")
ax.plot(x, f[0], c="black", lw=4, label="Mean function")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.05), ncol=n_groups + 1)
ax.set_title(
"Group-specific latent functions VS mean function", fontsize=18, fontweight="bold"
);
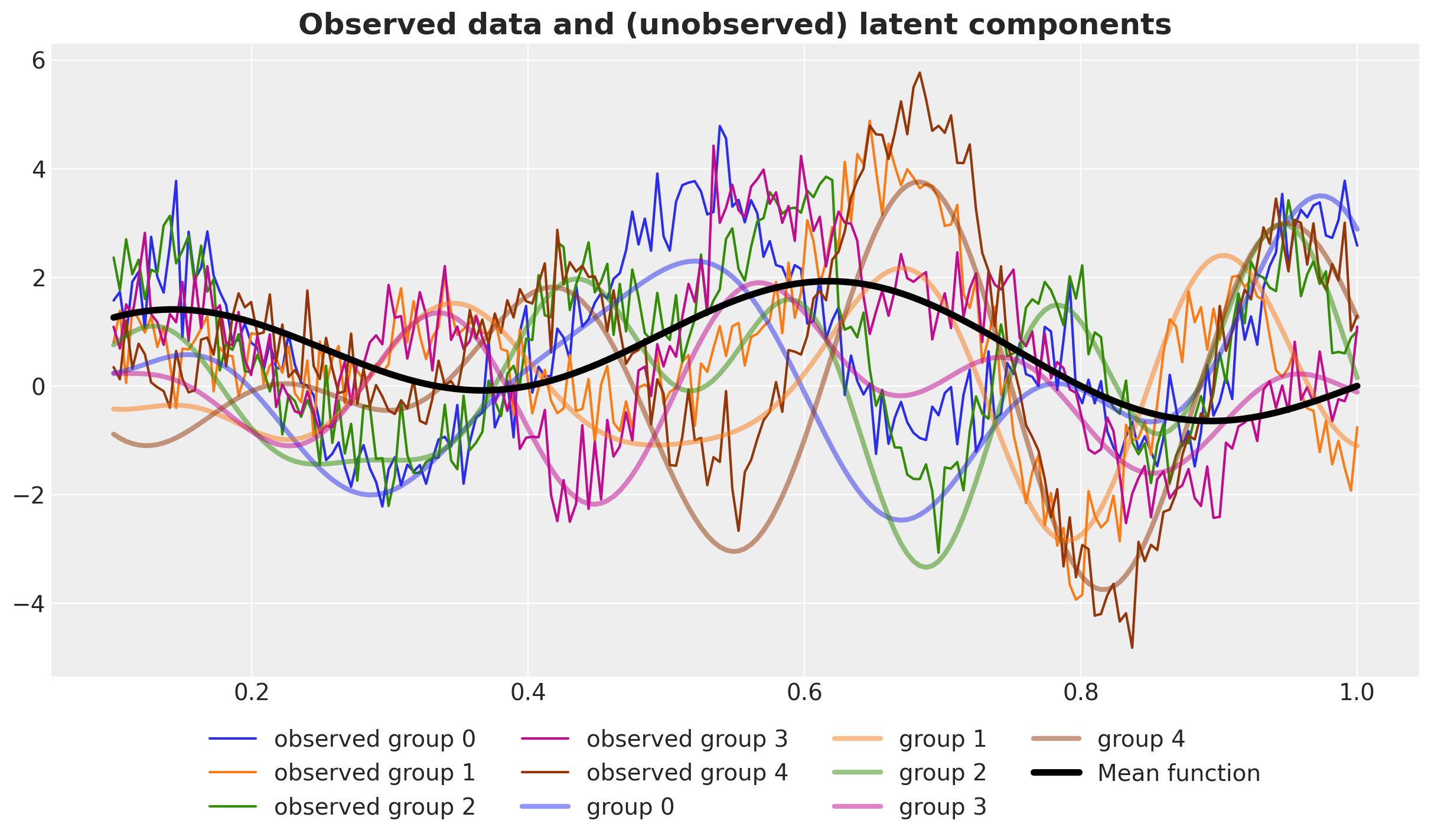
Finally, let’s look at everything together.
fig, ax = plt.subplots()
for g in range(n_groups):
ax.plot(x, y[g], c=f"C{g}", label=f"observed group {g}")
for g in range(n_groups):
ax.plot(x, f_g[g], lw=3, c=f"C{g}", alpha=0.5, label=f"group {g}")
ax.plot(x, f[0], c="black", lw=4, label="Mean function")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.05), ncol=n_groups - 1)
ax.set_title(
"Observed data and (unobserved) latent components", fontsize=18, fontweight="bold"
);
Train Test Split
Next, we do a simple train/test split.
# Share of data to use for training
share_train = 0.9
# Number of training observations
n_train = int(n * share_train)
x_train = x[:n_train]
x_test = x[n_train:]
f_train = f[:, :n_train]
f_test = f[:, n_train:]
f_g_train = f_g[:, :n_train]
f_g_test = f_g[:, n_train:]
y_train = y[:, :n_train]
y_test = y[:, n_train:]
# Check shapes
assert x_train.shape == (n_train,)
assert x_test.shape == (n - n_train,)
assert f_train.shape == (n_groups, n_train)
assert f_test.shape == (n_groups, n - n_train)
assert f_g_train.shape == (n_groups, n_train)
assert f_g_test.shape == (n_groups, n - n_train)
assert y_train.shape == (n_groups, n_train)
assert y_test.shape == (n_groups, n - n_train)We can visualize the train/test split result.
fig, ax = plt.subplots()
for g in range(n_groups):
ax.plot(x_train, y_train[g], c=f"C{g}", label=f"group {g} (train)")
ax.plot(
x_test, y_test[g], c=f"C{g}", ls="dotted", alpha=0.5, label=f"group {g} (test)"
)
ax.axvline(x=x_train[-1], c="gray", lw=2)
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.05), ncol=n_groups)
ax.set_title("Observed data (train/test split)", fontsize=18, fontweight="bold");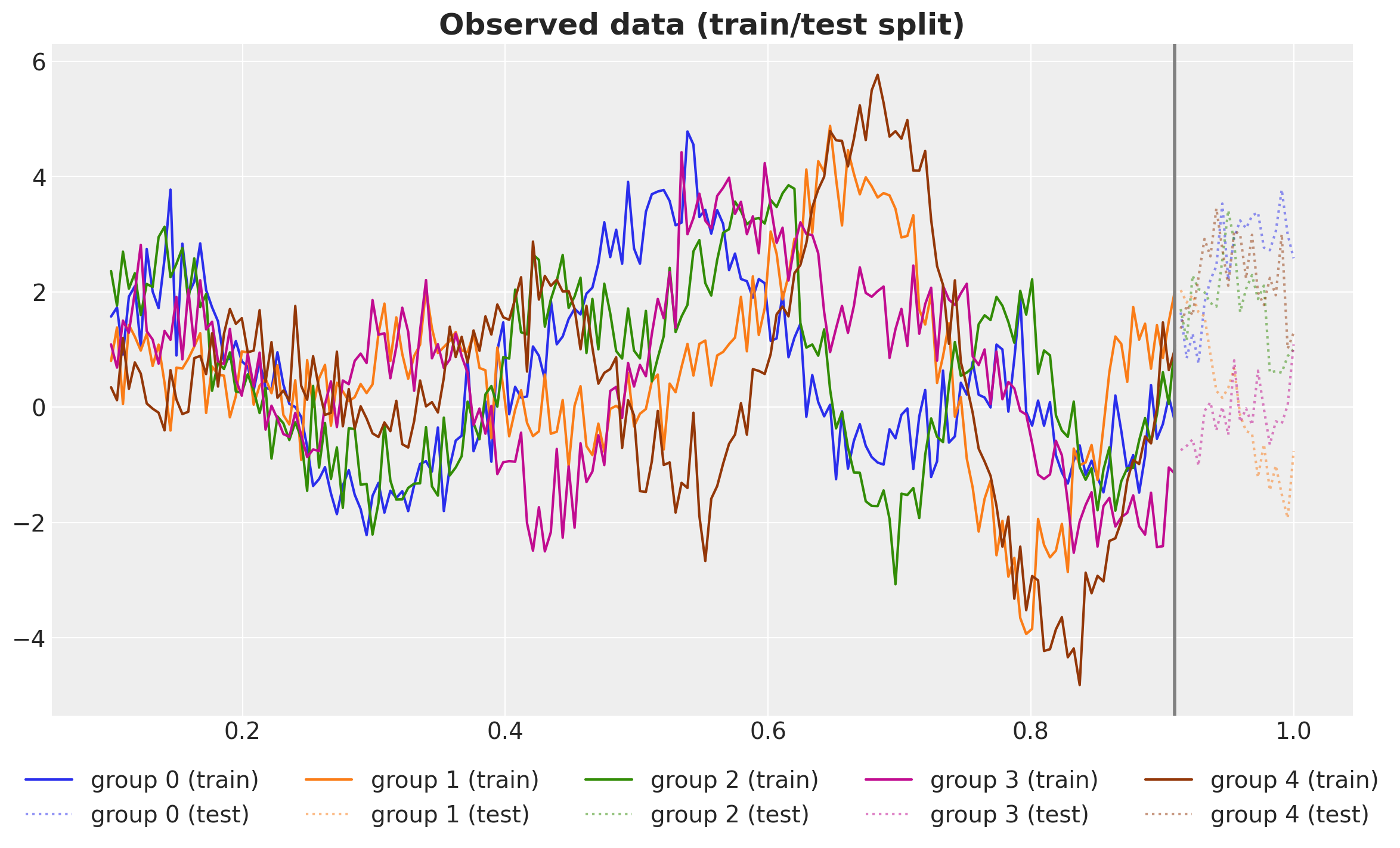
Vectorized Spectral Density
As a reminder, the Hilbert Space Gaussian Process approximation is given by (see “A Conceptual and Practical Introduction to Hilbert Space GPs Approximation Methods” for a very complete explanation of the algorithm):
\[ f(x) \approx \sum_{j = 1}^{m} \overbrace{\color{red}{\left(S(\sqrt{\lambda_j})\right)^{1/2}}}^{\text{Spectral Density: all hyperparameters are here!}} \times \underbrace{\color{blue}{\phi_{j}(x)}}_{\text{Eigenfunctions: easy to compute!}} \times \overbrace{\color{green}{\beta_{j}}}^{\sim \: \text{Normal}(0,1)} \]
where
- \(S\) is the spectral density of the GP kernel. This in the only term that contains the hyperparameters of the GP kernel (amplitude and length scale).
- \((\phi_{j}(x), \lambda_{j})\) are the eigenfunctions and eigenvalues of the Dirichlet Laplacian operator on a unit hypercube.
- \(\beta_{j}\) are the coefficients of the eigenfunction.
The spectral density expressions for the most used kernels are known and easy to implement. In many cases, and for most of the applications, the implementations are not fully vectorized to allow for many outputs. For our concrete application, we need to vectorize the spectral density expressions to allow for many groups. With JAX, this is straightforward using the vmap function.
def diag_spectral_density_squared_exponential_vectorized(
alpha: Float32[Array, " n_groups"],
length: Float32[Array, " n_groups"],
ell: float,
m: int,
dim: int,
) -> Float32[Array, " n_groups m"]:
"""Vectorized spectral density for the squared exponential kernel.
Parameters
----------
alpha : Float32[Array, " n_groups"]
Amplitude parameter.
length : Float32[Array, " n_groups"]
Length parameter.
ell : float
Length scale.
m : int
Number of eigenfunctions.
dim : int
Dimension of the input space.
"""
# Define the an array of parameters we want to vectorize over.
theta = jnp.stack([alpha, length], axis=0)
return vmap(
lambda theta: diag_spectral_density_squared_exponential(
alpha=theta[0], # alpha,
length=theta[1], # length,
ell=ell,
m=m,
dim=dim,
),
in_axes=-1,
)(theta)Let’s verify the implementation by computing the spectral density for different values of the hyperparameters:
- Constant of ones.
- Linear increasing.
# Set fixed parameters
ell = 1.2
m = 10
dim = 1
# Set different values for the hyperparameters
## Constant of ones
ones_array = jnp.ones(n_groups)
## Linear increasing
arange_array = 0.5 * jnp.arange(start=1, stop=n_groups + 1, step=1)
fig, axes = plt.subplots(
nrows=2, ncols=2, figsize=(12, 8), sharex=True, sharey=True, layout="constrained"
)
# Compute the spectral density for the different combinations of hyperparameters
for i, alpha in enumerate([ones_array, arange_array]):
for j, length in enumerate([ones_array, arange_array]):
spd = jnp.sqrt(
diag_spectral_density_squared_exponential_vectorized(
alpha=alpha,
length=length,
ell=ell,
m=m,
dim=dim,
)
)
assert spd.shape == (n_groups, m)
ax = axes[i, j]
alpha_label = "ones" if i == 0 else "arange"
length_label = "ones" if j == 0 else "arange"
for g in range(n_groups):
ax.plot(spd[g], c=f"C{g}", marker="o", markersize=5, label=f"group {g}")
ax.set_title(f"alpha: {alpha_label}, length: {length_label}")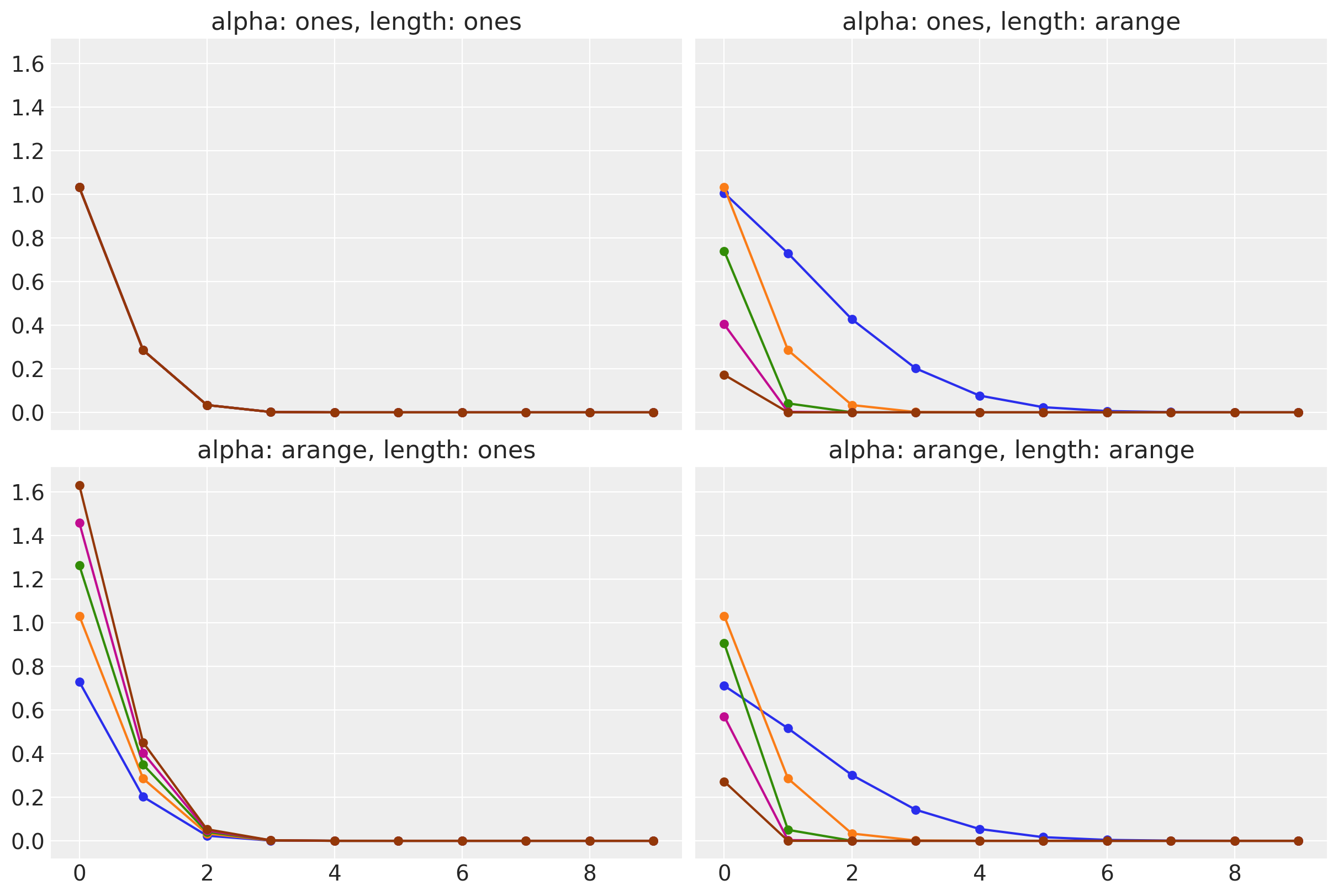
The results are as expected:
- In the upper left corner, we have the spectral density for a constant amplitude and length scale. All values of the spectral density are the same.
- In the upper right corner, we have the spectral density for a constant amplitude and a linear increasing length scale. All values of the spectral density are different. The smaller the length scale, the wider its “support”.
- In the lower left corner, we have the spectral density for a linear increasing amplitude and length scale. All values of the spectral density are different. The smaller larger the amplitude, the larger the spectral density.
- In the lower right corner, we have the spectral density for a linear increasing amplitude and length scale. All values of the spectral density are different and consistent with the previous cases.
In addition, we can test this last case explicitly by testing the vectorization results against the scalar version.
# Compute the spectral density for the linear increasing amplitude and length scale.
spd = jnp.sqrt(
diag_spectral_density_squared_exponential_vectorized(
alpha=arange_array,
length=arange_array,
ell=ell,
m=m,
dim=dim,
)
)
# Compare the vectorized results against the scalar version
for i, (single_alpha, single_length) in enumerate(
zip(arange_array, arange_array, strict=True)
):
assert jnp.array_equal(
spd[i],
jnp.sqrt(
diag_spectral_density_squared_exponential(
alpha=single_alpha, length=single_length, ell=ell, m=m, dim=dim
)
),
)Everything works as expected!
Model Specification
We are ready to work out the model specification.
Priors
First let’s think about the priors. Looking into the data we see that the range of the training data in between 0.1 and 1.0. Hence, in order to capture the global structure of the data, a length scale of around \(0.1\) is a good starting point. On the other hand, the amplitude of the data is around \(5.0\). Hence, we can use a prior that is centered around \(5.0\).
Before setting the priors concretely, let’s also think about the model structure. As we want to ensure the global GP captures most of the variance, we will assume that the group-specific length scales are deviations from the global length scale. We achieve this by using a ZeroSumNormal distribution. To ensure positive length scales, we will use a softplus link function.
fig, ax = plt.subplots(figsize=(8, 7))
x_range = jnp.linspace(-3, 5, 100)
ax.plot(x_range, softplus(x_range), label="Softplus")
ax.plot(x_range, x_range, c="black", ls="dashed", label="Identity")
ax.axhline(y=0, c="gray", ls="dotted", label="Zero")
ax.legend()
ax.set_title("Softplus Link Function", fontsize=18, fontweight="bold");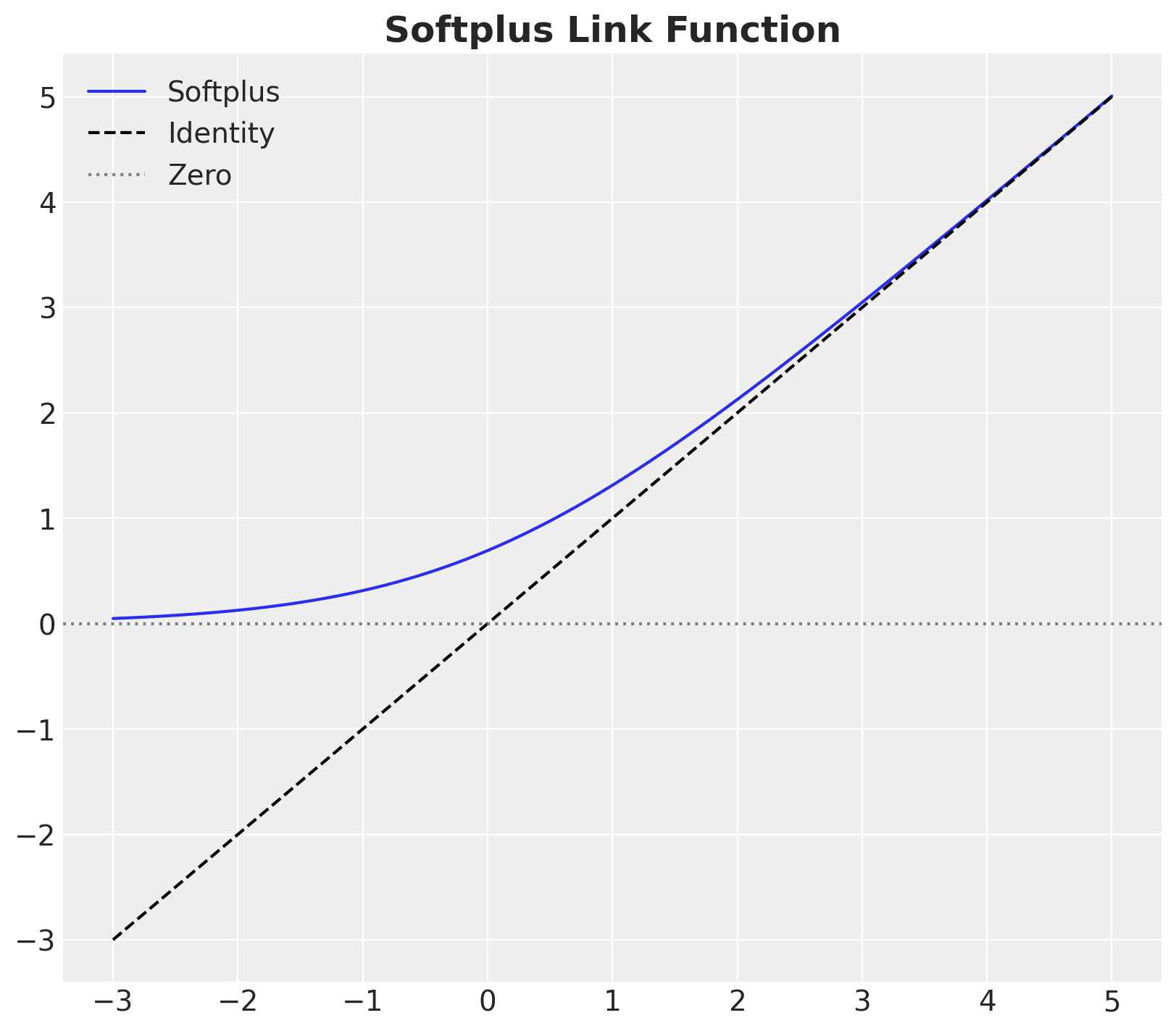
We use normal likelihoods on the transformed spaces around the heuristic values.
rng_key, rng_subkey = random.split(rng_key)
softplus_log_amplitude = softplus(
jnp.log(100) + 1 * random.normal(rng_subkey, shape=(10_000,))
)
softplus_log_length = softplus(
jnp.log(0.03) + 0.3 * random.normal(rng_subkey, shape=(10_000,))
)
fig, ax = plt.subplots(
nrows=2, ncols=1, figsize=(12, 9), sharex=False, sharey=False, layout="constrained"
)
az.plot_dist(
np.array(softplus_log_amplitude), color="C0", fill_kwargs={"alpha": 0.4}, ax=ax[0]
)
ax[0].set_title("Softplus Prior for the log-amplitude", fontsize=18, fontweight="bold")
az.plot_dist(
np.array(softplus_log_length), color="C1", fill_kwargs={"alpha": 0.4}, ax=ax[1]
)
ax[1].set_title("Softplus Prior for the log-length", fontsize=18, fontweight="bold");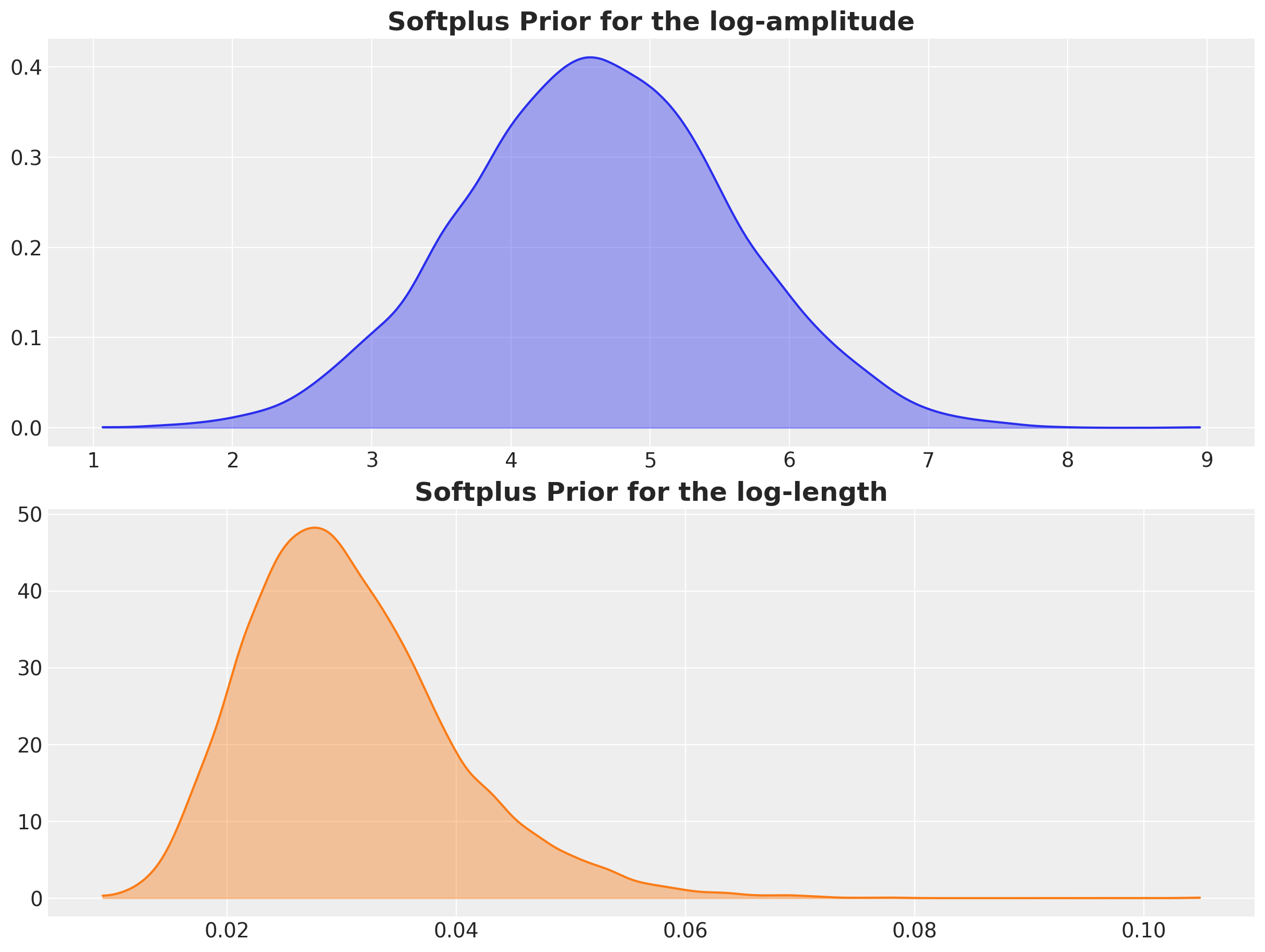
Parametrization
Having set priors on the key GP parameters, we can now work out the model parametrization. We do this by defining the global and group-specific latent mean GP components.
We start by defining the global latent mean GP component.
def priors_global_latent_mean_gp(
log_alpha_global: Float32[Array, ""], log_length_global: Float32[Array, ""]
) -> tuple[Float32[Array, ""], Float32[Array, ""]]:
"""Global latent mean GP priors.
Given the log-amplitude and log-length, we compute the amplitude and length
through a softplus link function.
Parameters
----------
log_alpha_global : Float32[Array, ""]
Log-amplitude prior.
log_length_global : Float32[Array, ""]
Log-length prior.
Returns
-------
tuple[Float32[Array, ""], Float32[Array, ""]]
Global amplitude and length.
"""
alpha_global = numpyro.deterministic("alpha_global", softplus(log_alpha_global))
length_global = numpyro.deterministic("length_global", softplus(log_length_global))
return alpha_global, length_global
def global_latent_mean_gp(
x: Float32[Array, " n"],
alpha_global: Float32[Array, ""],
length_global: Float32[Array, ""],
ell: float,
m_global: int,
) -> Float32[Array, " n"]:
"""Global latent mean GP.
Given the global amplitude and length, we compute the global latent mean GP
component using the HSGP approximation.
Parameters
----------
x : Float32[Array, " n"]
Input domain data.
alpha_global : Float32[Array, ""]
Global amplitude.
length_global : Float32[Array, ""]
Global length.
ell : float
Interval length.
m_global : int
Number of eigenfunctions in the approximation.
Returns
-------
Float32[Array, " n"]
Global latent mean GP component.
"""
return numpyro.deterministic(
"f_global",
hsgp_squared_exponential(
x=x,
alpha=alpha_global,
length=length_global,
ell=ell,
m=m_global,
),
)We continue by defining the group-specific offset component.
def priors_group_delta_gp(
n_groups: int,
log_alpha_global: Float32[Array, ""],
log_length_global: Float32[Array, ""],
) -> tuple[Float32[Array, " n_groups"], Float32[Array, " n_groups"]]:
"""Group-specific latent offset GP priors.
These components are used to capture the group-specific deviations from
the global latent mean GP component.
Given the log-amplitude and log-length of the global latent mean GP component,
we compute the amplitude and length of the group-specific latent offset GP
component using a zero-sum normal distribution.
Parameters
----------
n_groups : int
Number of groups.
log_alpha_global : Float32[Array, ""]
Log-amplitude prior.
log_length_global : Float32[Array, ""]
Log-length prior.
Returns
-------
tuple[Float32[Array, " n_groups"], Float32[Array, " n_groups"]]
Group-specific amplitude and length.
"""
log_alpha_groups = log_alpha_global + numpyro.sample(
"log_alpha_groups", dist.ZeroSumNormal(scale=3.0, event_shape=(n_groups,))
)
log_length_groups = log_length_global + numpyro.sample(
"log_length_groups", dist.ZeroSumNormal(scale=2.0, event_shape=(n_groups,))
)
alpha_groups = numpyro.deterministic("alpha_groups", softplus(log_alpha_groups))
length_groups = numpyro.deterministic("length_groups", softplus(log_length_groups))
return alpha_groups, length_groups
def group_delta_gp(
x: Float32[Array, " n"],
alpha_groups: Float32[Array, " n_groups"],
length_groups: Float32[Array, " n_groups"],
ell: float,
m_groups: int,
) -> Float32[Array, " n_groups m_groups"]:
"""Group-specific latent offset GP.
Here we use the vectorized spectral density to compute the HSGP
approximation of the group-specific latent offset GP component.
Parameters
----------
x : Float32[Array, " n"]
Input domain data.
alpha_groups : Float32[Array, " n_groups"]
Group-specific amplitude.
length_groups : Float32[Array, " n_groups"]
Group-specific length.
ell : float
Interval length.
m_groups : int
Number of eigenfunctions in the approximation.
Returns
-------
Float32[Array, " n_groups m_groups"]
Group-specific latent mean GP component.
"""
# Compute the eigenfunctions of the Dirichlet Laplacian.
phi = eigenfunctions(x=x, ell=ell, m=m_groups)
# Compute the spectral density of the squared exponential kernel.
spd = jnp.sqrt(
diag_spectral_density_squared_exponential_vectorized(
alpha=alpha_groups, length=length_groups, ell=ell, m=m_groups, dim=1
)
)
# We use the non-centered parameterization of the approximate linear model.
with (
numpyro.plate("groups", n_groups, dim=-1),
numpyro.plate("group_basis", m_groups, dim=-2),
):
# Standard normal distributions to model the coefficients of the eigenfunctions.
beta_delta = numpyro.sample("beta_delta", dist.Normal(loc=0.0, scale=1.0))
# This is the final formula in the approximation.
return numpyro.deterministic("f_delta", (phi @ (spd.T * beta_delta)).T)We can bring these components together to define the model.
def model(
x: Float32[Array, " n"], n_groups: int, ell: float, m_global: int, m_groups: int
) -> None:
"""Hierarchical HSGP model.
This model is a hierarchical model that captures the global structure of the
data and the group-specific deviations from the global structure.
y = f_global + f_delta + noise
The global structure is captured by the global latent mean GP component, while
the group-specific deviations are captured by the group-specific latent
offset GP component.
We also include a hierarchical Student-T likelihood to model the likelihood
of the data.
Parameters
----------
x : Float32[Array, " n"]
Input domain data.
n_groups : int
Number of groups.
ell : float
Interval length.
m_global : int
Number of eigenfunctions in the global latent mean GP.
m_groups : int
Number of eigenfunctions in the group-specific latent mean GP.
"""
log_alpha_global = numpyro.sample(
"log_alpha_global", dist.Normal(loc=jnp.log(10), scale=1)
)
log_length_global = numpyro.sample(
"log_length_global", dist.Normal(loc=jnp.log(0.03), scale=0.3)
)
alpha_global, length_global = priors_global_latent_mean_gp(
log_alpha_global=log_alpha_global,
log_length_global=log_length_global,
)
alpha_groups, length_groups = priors_group_delta_gp(
n_groups=n_groups,
log_alpha_global=log_alpha_global,
log_length_global=log_length_global,
)
nu = numpyro.sample("nu", dist.Gamma(concentration=10, rate=2.5))
scale_prior = numpyro.sample("scale_prior", dist.HalfNormal(scale=2.5))
with numpyro.plate("groups", n_groups, dim=-1):
scale = numpyro.sample("scale", dist.HalfNormal(scale=scale_prior))
f_global = scope(global_latent_mean_gp, prefix="global", divider="_")(
x=x,
alpha_global=alpha_global,
length_global=length_global,
ell=ell,
m_global=m_global,
)
f_delta = group_delta_gp(
x=x,
alpha_groups=alpha_groups,
length_groups=length_groups,
ell=ell,
m_groups=m_groups,
)
f_group = numpyro.deterministic("f_group", f_global + f_delta)
numpyro.sample("obs", dist.StudentT(df=nu, loc=f_group, scale=scale[..., None]))There are only three parameters we need to set:
- The interval length: We set it to \(1.5\) based on the range of the data.
- The number of eigenfunctions in the global latent mean GP.
- The number of eigenfunctions in the group-specific latent mean GP.
For this specific example, we want to have a regularized global latent mean GP component and we expect more variation (wiggliness) in the group-specific latent mean GP component. Therefore, we set the number of eigenfunctions in the global latent mean GP to \(20\) and \(30\) in the group-specific latent mean GP.
# Set fixed parameters.
ell = 1.1
m_global = 12
m_groups = 28Let’s visualize the model structure.
numpyro.render_model(model, model_args=(x_train, n_groups, ell, m_global, m_groups))
Prior Predictive Check
Before fitting the model, we perform a prior predictive check to see if the model is working as expected.
prior_predictive = Predictive(model, num_samples=1_000, return_sites=["obs"])
rng_key, rng_subkey = random.split(rng_key)
prior_predictive_samples = prior_predictive(
rng_subkey, x_train, n_groups, ell, m_global, m_groups
)
prior_predictive_idata = az.from_numpyro(
prior=prior_predictive_samples,
coords={"x": x_train, "group": jnp.arange(n_groups)},
dims={"f": ["group", "x"], "obs": ["group", "x"]},
)fig, ax = plt.subplots()
for draw in range(1):
ax.plot(
x_train,
prior_predictive_idata["prior"]["obs"].sel(chain=0, draw=draw).T,
c="gray",
alpha=0.5,
)
for i, hdi_prob in enumerate([0.94, 0.5]):
az.plot_hdi(
x_train,
prior_predictive_idata["prior"]["obs"].sel(group=0),
fill_kwargs={
"color": "gray",
"alpha": 0.4 + 0.2 * i,
"label": f"HDI {hdi_prob}",
},
hdi_prob=hdi_prob,
smooth=True,
ax=ax,
)
for g in range(n_groups):
ax.plot(x_train, y_train[g], c=f"C{g}", label=f"group {g}")
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.05), ncol=n_groups + 2)
ax.set_title("Prior predictive check", fontsize=18, fontweight="bold");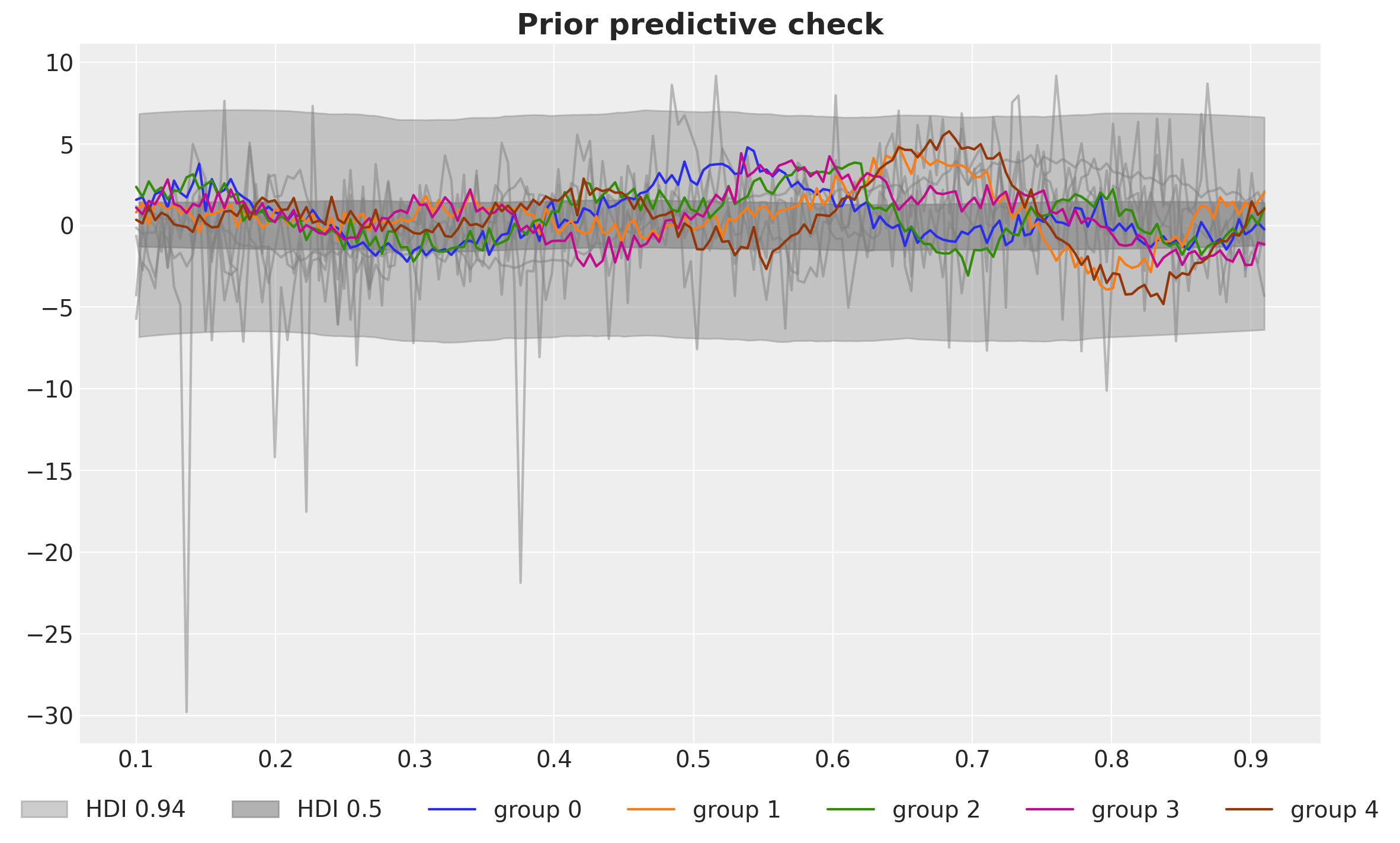
The range of prior predictive distributions loos very reasonable.
Condition and Fit the Model
We now proceed to condition the model on the data and fit using NUTS.
# Condition the model on the training data.
conditioned_model = condition(model, data={"obs": y_train})
# Define the sampler.
sampler = NUTS(conditioned_model, target_accept_prob=0.9)
mcmc = MCMC(sampler, num_warmup=1_500, num_samples=4_000, num_chains=4)
# Run the sampler.
rng_key, rng_subkey = random.split(rng_key)
mcmc.run(rng_subkey, x_train, n_groups, ell, m_global, m_groups)We store the results in an arviz.InferenceData object.
idata = az.from_numpyro(
posterior=mcmc,
coords={
"x": x_train,
"group": jnp.arange(n_groups),
"m_global": jnp.arange(m_global),
"m_groups": jnp.arange(m_groups),
},
dims={
"log_alpha_groups": ["group"],
"log_length_groups": ["group"],
"alpha_groups": ["group"],
"length_groups": ["group"],
"global_beta": ["m_global"],
"beta_delta": ["m_groups", "group"],
"f_delta": ["group", "x"],
"global_f_global": ["x"],
"f_group": ["group", "x"],
"scale": ["group"],
"obs": ["group", "x"],
},
)Model Diagnostics
Let’s look into some diagnostics.
# Check for divergences.
idata["sample_stats"].diverging.sum().item()0az.summary(
idata,
var_names=[
"log_alpha_global",
"log_length_global",
"log_alpha_groups",
"log_length_groups",
"scale_prior",
"scale",
"nu",
],
)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| log_alpha_global | 3.427 | 0.610 | 2.323 | 4.581 | 0.005 | 0.004 | 15504.0 | 12028.0 | 1.0 |
| log_length_global | -3.657 | 0.206 | -4.035 | -3.262 | 0.002 | 0.001 | 15504.0 | 12921.0 | 1.0 |
| log_alpha_groups[0] | -1.193 | 1.385 | -3.609 | 1.480 | 0.012 | 0.009 | 13680.0 | 12792.0 | 1.0 |
| log_alpha_groups[1] | -0.343 | 1.396 | -2.738 | 2.416 | 0.011 | 0.010 | 15607.0 | 12898.0 | 1.0 |
| log_alpha_groups[2] | 1.008 | 1.470 | -1.574 | 3.859 | 0.011 | 0.010 | 19282.0 | 12357.0 | 1.0 |
| log_alpha_groups[3] | -0.685 | 1.421 | -3.204 | 2.012 | 0.012 | 0.010 | 15865.0 | 12375.0 | 1.0 |
| log_alpha_groups[4] | 1.213 | 1.380 | -1.343 | 3.767 | 0.010 | 0.009 | 18143.0 | 11975.0 | 1.0 |
| log_length_groups[0] | 0.240 | 0.688 | -1.097 | 1.277 | 0.007 | 0.005 | 9835.0 | 11771.0 | 1.0 |
| log_length_groups[1] | -0.112 | 0.581 | -1.165 | 0.926 | 0.005 | 0.004 | 16531.0 | 12678.0 | 1.0 |
| log_length_groups[2] | -0.367 | 0.474 | -1.198 | 0.545 | 0.003 | 0.003 | 19403.0 | 11485.0 | 1.0 |
| log_length_groups[3] | -0.185 | 0.627 | -1.370 | 0.898 | 0.005 | 0.004 | 13773.0 | 11610.0 | 1.0 |
| log_length_groups[4] | 0.424 | 0.465 | -0.461 | 1.242 | 0.004 | 0.003 | 12852.0 | 12695.0 | 1.0 |
| scale_prior | 0.598 | 0.282 | 0.242 | 1.078 | 0.002 | 0.002 | 30457.0 | 10647.0 | 1.0 |
| scale[0] | 0.449 | 0.031 | 0.392 | 0.509 | 0.000 | 0.000 | 30508.0 | 13253.0 | 1.0 |
| scale[1] | 0.449 | 0.030 | 0.395 | 0.506 | 0.000 | 0.000 | 32087.0 | 12929.0 | 1.0 |
| scale[2] | 0.428 | 0.029 | 0.376 | 0.484 | 0.000 | 0.000 | 31833.0 | 11601.0 | 1.0 |
| scale[3] | 0.458 | 0.030 | 0.403 | 0.515 | 0.000 | 0.000 | 29545.0 | 12516.0 | 1.0 |
| scale[4] | 0.402 | 0.028 | 0.351 | 0.454 | 0.000 | 0.000 | 29722.0 | 13103.0 | 1.0 |
| nu | 7.415 | 1.247 | 5.191 | 9.774 | 0.008 | 0.006 | 26861.0 | 13376.0 | 1.0 |
There are no divergences and all the rhat values are essentially \(1.0\).
We can also look into the posterior distributions.
_ = az.plot_trace(
data=idata,
var_names=[
"log_alpha_global",
"log_length_global",
"log_alpha_groups",
"log_length_groups",
"alpha_global",
"length_global",
"alpha_groups",
"length_groups",
"scale_prior",
"scale",
"nu",
],
kind="rank_bars",
compact=True,
backend_kwargs={"figsize": (12, 18), "layout": "constrained"},
)
plt.gcf().suptitle("Model Posteriors", fontsize=18, fontweight="bold");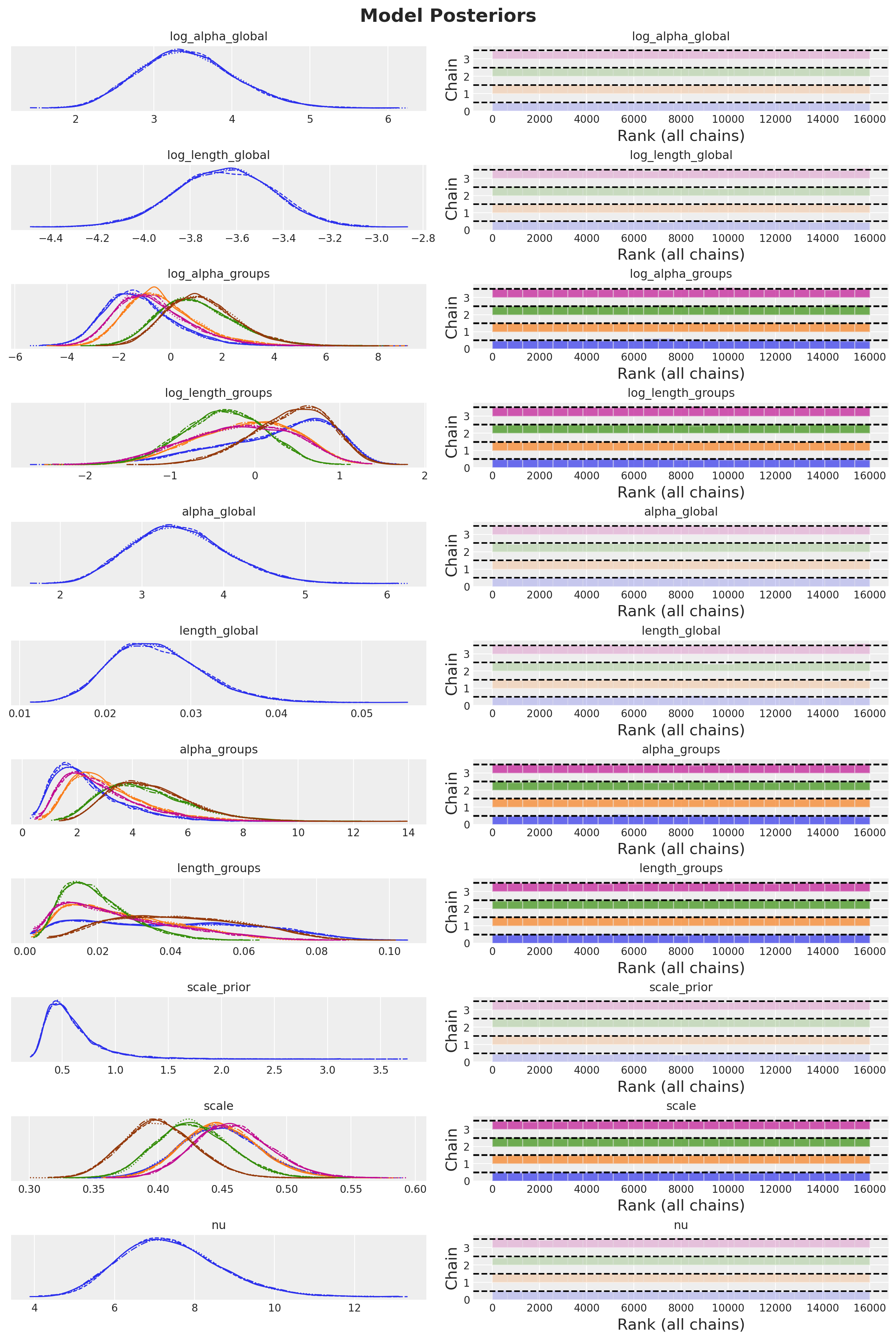
Posterior Predictive Check
We can now study the posterior predictive distribution and compare it against the true data. First, we sample and store the posterior predictive samples.
posterior_predictive = Predictive(
model, posterior_samples=mcmc.get_samples(), return_sites=["obs"]
)
rng_key, rng_subkey = random.split(rng_key)
posterior_predictive_samples = posterior_predictive(
rng_subkey, x_train, n_groups, ell, m_global, m_groups
)
idata.extend(
az.from_numpyro(
posterior_predictive=posterior_predictive_samples,
coords={"x": x_train, "group": jnp.arange(n_groups)},
dims={"f_group": ["group", "x"], "obs": ["group", "x"]},
)
)Next, we can start by visualizing the posterior predictive distribution of the global latent mean GP component.
fig, ax = plt.subplots()
for i, hdi_prob in enumerate([0.94, 0.5]):
az.plot_hdi(
x_train,
idata["posterior"]["global_f_global"],
fill_kwargs={
"color": "gray",
"alpha": 0.4 + 0.2 * i,
"label": f"HDI {hdi_prob:.0%}",
},
ax=ax,
hdi_prob=hdi_prob,
smooth=True,
)
ax.plot(x_train, f_train[0], c="black", lw=4, label="Mean function")
ax.legend(loc="lower left", ncol=3)
ax.set_title(
"Posterior predictive check - Latent Global Mean GP", fontsize=18, fontweight="bold"
);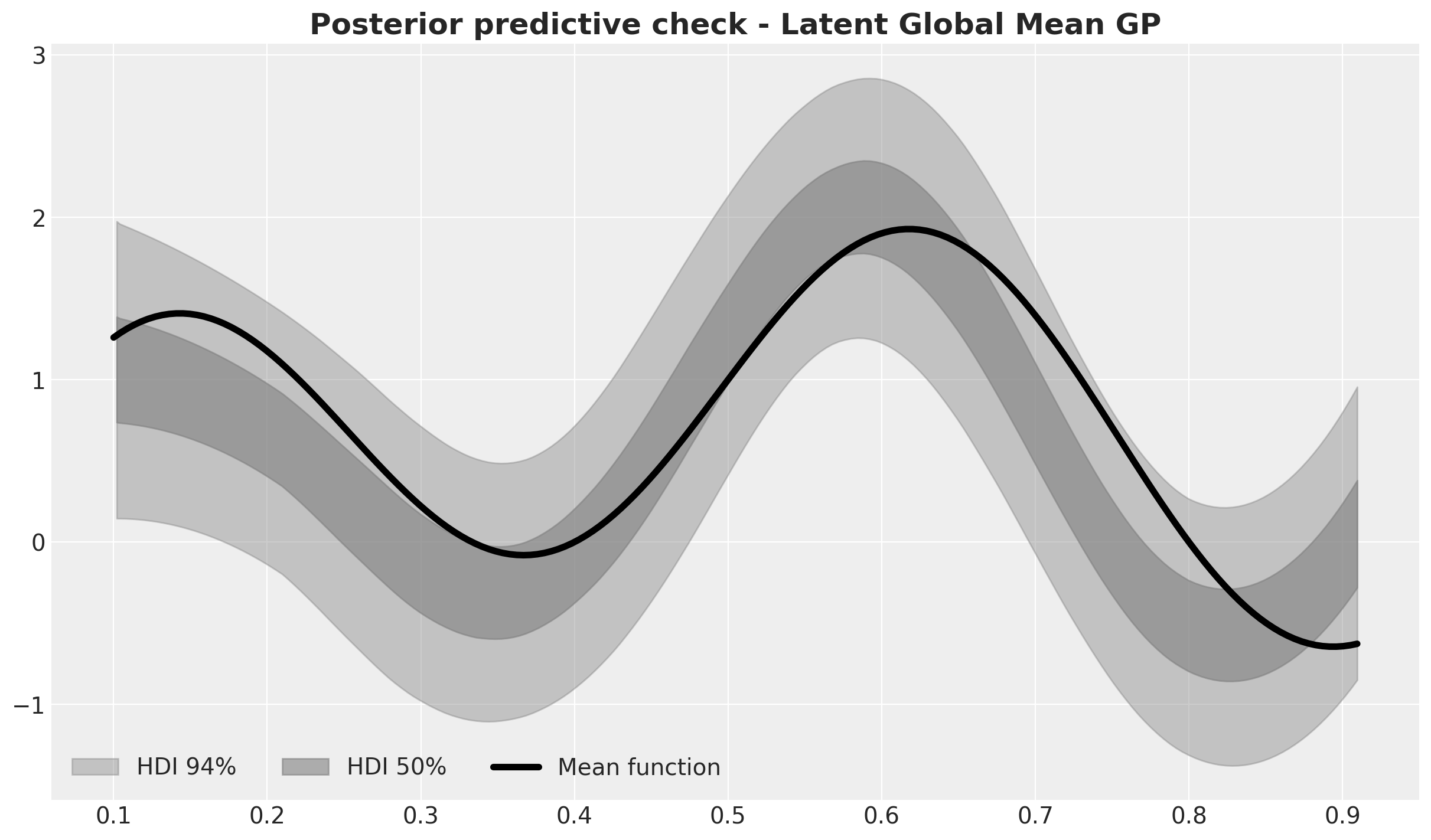
The fit is not perfect but it is a very good approximation of the true mean function.
We now compare it against the posterior predictive distribution of the group-specific observations.
fig, axes = plt.subplots(
nrows=n_groups + 1,
ncols=1,
figsize=(12, 3 * (n_groups + 1)),
sharex=True,
sharey=True,
layout="constrained",
)
for i, hdi_prob in enumerate([0.94, 0.5]):
az.plot_hdi(
x_train,
idata["posterior"]["global_f_global"],
fill_kwargs={
"color": "gray",
"alpha": 0.4 + 0.2 * i,
"label": f"HDI {hdi_prob:.0%}",
},
ax=axes[0],
hdi_prob=hdi_prob,
smooth=True,
)
axes[0].plot(x_train, f_train[0], c="black", lw=4, label="Mean function")
axes[0].legend(loc="lower left", ncol=3)
for group in range(n_groups):
for i, hdi_prob in enumerate([0.94, 0.5]):
ax = axes[group + 1]
az.plot_hdi(
x_train,
idata["posterior_predictive"]["obs"].sel(group=group),
fill_kwargs={
"color": f"C{group}",
"alpha": 0.2 + 0.2 * i,
"label": f"HDI {hdi_prob:.0%}",
},
hdi_prob=hdi_prob,
smooth=True,
ax=ax,
)
ax.plot(x_train, y_train[group], c=f"C{group}", label=f"group {group}")
ax.legend(loc="lower left", ncol=3)
fig.suptitle("Posterior predictive check", fontsize=18, fontweight="bold");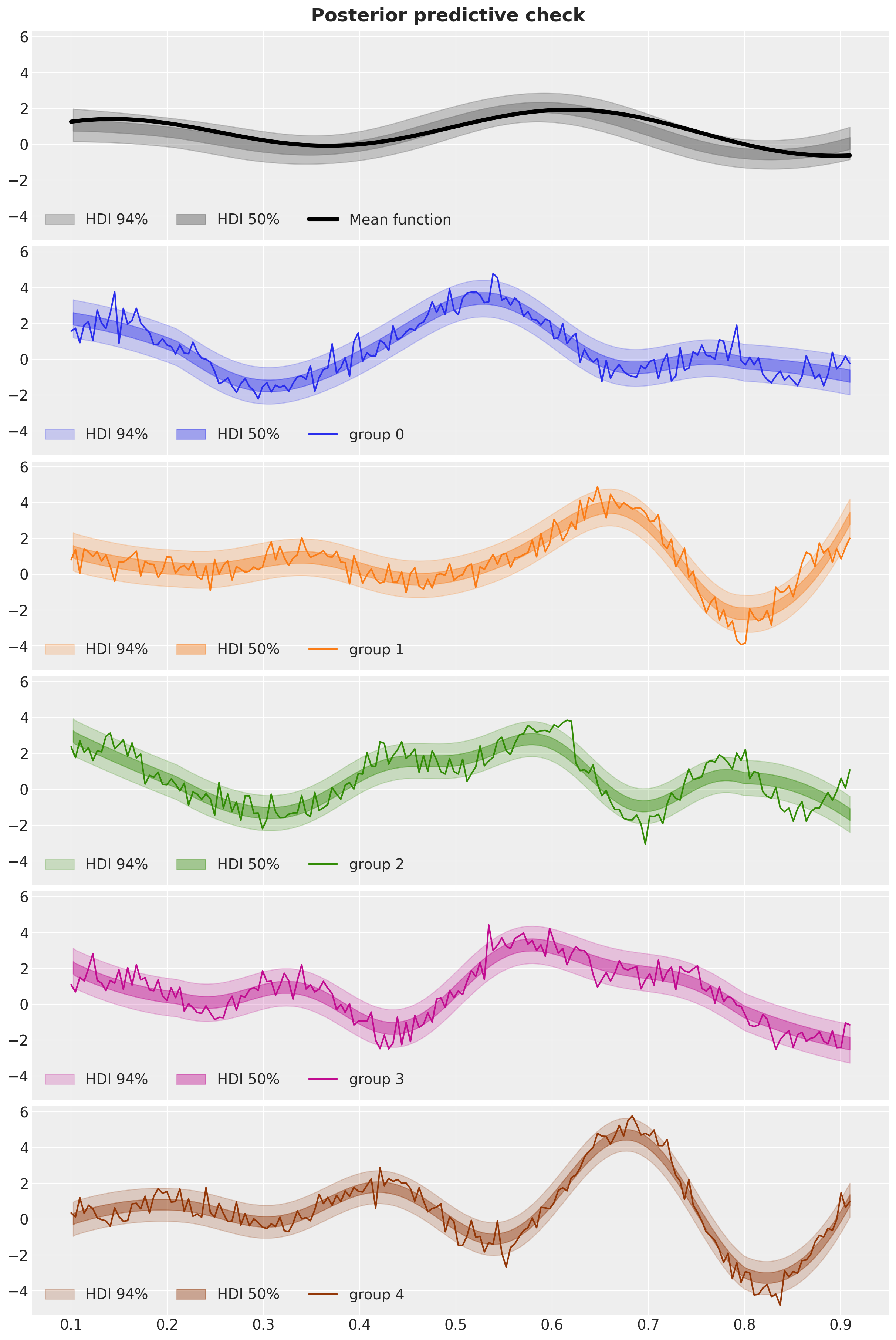
We see that the model is able to capture the global structure of the data and the group-specific deviations.
As a result, the inferred offsets (deltas) are also good approximations of the true offsets.
fig, axes = plt.subplots(
nrows=n_groups,
ncols=1,
figsize=(12, 3 * n_groups),
sharex=True,
sharey=True,
layout="constrained",
)
for group in range(n_groups):
for i, hdi_prob in enumerate([0.94, 0.5]):
az.plot_hdi(
x_train,
idata["posterior"]["f_delta"].sel(group=group),
fill_kwargs={
"color": f"C{group}",
"alpha": 0.2 + 0.2 * i,
"label": f"HDI {hdi_prob:.0%}",
},
hdi_prob=hdi_prob,
smooth=True,
ax=axes[group],
)
axes[group].plot(x_train, f_g_train[group], c=f"C{group}", label=f"group {group}")
axes[group].legend(loc="lower left", ncol=3)
fig.suptitle("Posterior predictive check", fontsize=18, fontweight="bold");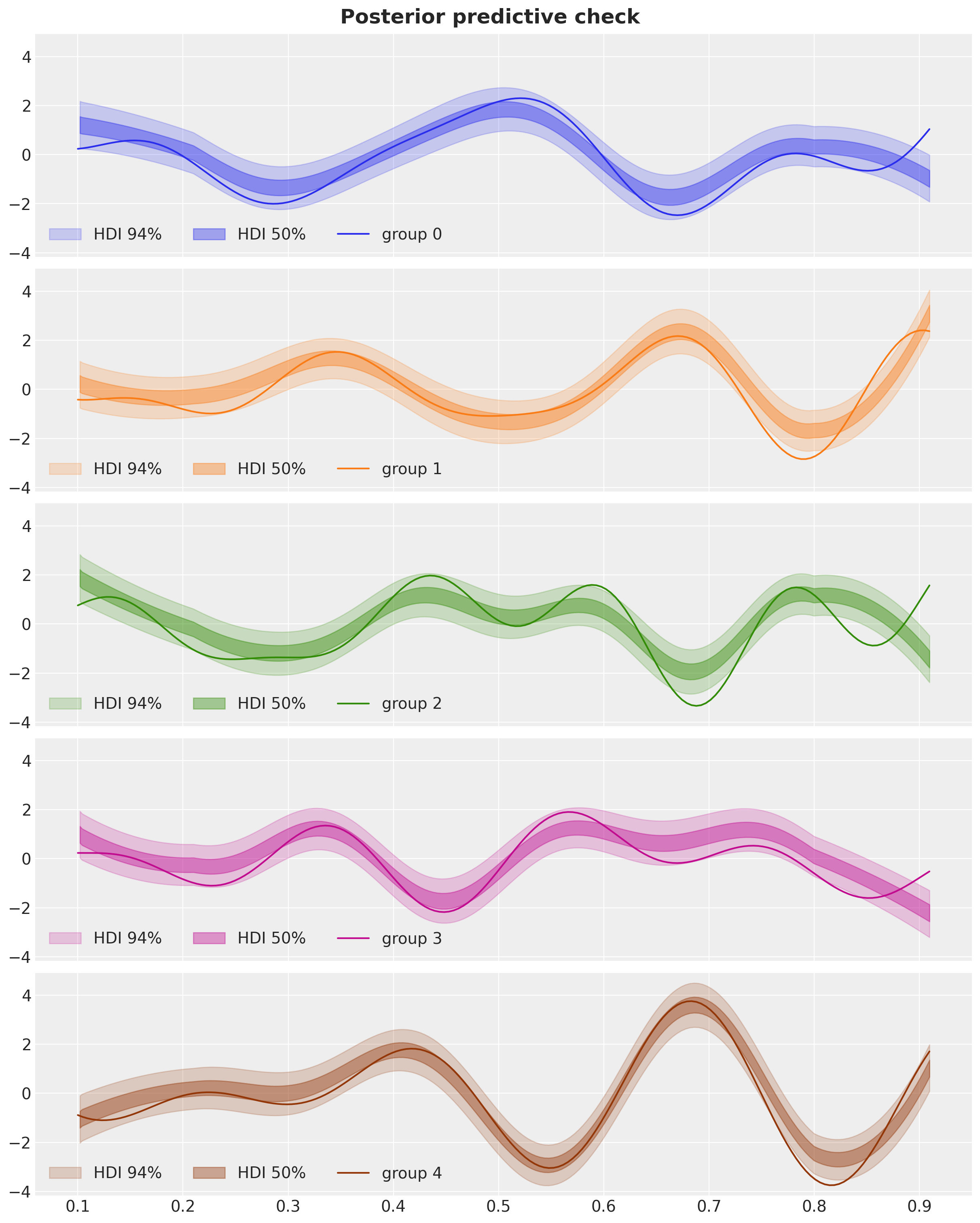
Out-of-Sample Prediction
Finally, we can generate predictions for the test data.
rng_key, rng_subkey = random.split(rng_key)
test_posterior_predictive_samples = posterior_predictive(
rng_subkey, x, n_groups, ell, m_global, m_groups
)
idata.extend(
az.from_numpyro(
predictions=test_posterior_predictive_samples,
coords={"x": x, "group": jnp.arange(n_groups)},
pred_dims={"f_group": ["group", "x"], "obs": ["group", "x"]},
num_chains=4,
)
)Let’s see the results:
fig, axes = plt.subplots(
nrows=n_groups,
ncols=1,
figsize=(12, 3 * n_groups),
sharex=True,
sharey=True,
layout="constrained",
)
for group in range(n_groups):
for i, hdi_prob in enumerate([0.94, 0.5]):
ax = axes[group]
az.plot_hdi(
x,
idata["predictions"]["obs"].sel(group=group),
fill_kwargs={
"color": f"C{group}",
"alpha": 0.2 + 0.2 * i,
"label": f"HDI {hdi_prob:.0%}",
},
hdi_prob=hdi_prob,
smooth=True,
ax=ax,
)
ax.plot(x, y[group], c=f"C{group}", label=f"group {group}")
ax.axvline(x=x_test[0], c="gray", ls="dashed", label="train/test split")
ax.legend(loc="lower left", ncol=4)
fig.suptitle("Posterior predictive check", fontsize=18, fontweight="bold");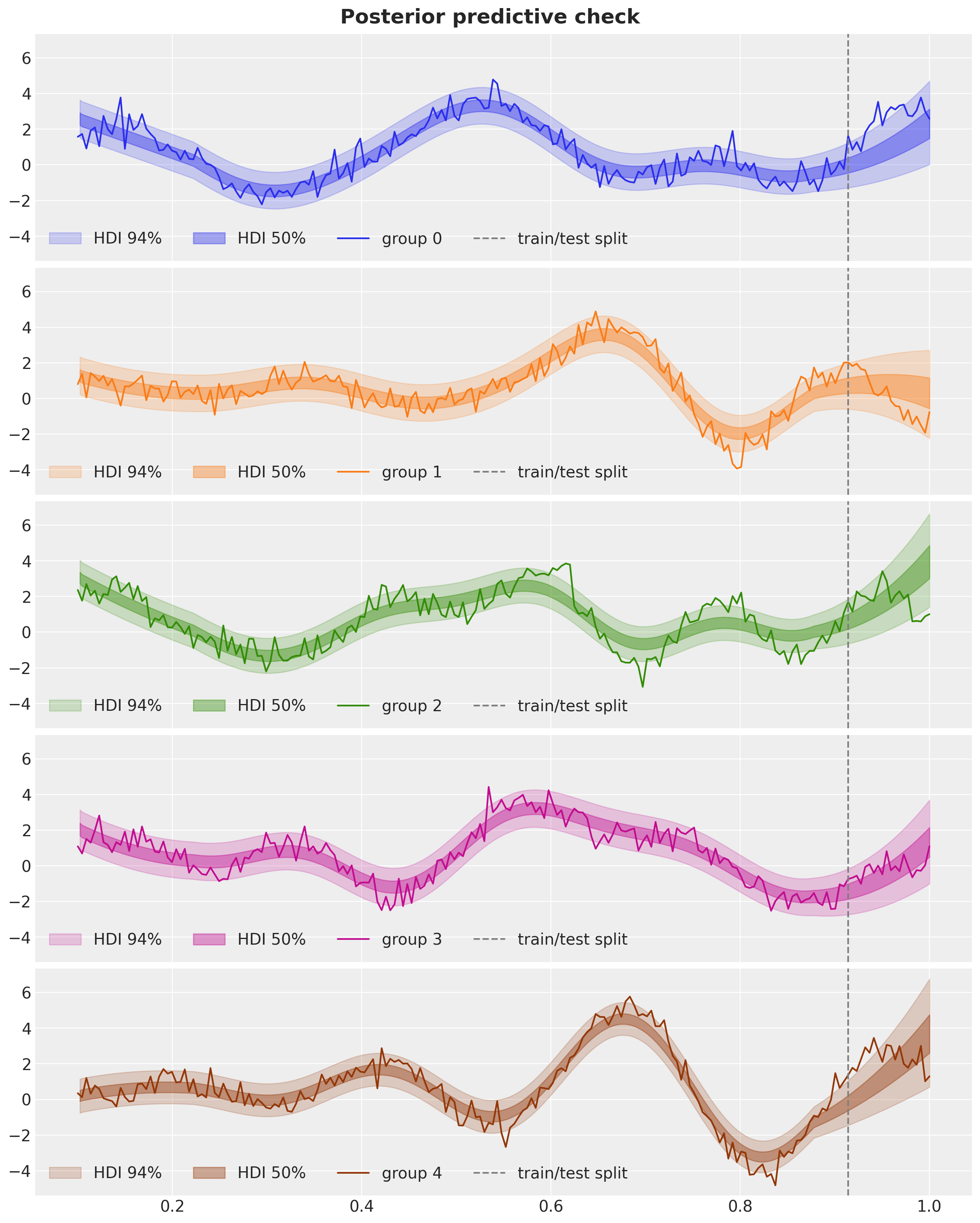
For short-term out-of-sample predictions the models does an ok job. However, these models are not the best for long-term predictions.
We hope this simulated example helps you to understand how to implement a hierarchical HSGP model in NumPyro. Once we have this component in place, we can easily integrate it into a more complex model like a time-varying coefficient model.