In the blog post “Notes on Exponential Smoothing with NumPyro” we implemented the damped Holt-Winters model in the component form of Hyndman & Athanasopoulos, FPP3, §8.3. A very nice observation was raised by @theorashid in issue #193: when we forecast with the component-form model the credible intervals barely widen across the horizon. The reason is subtle but important. Quoting the issue:
The models are written in component form, as in Hyndman 8.3. However, when we fitted this model, we found the error bars didn’t increase as much as expected. My explanation for this is that the variance from
predis the same around each data point. And this variance isn’t pushed forward to form a cone in the same way an autoregressive model does. The increasing error we see I think is entirely from the variability in the coefficients.We rewrote the model from component form into state space form, which is introduced in 8.5. It looks like the component form is just a “smoothing formula”, whereas this state space form is a proper stochastic process that gets more uncertain over the forecast horizon. Anyway, when I fitted it, the uncertainty intervals grew and looked better than before.
This notebook addresses that point: we re-implement the damped Holt-Winters model using the innovations state-space (a.k.a. single-source-of-error, SSOE) representation of FPP3 §8.5, specifically the ETS(A, A_d, A) model: additive error, additive damped trend, additive seasonality. The same random innovation \(\varepsilon_t\) drives both the observation equation and the state transitions, so during forecasting (when pred is sampled rather than observed) the sampled innovation feeds back into the level, trend and seasonal states and the forecast uncertainty grows naturally over the horizon.
What changes versus the component-form post
Concretely, compared to the original implementation the SSOE reformulation boils down to a handful of localised changes, all inside the model function, everything outside it (synthetic data, train-test split, inference helpers, ArviZ integration, plot style) stays the same:
Unified transition function. In the original post the state updates inside
transition_fnwere written in the component form and driven by the observed \(y_t\) (via terms like \(\alpha \, (y_t - s_{t-m})\)). Here they are rewritten around a single innovationerror = pred - mu, the level, trend and seasonal equations are all updated by the sameerror. That is the operational meaning of the “single source of error” in the remark above.No
jnp.where(t < t_max, ...)branching. The component-form model needed to “freeze” the state updates during forecasting (because feeding the sampledpredback through the component-form updates would double-count the emission noise). In the SSOE form training and forecasting use the exact same recursion, the only difference is whetherpredis conditioned on data or sampled from \(\text{Normal}(\mu_t, \sigma)\), so the branch disappears. Thid is a much transparent implementation.No explicit \(\phi_h = \phi + \phi^2 + \cdots + \phi^h\) sum. The original post computed this multi-step damping factor inside a
fori_loopat forecast time. Here the geometric decay emerges naturally from iterating \(b_t = \phi \, b_{t-1} + \beta \, \varepsilon_t\) insidescan, so the explicit loop is gone.Reverse-mode autodiff. Because there is no
fori_loopwe no longer needforward_mode_differentiation=TrueinNUTS, the default (reverse-mode) path, which is the faster and canonical one in NumPyro, now works.Slightly retuned priors. We keep the shape of the priors but tighten a few of them (Beta(5, 5) on the smoothing parameters, data-anchored \(l_0\), a realistic-scale \(b_0\), a tighter noise scale). This is a sampling-geometry fix, not a modelling change, see the model-definition section below for the full description.
Changes (1) and (2) together are what makes the forecast uncertainty grow naturally over the horizon. Once every state equation is driven by the same sampled innovation \(\varepsilon_t\), iterating the recursion during forecasting propagates that innovation into \(l_t\), \(b_t\), \(s_t\), and the posterior predictive fans out into a proper cone. This is precisely the behaviour the component-form implementation was missing.
Thanks to @theorashid for the great feedback! 🙌
Prepare Notebook
from collections.abc import Callable
import arviz as az
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpyro
import numpyro.distributions as dist
import preliz as pz
from jax import Array, random
from numpyro.contrib.control_flow import scan
from numpyro.infer import MCMC, NUTS, Predictive
from pydantic import BaseModel, Field
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
numpyro.set_host_device_count(n=4)
rng_key = random.PRNGKey(seed=42)
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"Generate Synthetic Data
We use the same synthetic series as in the original post so that the two sets of forecasts can be compared directly: a cosine seasonal component plus a logarithmic trend, with additive Gaussian noise.
n_seasons = 15
t = jnp.linspace(start=0, stop=n_seasons + 1, num=(n_seasons + 1) * n_seasons)
rng_key, rng_subkey = random.split(key=rng_key)
y = jnp.cos(2 * jnp.pi * t) + jnp.log(t + 1) + 0.2 * random.normal(rng_subkey, t.shape)
fig, ax = plt.subplots()
ax.plot(t, y)
ax.set(xlabel="time", ylabel="y", title="Time Series Data");
Train - Test Split
n = y.size
prop_train = 0.8
n_train = round(prop_train * n)
y_train = y[:n_train]
t_train = t[:n_train]
y_test = y[n_train:]
t_test = t[n_train:]
fig, ax = plt.subplots()
ax.plot(t_train, y_train, color="C0", label="train")
ax.plot(t_test, y_test, color="C1", label="test")
ax.axvline(x=t_train[-1], c="black", linestyle="--")
ax.legend()
ax.set(xlabel="time", ylabel="y", title="Time Series Data Split");
From Component Form to State Space Form
For quick reference, the damped Holt-Winters model in component form (as in the original post) is
\[\begin{align*} \hat{y}_{t+h|t} = & \: l_t + \phi_h b_t + s_{t + h - m(k + 1)} \\ l_t = & \: \alpha(y_t - s_{t - m}) + (1 - \alpha)(l_{t-1} + \phi b_{t-1}) \\ b_t = & \: \beta^*(l_t - l_{t-1}) + (1 - \beta^*)\phi b_{t-1} \\ s_t = & \: \gamma(y_t - l_{t-1} - \phi b_{t-1}) + (1 - \gamma)s_{t-m} \end{align*}\]
with \(\phi_h = \phi + \phi^2 + \cdots + \phi^h\). The state updates are driven by the observed \(y_t\), which is fine for training but means the forecast distribution collapses to the (deterministic) recursion mu plus a single emission noise term. The emission noise is never fed back into \(l_t\), \(b_t\) or \(s_t\), so the forecast bands stay narrow.
The innovations state space (or SSOE) form of the same model, ETS(A, A_d, A), is the Gaussian linear state space system
\[\begin{align*} y_t &= l_{t-1} + \phi b_{t-1} + s_{t-m} + \varepsilon_t, \quad \varepsilon_t \sim \text{Normal}(0, \sigma) \\ l_t &= l_{t-1} + \phi b_{t-1} + \alpha \, \varepsilon_t \\ b_t &= \phi b_{t-1} + \beta \, \varepsilon_t \\ s_t &= s_{t-m} + \gamma \, \varepsilon_t \end{align*}\]
The same \(\varepsilon_t\) appears in every equation that is the “single source of error”. Two consequences matter for us:
- During training we condition
pred = y[t], so the innovation \(\varepsilon_t = y_t - \mu_t\) is exactly the one-step-ahead forecast error, and the state updates reduce to the familiar Kalman-style corrections. - During forecasting
predis sampled from \(\text{Normal}(\mu_t, \sigma)\); the sampled \(\varepsilon_t\) then propagates into \(l_t\), \(b_t\), \(s_t\) and drives the next step’s \(\mu\). The forecast distribution therefore fans out into a proper cone, precisely what we want.
A small reparameterisation note: \(\beta^\ast\) is the component-form trend smoothing (line 114), and \(\gamma^\ast = \gamma / (1 - \alpha)\) is the \([0, 1]\)-rescaling of the component-form seasonal smoothing (line 115, which carries the FPP3 admissibility constraint \(0 \le \gamma \le 1 - \alpha\)). Both live on \([0, 1]\) and map to the state-space coefficients via \[ \beta = \beta^\ast \, \alpha, \qquad \gamma = \gamma^\ast \, (1 - \alpha), \] so the priors are directly comparable with those in the original post. See FPP3 §8.5 for the derivation.
Remark: note that in the SSOE form we do not need the explicit \(\phi_h = \phi + \phi^2 + \cdots + \phi^h\) sum, and therefore no fori_loop and no forward_mode_differentiation=True. The geometric damping of the trend emerges naturally from iterating the transition \(b_t = \phi b_{t-1} + \beta \, \varepsilon_t\) inside scan.
Damped Holt-Winters State Space Model
The structural change versus the component-form implementation is entirely inside transition_fn. We do tighten a few of the priors, though, not because the original priors are “wrong”, but because the SSOE posterior has a very different geometry and the \(\text{Beta}(2, 2)\) / \(\text{Normal}(0, 1)\) / \(\text{HalfNormal}(1)\) priors of the original post place NUTS in high-curvature regions that produce divergences. The refinements below are aimed at sampling geometry only:
Smoothing parameters \(\alpha\), \(\beta^\ast\), \(\gamma^\ast\): \(\text{Beta}(2, 2) \to \text{Beta}(5, 5)\). The mode stays at \(0.5\) but the density at the boundaries goes from vanishing linearly (\(\text{Beta}(2, 2)\), density \(\propto x(1-x)\)) to vanishing like \(x^4\) (\(\text{Beta}(5, 5)\), density \(\propto x^4(1-x)^4\)), i.e. essentially flat near \(0\) and \(1\). This matters because the SSOE reparameterisation \(\beta = \alpha \, \beta^\ast\), \(\gamma = (1 - \alpha) \, \gamma^\ast\) creates funnels at \(\alpha = 0\) and \(\alpha = 1\): as \(\alpha \to 0\) the trend coefficient \(\beta\) collapses and \(\beta^\ast\) becomes locally unidentifiable (flat likelihood, non-zero prior gradient); symmetrically at \(\alpha \to 1\) for \(\gamma^\ast\). With \(\text{Beta}(2, 2)\) priors the sampler happily walks into those corners and diverges; \(\text{Beta}(5, 5)\) simply keeps it away.
Initial level \(l_0\): \(\text{Normal}(0, 1) \to \text{Normal}(y_0, 1)\). Anchoring on the first observation means the warmup does not have to walk \(l_0\) across the data scale before the smoothing parameters can be identified. The variance is unchanged, the prior is still weakly informative.
Initial trend \(b_0\): \(\text{Normal}(0.5, 1) \to \text{Normal}(0, 0.1)\). The original prior was centered at \(0.5\) and was much wider than any realistic one-step trend. With \(\phi\) small, \(b_0\) is only identified through the first few observations and the wide prior creates a long weakly-identified direction in the posterior.
Noise \(\sigma\): \(\text{HalfNormal}(1) \to \text{HalfNormal}(0.5)\). Still comfortably above the true noise scale of the synthetic data (\(\approx 0.2\)), but tighter, this breaks the \(\sigma\)–\(\alpha\) correlation (large \(\alpha\) + small \(\sigma\) and small \(\alpha\) + large \(\sigma\) give similar likelihoods) that the original wide prior left loose.
Damping \(\phi \sim \text{Beta}(2, 5)\) and the seasonal initials \(\text{Normal}(0, 1)\) are left unchanged. The trace of the original SSOE fit shows both are already well identified.
Lets visualize the difference between the two priors:
fig, ax = plt.subplots()
pz.Beta(2, 2).plot_pdf(ax=ax)
pz.Beta(2, 5).plot_pdf(ax=ax)
pz.Beta(5, 5).plot_pdf(ax=ax)
ax.set(xlabel="x", ylabel="density", title="Beta Distribution Comparison");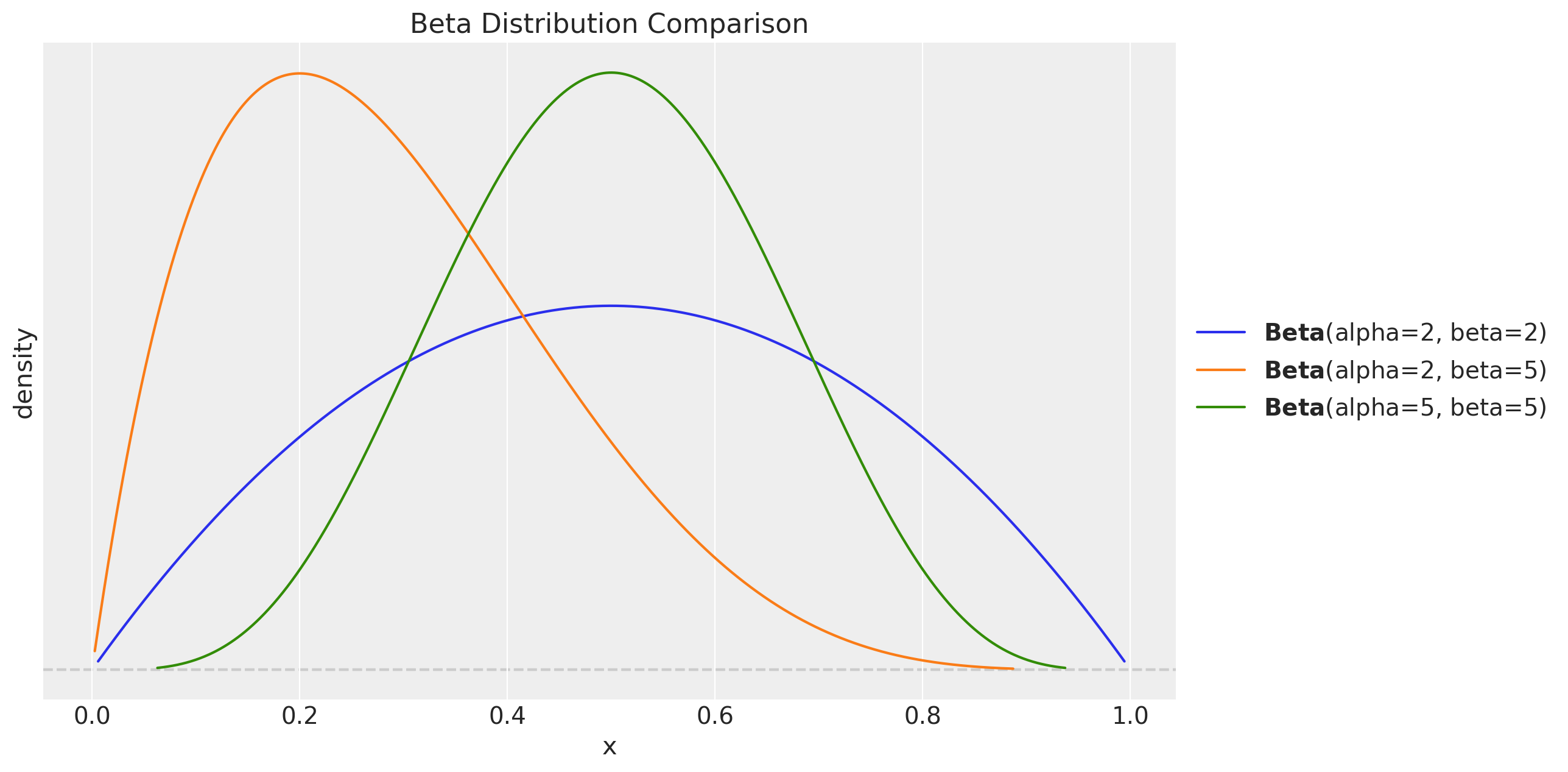
We now implement the SSOE form:
def damped_holt_winters_ssm_model(y: Array, n_seasons: int, future: int = 0) -> None:
# Get time series length
t_max = y.shape[0]
# --- Priors ---
## Level
level_smoothing = numpyro.sample("level_smoothing", dist.Beta(5, 5))
level_init = numpyro.sample("level_init", dist.Normal(y[0], 1))
## Trend (component-form beta*; in SSOE form beta = beta* * alpha)
trend_smoothing = numpyro.sample("trend_smoothing", dist.Beta(5, 5))
trend_init = numpyro.sample("trend_init", dist.Normal(0, 0.1))
## Seasonality (gamma* is the [0,1]-rescaling of component-form gamma
# in SSOE form gamma = gamma* * (1 - alpha))
seasonality_smoothing = numpyro.sample("seasonality_smoothing", dist.Beta(5, 5))
adj_seasonality_smoothing = seasonality_smoothing * (1 - level_smoothing)
## Damping
phi = numpyro.sample("phi", dist.Beta(2, 5))
with numpyro.plate("n_seasons", n_seasons):
seasonality_init = numpyro.sample("seasonality_init", dist.Normal(0, 1))
## Noise
noise = numpyro.sample("noise", dist.HalfNormal(0.5))
# --- Transition Function ---
def transition_fn(carry, t):
previous_level, previous_trend, previous_seasonality = carry
# Observation equation: y_t = l_{t-1} + φ b_{t-1} + s_{t-m} + ε_t
mu = previous_level + phi * previous_trend + previous_seasonality[0]
pred = numpyro.sample("pred", dist.Normal(loc=mu, scale=noise))
# SSOE innovation. During training pred is conditioned on y[t] so
# error = y[t] - mu is the one-step-ahead forecast error. During
# forecasting pred is sampled from N(mu, noise) so error ~ N(0, noise)
# and propagates through the state updates below.
error = pred - mu
# State updates (innovations form)
level = previous_level + phi * previous_trend + level_smoothing * error
trend = phi * previous_trend + trend_smoothing * level_smoothing * error
new_season = previous_seasonality[0] + adj_seasonality_smoothing * error
# Rotate the seasonal buffer so that index 0 always holds s_{t-m}.
seasonality = jnp.concatenate(
[previous_seasonality[1:], new_season[None]], axis=0
)
return (level, trend, seasonality), pred
# --- Run Scan ---
with numpyro.handlers.condition(data={"pred": y}):
_, preds = scan(
transition_fn,
(level_init, trend_init, seasonality_init),
jnp.arange(t_max + future),
)
# --- Forecast ---
if future > 0:
numpyro.deterministic("y_forecast", preds[-future:])Inference
We reuse the same helper functions as the original post.
class InferenceParams(BaseModel):
num_warmup: int = Field(2_000, ge=1)
num_samples: int = Field(2_000, ge=1)
num_chains: int = Field(4, ge=1)
def run_inference(
rng_key: Array,
model: Callable,
args: InferenceParams,
*model_args,
**nuts_kwargs,
) -> MCMC:
sampler = NUTS(model, **nuts_kwargs)
mcmc = MCMC(
sampler=sampler,
num_warmup=args.num_warmup,
num_samples=args.num_samples,
num_chains=args.num_chains,
)
mcmc.run(rng_key, *model_args)
return mcmcinference_params = InferenceParams()
rng_key, rng_subkey = random.split(key=rng_key)
damped_holt_winters_ssm_mcmc = run_inference(
rng_subkey,
damped_holt_winters_ssm_model,
inference_params,
y_train,
n_seasons,
target_accept_prob=0.8,
)Let’s look at the summary:
damped_holt_winters_ssm_idata = az.from_numpyro(posterior=damped_holt_winters_ssm_mcmc)
az.summary(data=damped_holt_winters_ssm_idata)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| level_init | 0.286 | 0.285 | -0.254 | 0.817 | 0.011 | 0.005 | 734.0 | 2066.0 | 1.0 |
| level_smoothing | 0.230 | 0.045 | 0.149 | 0.314 | 0.001 | 0.001 | 3401.0 | 3606.0 | 1.0 |
| noise | 0.233 | 0.013 | 0.209 | 0.257 | 0.000 | 0.000 | 3595.0 | 4465.0 | 1.0 |
| phi | 0.260 | 0.156 | 0.014 | 0.545 | 0.003 | 0.002 | 3305.0 | 3308.0 | 1.0 |
| seasonality_init[0] | 0.857 | 0.272 | 0.354 | 1.377 | 0.010 | 0.005 | 688.0 | 1824.0 | 1.0 |
| seasonality_init[1] | 0.766 | 0.272 | 0.246 | 1.273 | 0.010 | 0.005 | 694.0 | 1982.0 | 1.0 |
| seasonality_init[2] | 0.488 | 0.273 | -0.021 | 0.999 | 0.010 | 0.005 | 730.0 | 1837.0 | 1.0 |
| seasonality_init[3] | 0.092 | 0.272 | -0.404 | 0.612 | 0.010 | 0.005 | 754.0 | 1986.0 | 1.0 |
| seasonality_init[4] | -0.325 | 0.272 | -0.839 | 0.173 | 0.010 | 0.005 | 697.0 | 1772.0 | 1.0 |
| seasonality_init[5] | -0.718 | 0.272 | -1.217 | -0.201 | 0.010 | 0.005 | 719.0 | 1765.0 | 1.0 |
| seasonality_init[6] | -0.808 | 0.270 | -1.315 | -0.311 | 0.010 | 0.005 | 695.0 | 1919.0 | 1.0 |
| seasonality_init[7] | -1.111 | 0.272 | -1.627 | -0.596 | 0.010 | 0.005 | 691.0 | 1623.0 | 1.0 |
| seasonality_init[8] | -0.903 | 0.271 | -1.426 | -0.409 | 0.010 | 0.005 | 679.0 | 1865.0 | 1.0 |
| seasonality_init[9] | -0.819 | 0.272 | -1.324 | -0.303 | 0.010 | 0.005 | 693.0 | 2041.0 | 1.0 |
| seasonality_init[10] | -0.429 | 0.273 | -0.947 | 0.077 | 0.010 | 0.005 | 707.0 | 1615.0 | 1.0 |
| seasonality_init[11] | -0.015 | 0.273 | -0.526 | 0.483 | 0.011 | 0.005 | 671.0 | 1755.0 | 1.0 |
| seasonality_init[12] | 0.432 | 0.272 | -0.078 | 0.950 | 0.010 | 0.005 | 713.0 | 1963.0 | 1.0 |
| seasonality_init[13] | 0.715 | 0.270 | 0.220 | 1.229 | 0.010 | 0.005 | 697.0 | 1674.0 | 1.0 |
| seasonality_init[14] | 0.932 | 0.273 | 0.437 | 1.453 | 0.010 | 0.005 | 701.0 | 1680.0 | 1.0 |
| seasonality_smoothing | 0.242 | 0.076 | 0.113 | 0.391 | 0.001 | 0.001 | 2708.0 | 3865.0 | 1.0 |
| trend_init | -0.003 | 0.098 | -0.184 | 0.184 | 0.002 | 0.001 | 3961.0 | 4659.0 | 1.0 |
| trend_smoothing | 0.478 | 0.149 | 0.204 | 0.752 | 0.002 | 0.001 | 4276.0 | 4973.0 | 1.0 |
print(
f"""Divergences: {
damped_holt_winters_ssm_idata["sample_stats"]["diverging"].sum().item()
}"""
)Divergences: 0axes = az.plot_trace(
data=damped_holt_winters_ssm_idata,
compact=True,
kind="rank_bars",
backend_kwargs={"figsize": (12, 12), "layout": "constrained"},
)
plt.gcf().suptitle("Damped Holt-Winters (State Space) Trace", fontsize=16);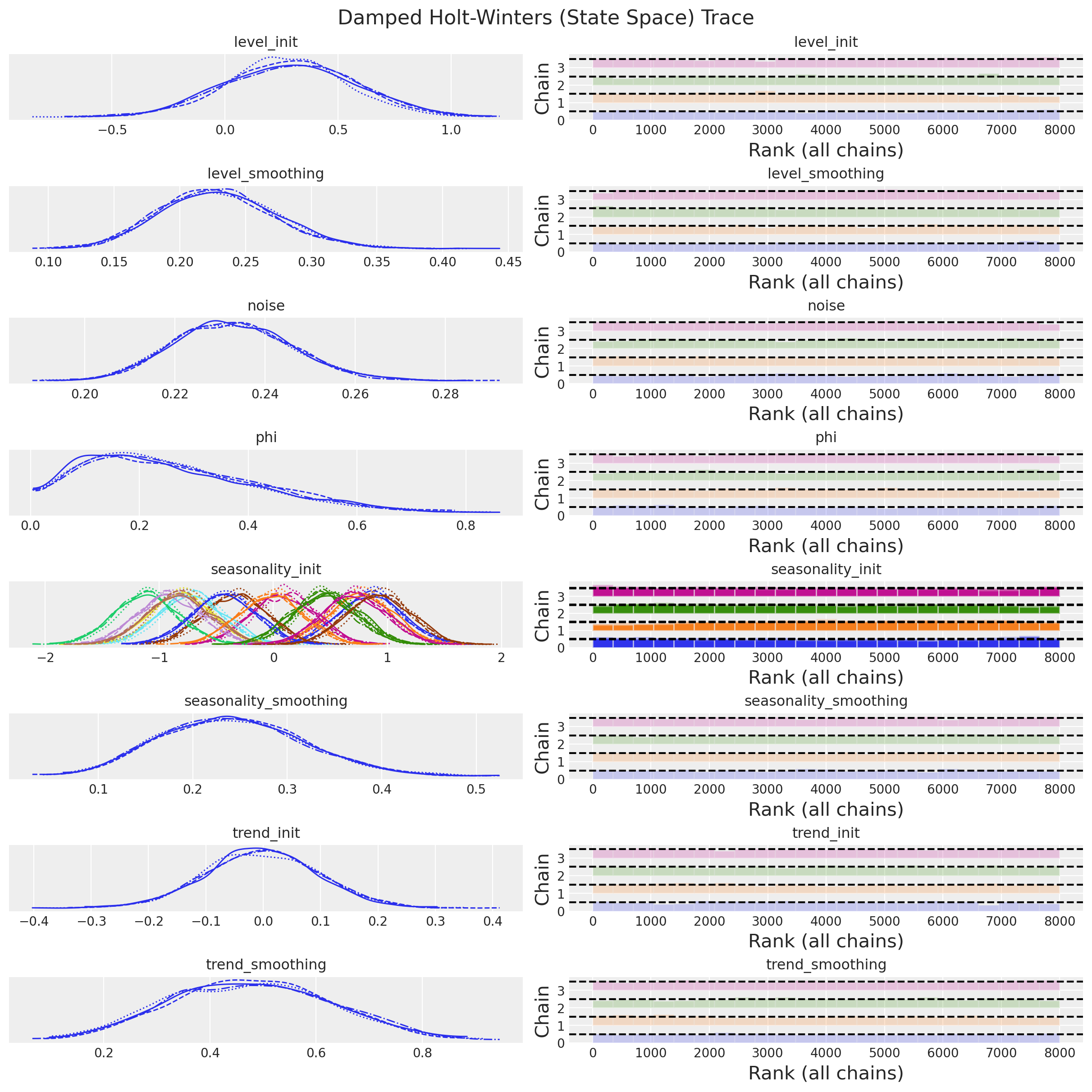
Everything looks good. We can now continue with the forecast,
Forecast
We use the same helper function as in the original post:
def forecast(
rng_key: Array, model: Callable, samples: dict[str, Array], *model_args
) -> dict[str, Array]:
predictive = Predictive(
model=model,
posterior_samples=samples,
return_sites=["y_forecast"],
)
return predictive(rng_key, *model_args)We now generate the posterior predictive samples for the forecast period:
rng_key, rng_subkey = random.split(key=rng_key)
damped_holt_winters_ssm_forecast = forecast(
rng_subkey,
damped_holt_winters_ssm_model,
damped_holt_winters_ssm_mcmc.get_samples(),
y_train,
n_seasons,
y_test.size,
)
damped_holt_winters_ssm_posterior_predictive = az.from_numpyro(
posterior_predictive=damped_holt_winters_ssm_forecast,
coords={"t": t_test},
dims={"y_forecast": ["t"]},
)
fig, ax = plt.subplots()
az.plot_hdi(
x=t_test,
y=damped_holt_winters_ssm_posterior_predictive["posterior_predictive"][
"y_forecast"
],
hdi_prob=0.94,
color="C2",
fill_kwargs={"alpha": 0.2, "label": r"$94\%$ HDI"},
ax=ax,
)
az.plot_hdi(
x=t_test,
y=damped_holt_winters_ssm_posterior_predictive["posterior_predictive"][
"y_forecast"
],
hdi_prob=0.50,
color="C2",
fill_kwargs={"alpha": 0.5, "label": r"$50\%$ HDI"},
ax=ax,
)
ax.plot(
t_test,
damped_holt_winters_ssm_posterior_predictive["posterior_predictive"][
"y_forecast"
].mean(dim=("chain", "draw")),
color="C2",
label="mean forecast",
)
ax.plot(t_train, y_train, color="C0", label="train")
ax.plot(t_test, y_test, color="C1", label="test")
ax.axvline(x=t_train[-1], c="black", linestyle="--")
ax.legend()
ax.set(
xlabel="time",
ylabel="y",
title="Damped Holt Winters Model Forecast (State Space Form)",
);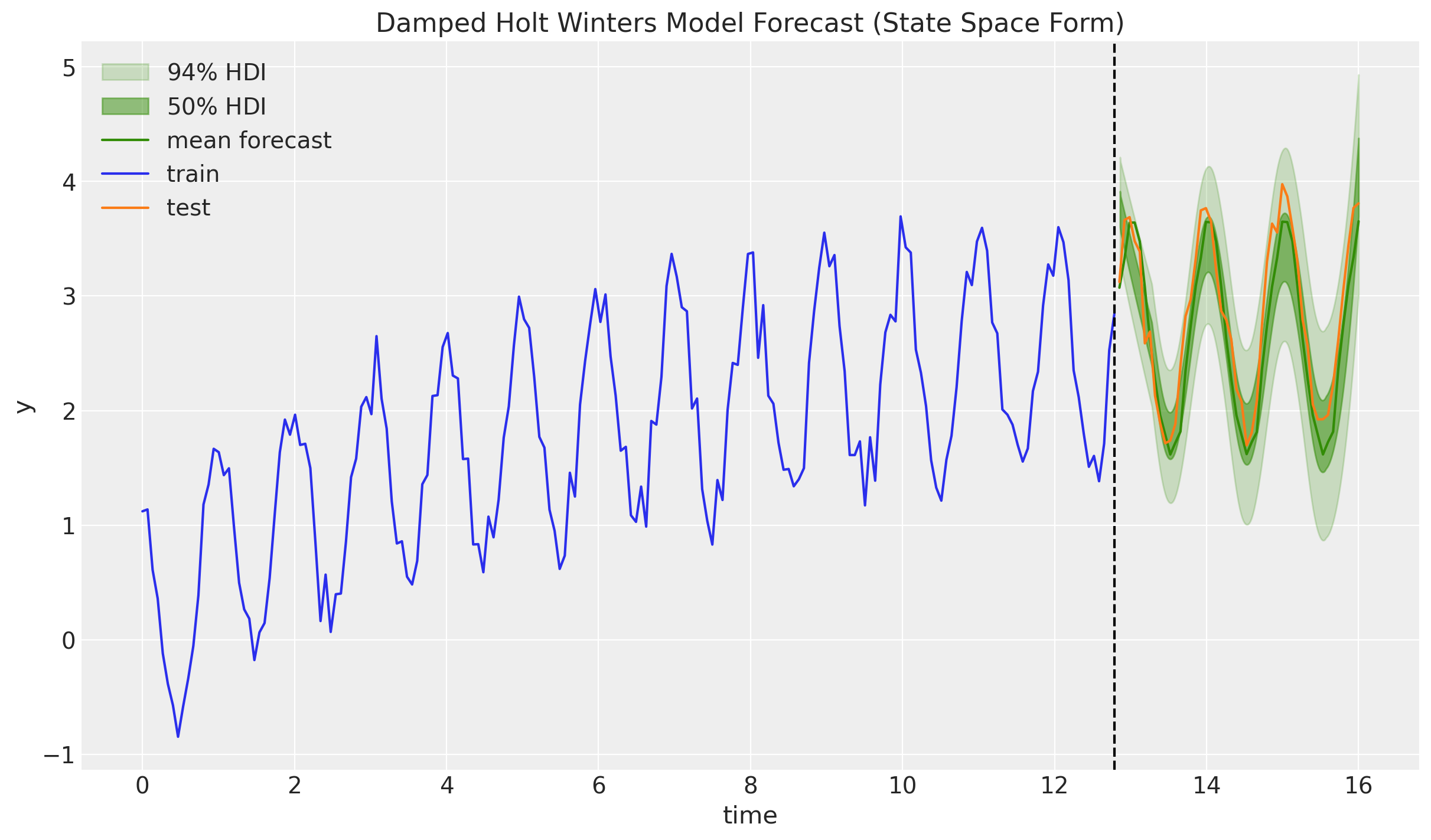
Compared to the component-form plot in the original post, the \(94\%\) and \(50\%\) HDIs now visibly fan out across the forecast horizon. The sampled innovation \(\varepsilon_t\) at each step feeds back into the level, trend and seasonal states, and the accumulated uncertainty produces a proper forecast cone. This is exactly the behaviour we should expect from a stochastic state space model, and it is what the component form was missing.
Two small caveats worth keeping in mind:
- The SSOE form assumes that the observation noise and the state-transition innovation are the same random variable. As noted in FPP3 §8.5, this is a fairly strong assumption, but it is the canonical one for the ETS family and gives the model a nice likelihood-based interpretation.
- We kept the component-form prior on the trend smoothing (\(\beta^\ast\)) and scaled it by \(\alpha\) at use time, because \(\beta^\ast\) has a clean interpretation on \([0, 1]\). This is not essential, a direct prior on the SSOE coefficient \(\beta\) would also work.
Thanks again to @theorashid for issue #193!