Causal Inference Through the Lens of Probabilistic Programming
PyCon DE & PyData 2026
Bayesian A/B Testing
A/B testing is the gold standard of causal inference: random assignment makes treatment independent of all confounders, observed and unobserved. The hard part shifts from identification to estimation under uncertainty.
with pm.Model() as non_informative_model:
conversion_rate_control = pm.Uniform(
"conversion_rate_control", lower=0, upper=1
)
conversion_rate_treatment = pm.Uniform(
"conversion_rate_treatment", lower=0, upper=1
)
relative_lift = pm.Deterministic(
"relative_lift",
conversion_rate_treatment / conversion_rate_control - 1,
)
\[\begin{align*} \text{cr}_\text{c} & \sim \text{Beta}(1, 1) \\ \text{cr}_\text{t} & \sim \text{Beta}(1, 1) \\ \text{lift} & = \text{cr}_\text{t} / \text{cr}_\text{c} - 1 \\ N_{\text{c}} & \sim \text{Binomial}(N, \text{cr}_\text{c}) \\ N_{\text{t}} & \sim \text{Binomial}(N, \text{cr}_\text{t}) \\ \end{align*}\]
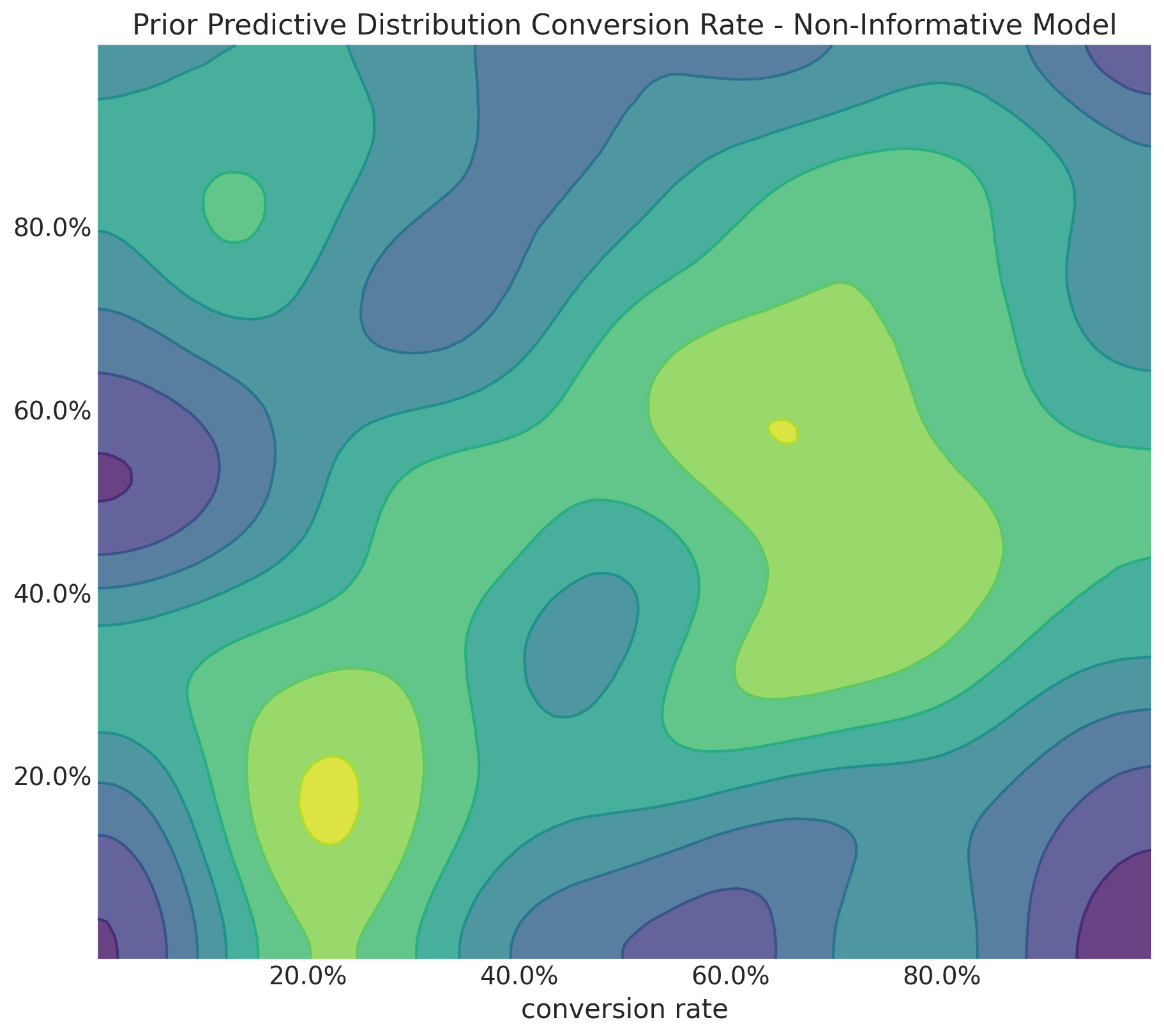
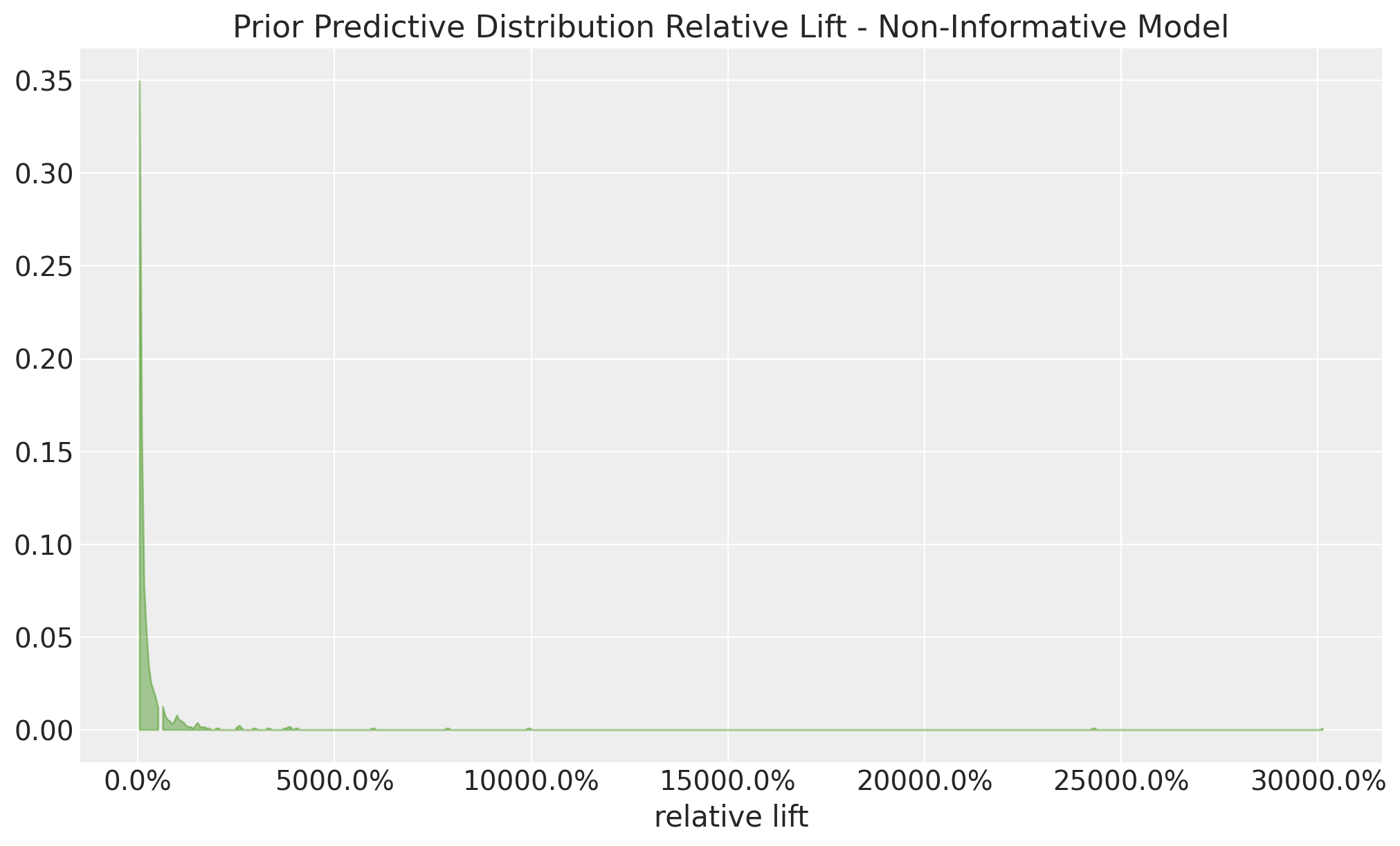
Uninformative Priors: Implications
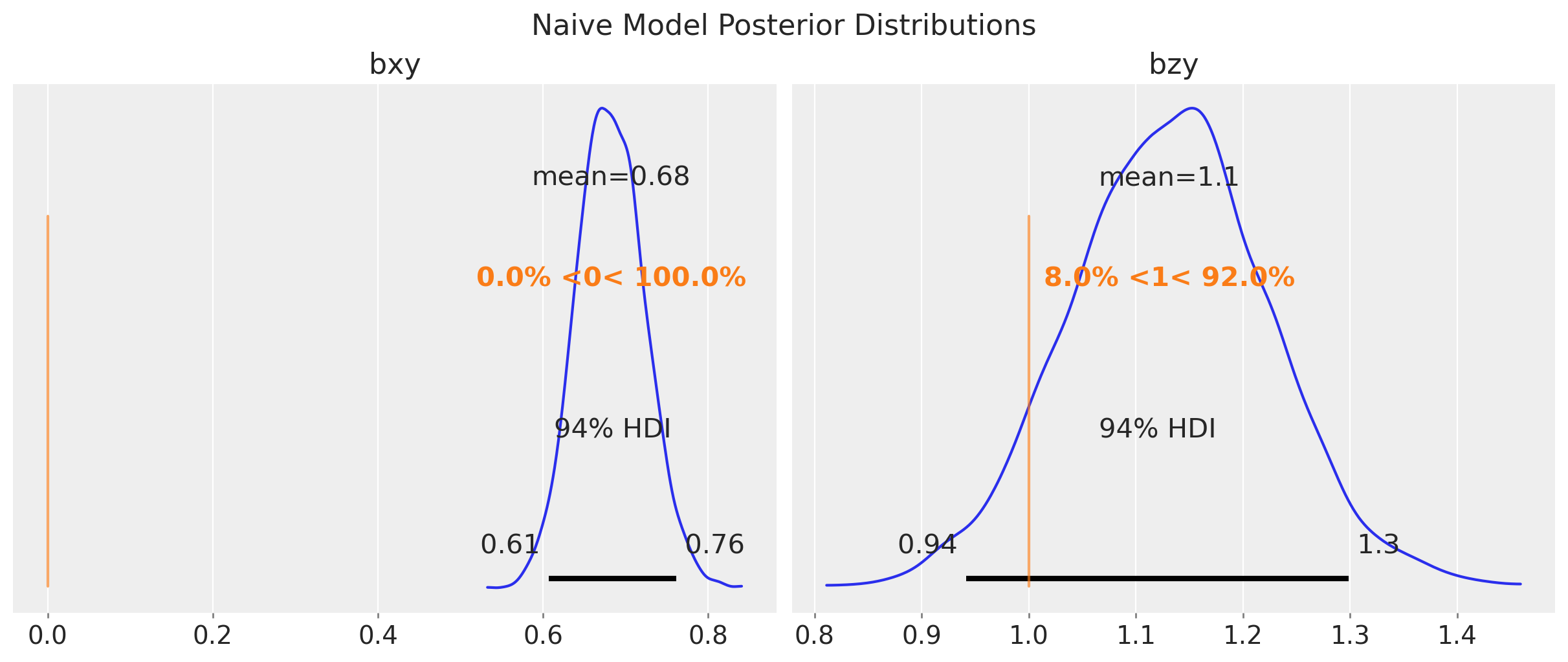
Uninformative Priors yield implausible values for the relative lift.
Setting uninformative priors for the conversion rates yields implausible values for the relative lifts as this is a ratio of two random variables, so it can blow up to infinity or zero.
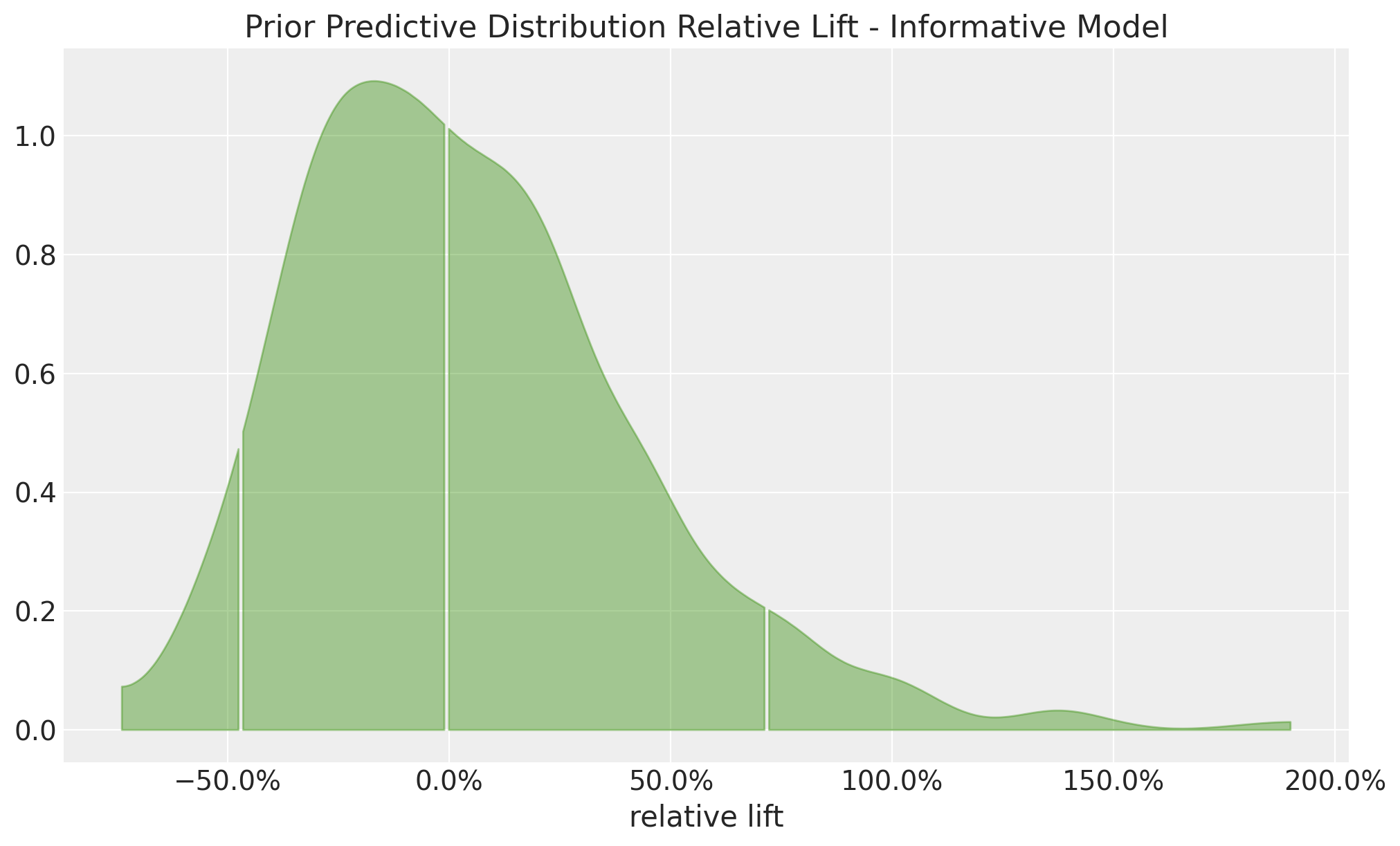
Informative Priors: Implications
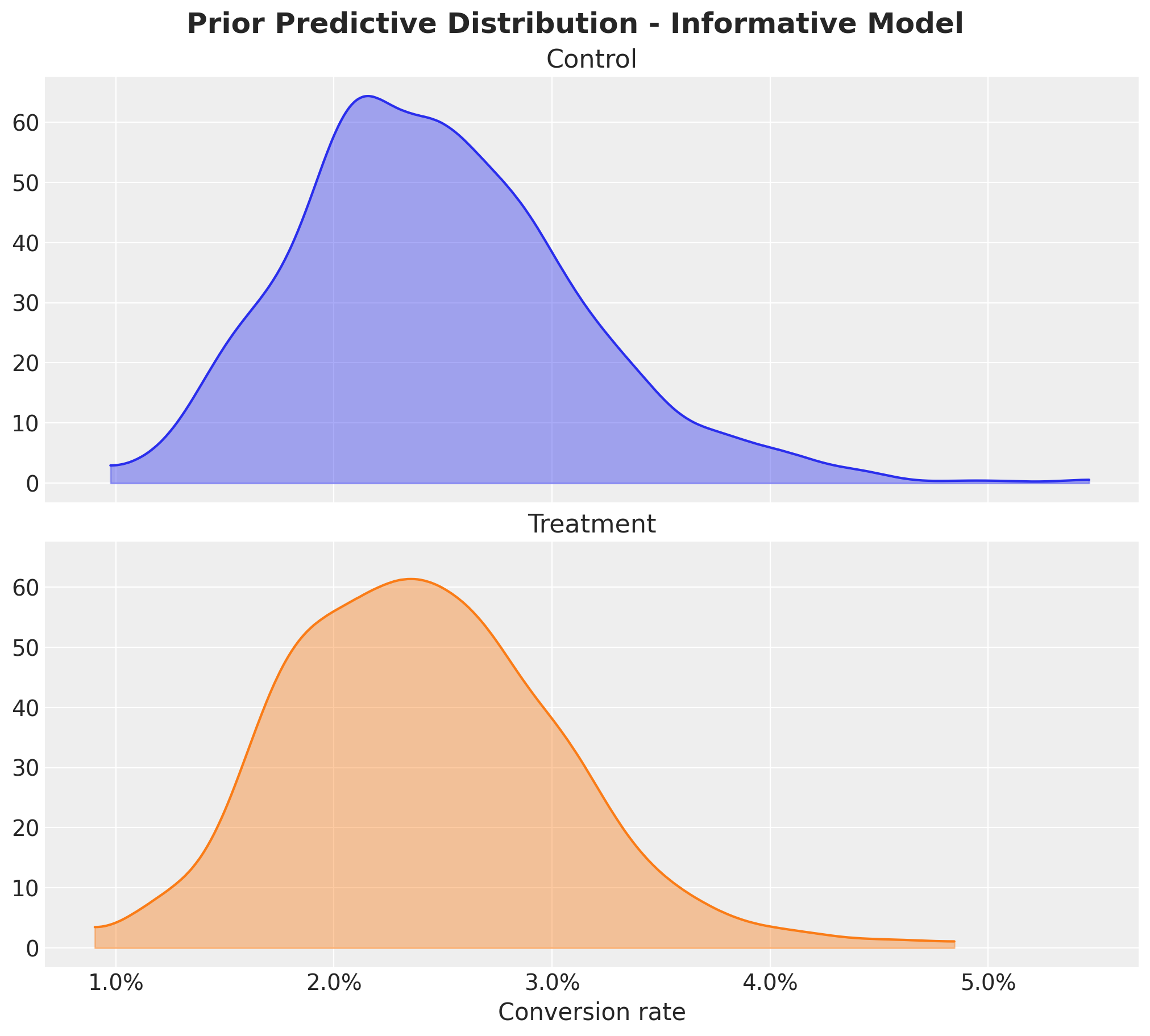
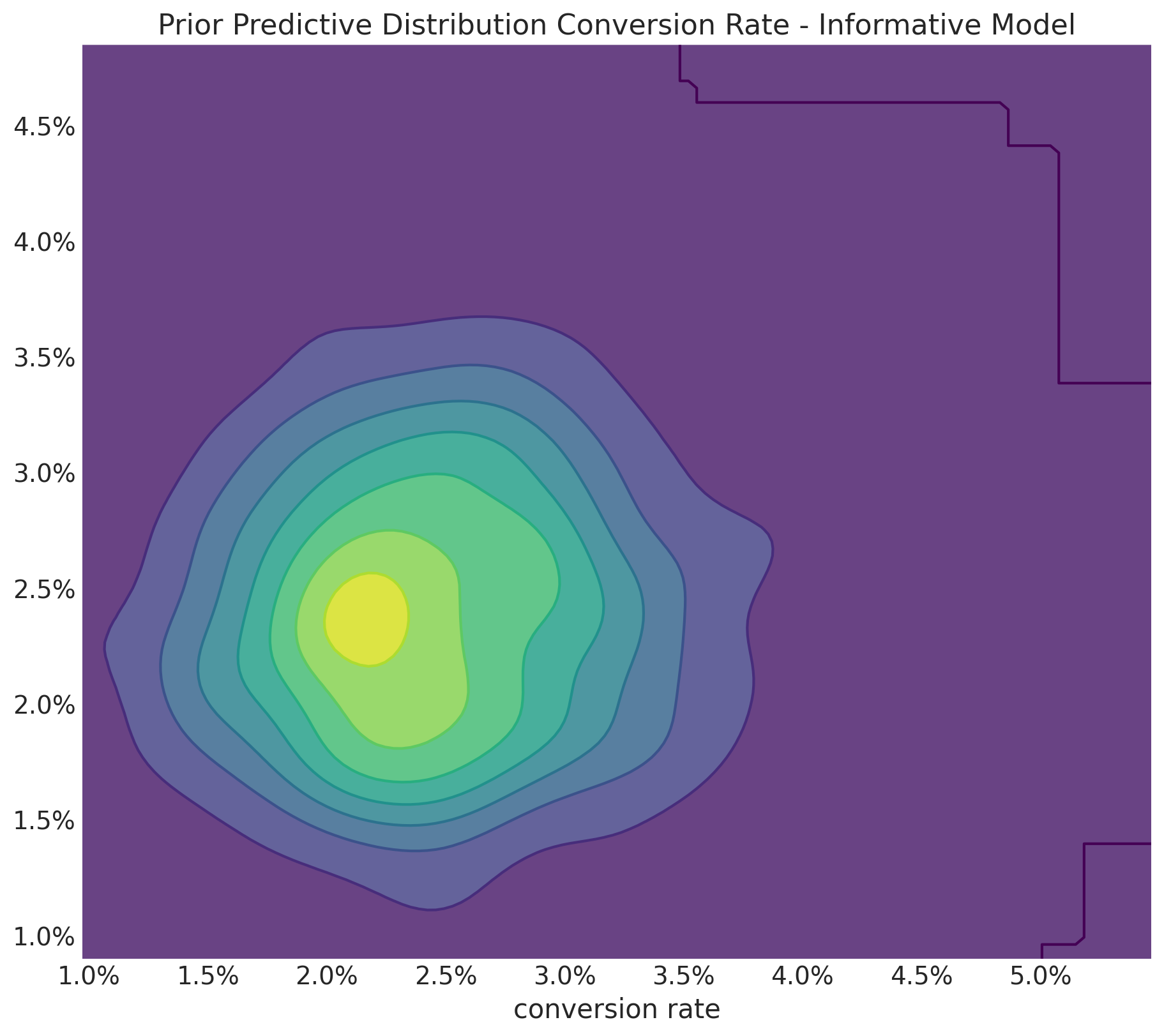
Informative Priors
Even if we set informative priors for the conversion rates, the relative lift range is still unreasonably wide.
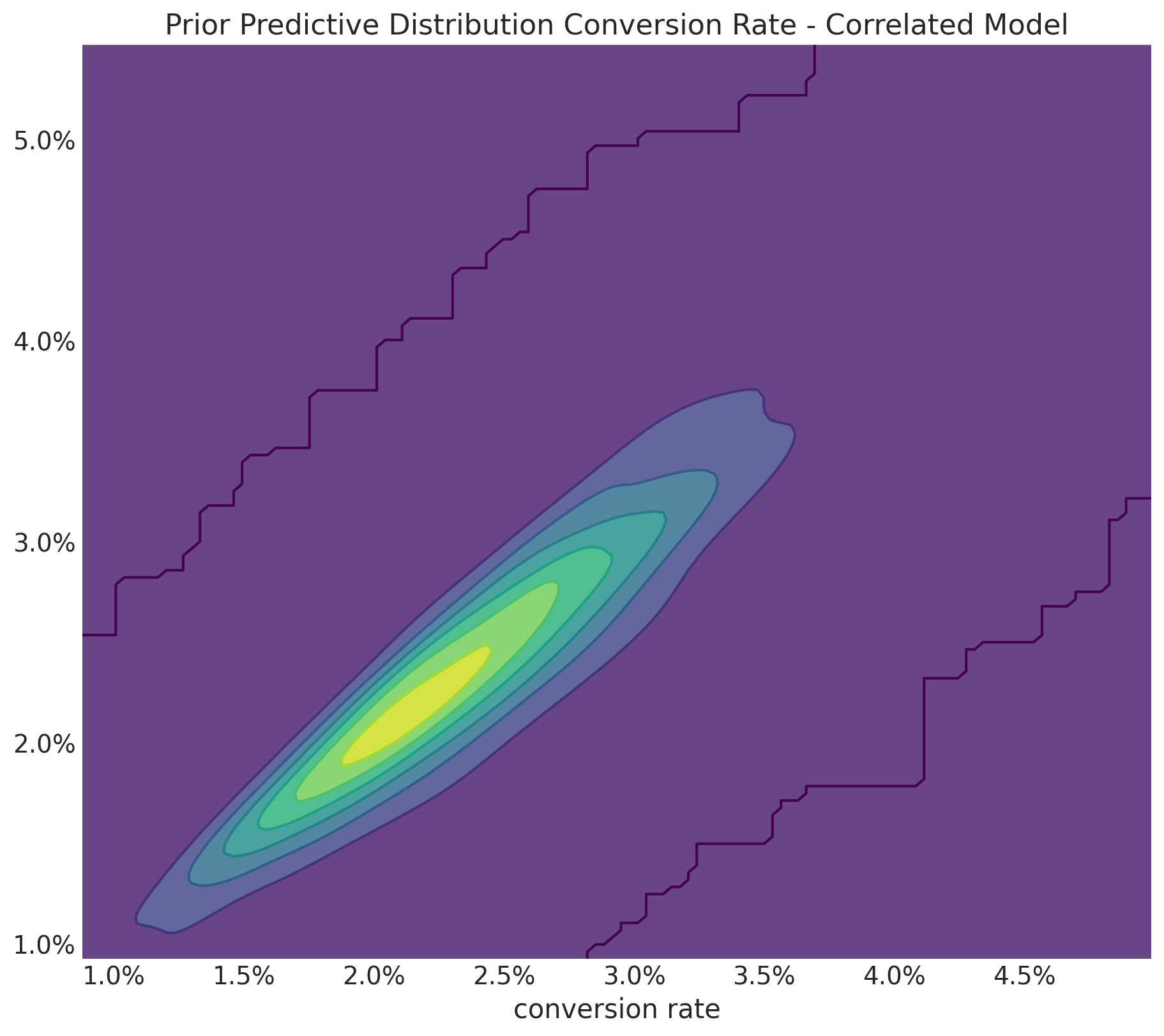
Correlated Priors: Implications
with pm.Model() as correlated_model:
conversion_rate_control = pm.Beta(
"conversion_rate_control", alpha=15, beta=600
)
relative_lift = pm.Normal(
"relative_lift", mu=0, sigma=0.1
)
conversion_rate_treatment = pm.Deterministic(
"conversion_rate_treatment",
conversion_rate_control * (1 + relative_lift)
)

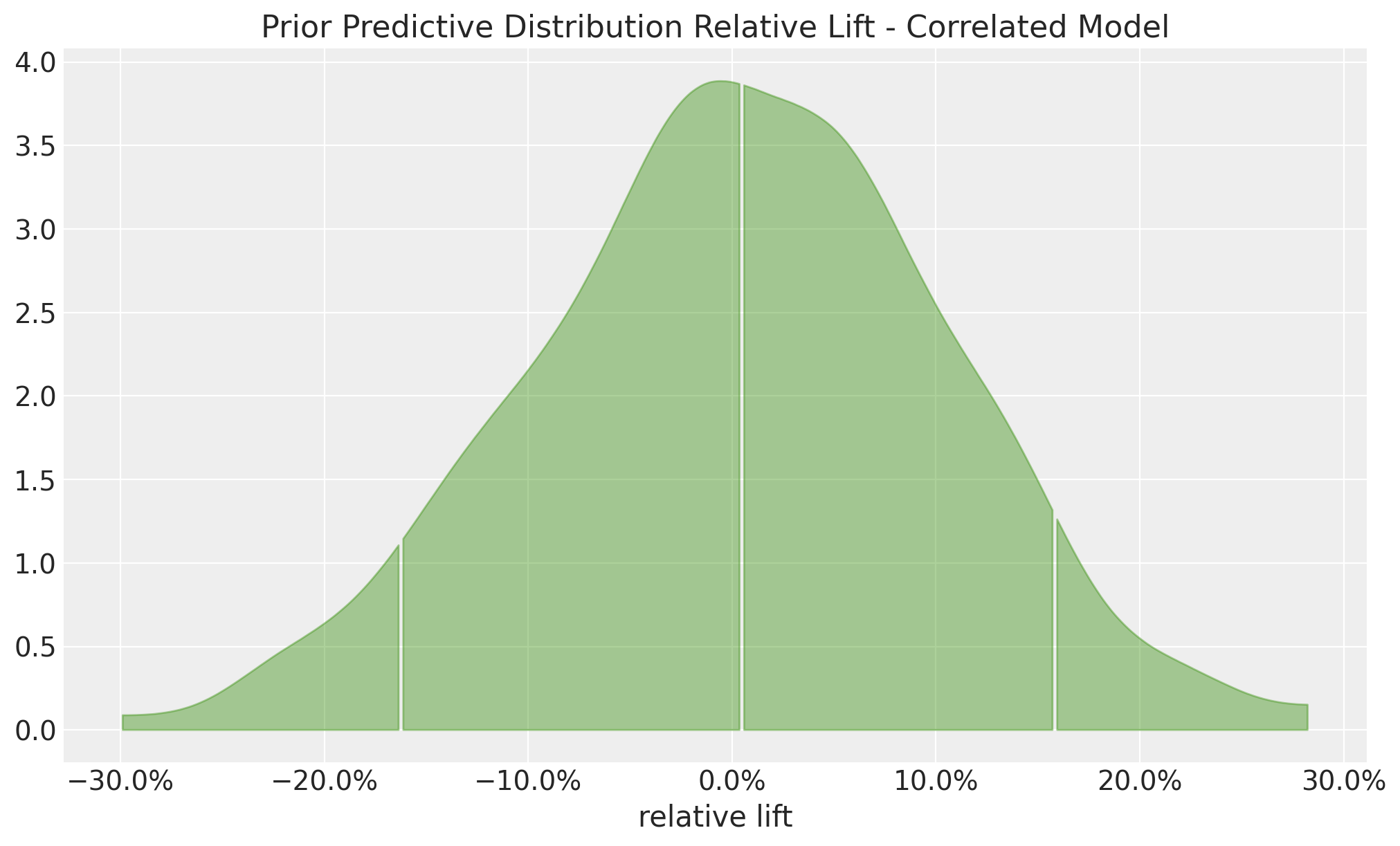
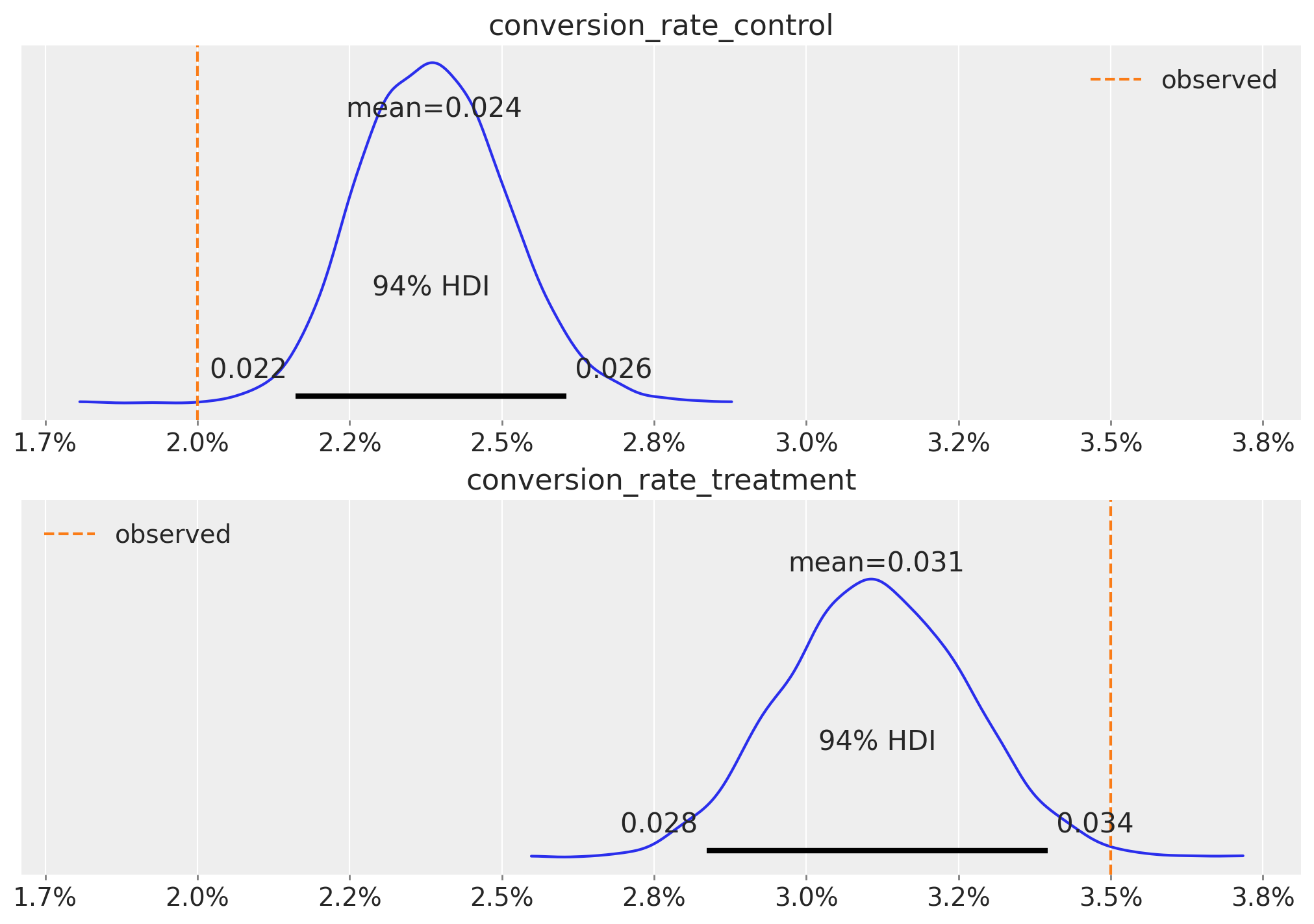
Inference with Correlated Priors

Bayesian Power Analysis
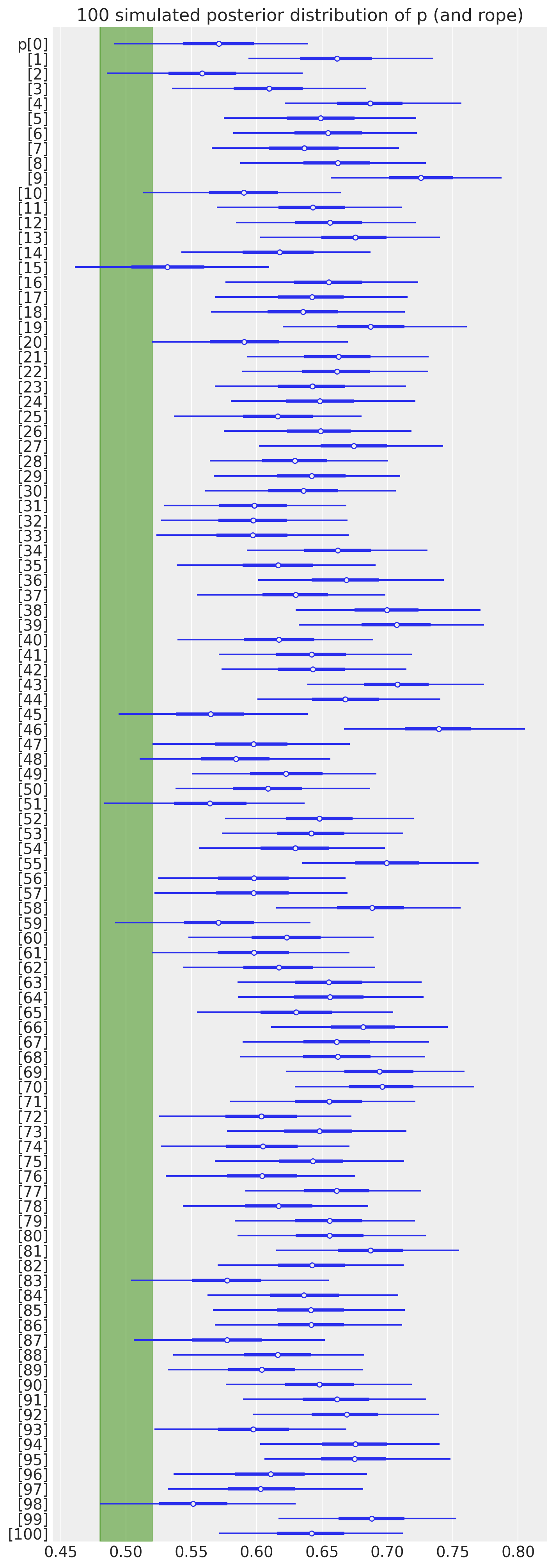
HDI + ROPE Framework
Declare significance when the \(94\%\) HDI of the posterior lift excludes the ROPE (Region of Practical Equivalence) around zero.
Five-step process:
- Generate parameter values from a hypothetical distribution
- Simulate data samples using the generative model
- Compute posterior estimates with Bayesian analysis for various sample sizes
- Assess whether the \(94\%\) HDI excludes the ROPE
- Repeat to approximate statistical power
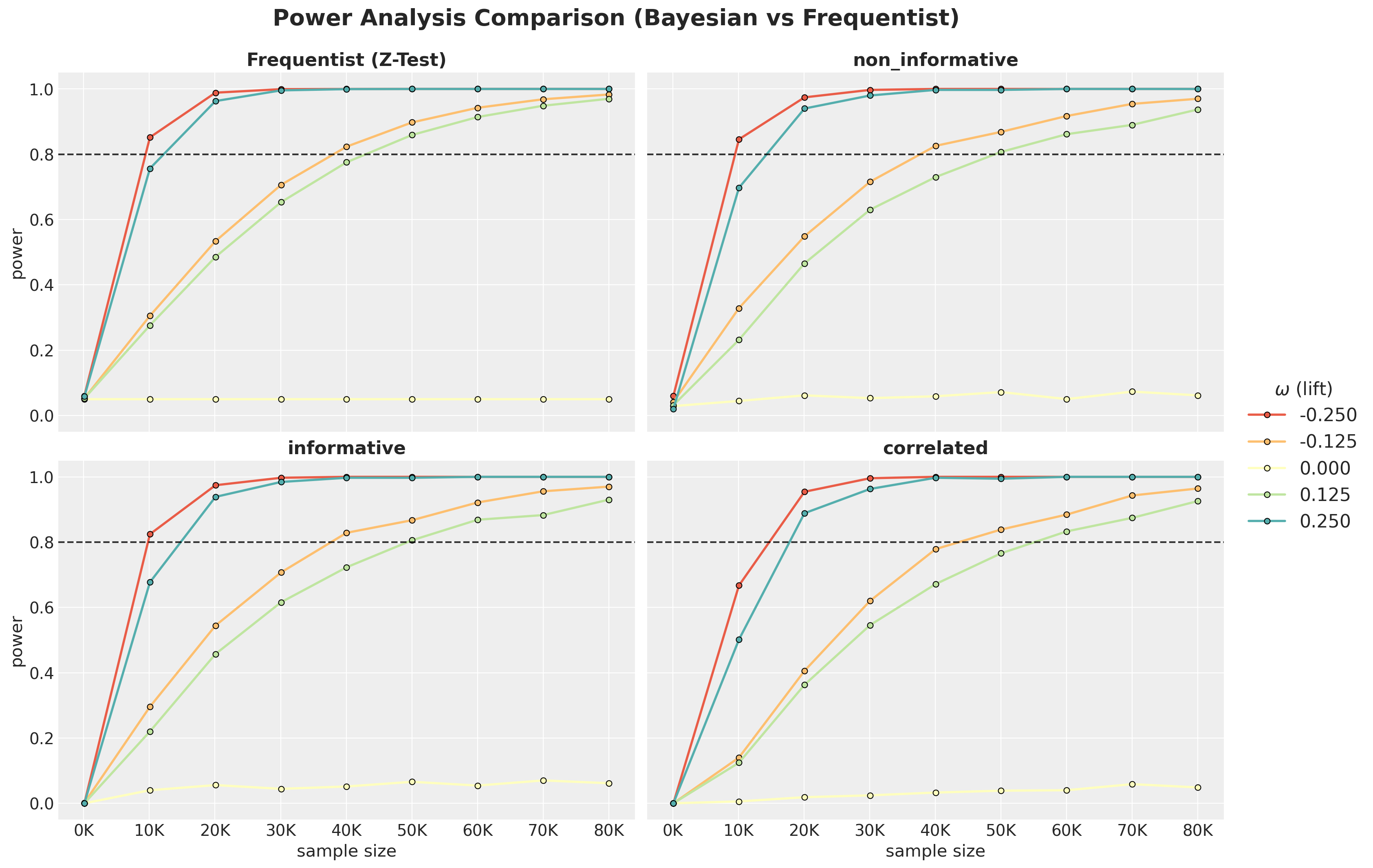
Power Curves
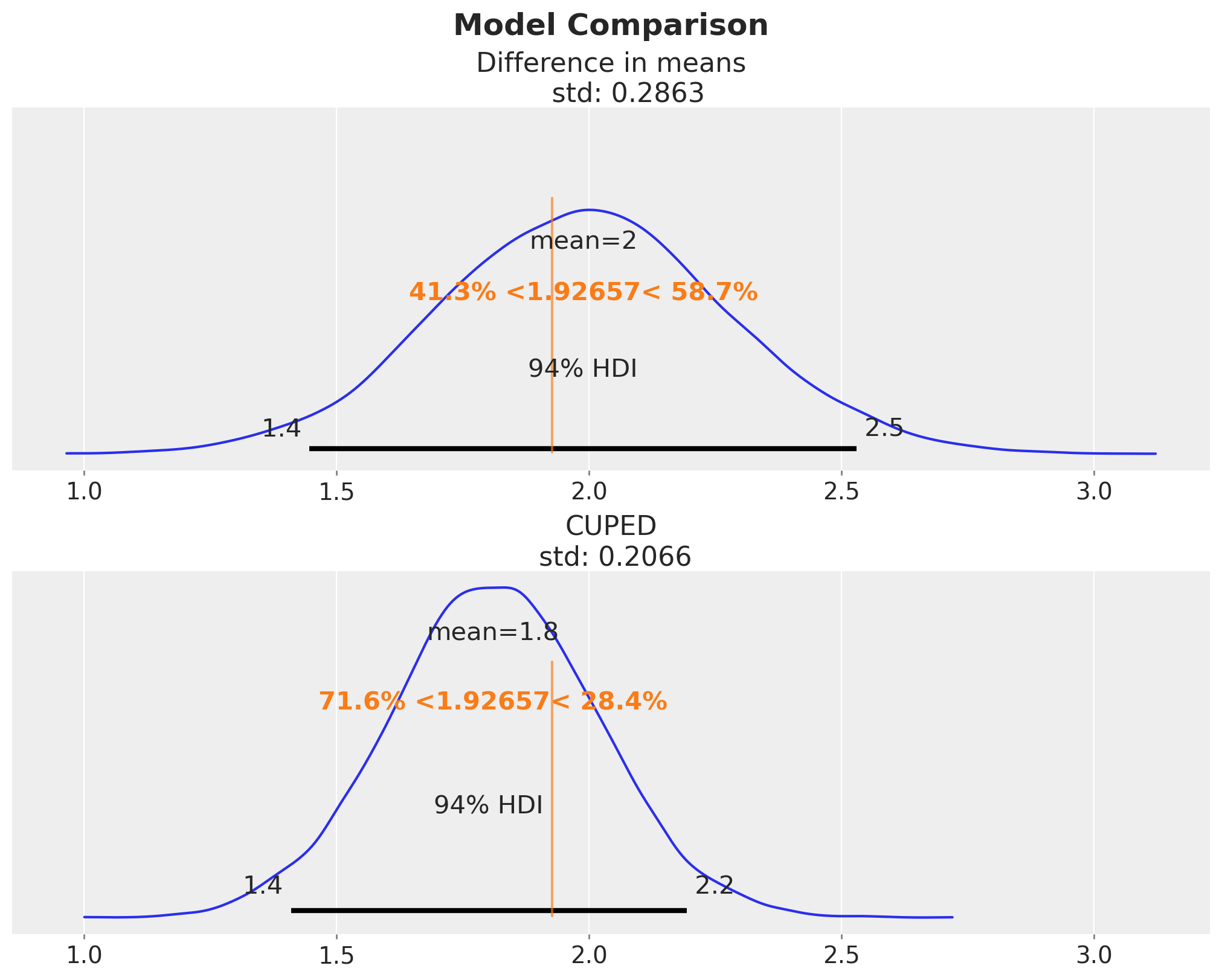
Bayesian CUPED

CUPED: Use pre-treatment outcome as a covariate to reduce posterior variance of the causal effect estimate.
Regress \(y_{\text{post}}\) on \(y_{\text{pre}}\) and estimate the \(\theta\) coefficient.
Compute \(y_{\text{cuped}, i} = y_{\text{post}, i} - \theta \, (y_{\text{pre}, i} - \bar{y}_{\text{pre}})\) for each unit \(i\).
Compute the difference in means of \(y_{\text{cuped}}\) between treatment and control group.
\[ y_{\text{cuped}} = \alpha + \beta_{\text{cuped}} \times \text{treatment} + \varepsilon \]
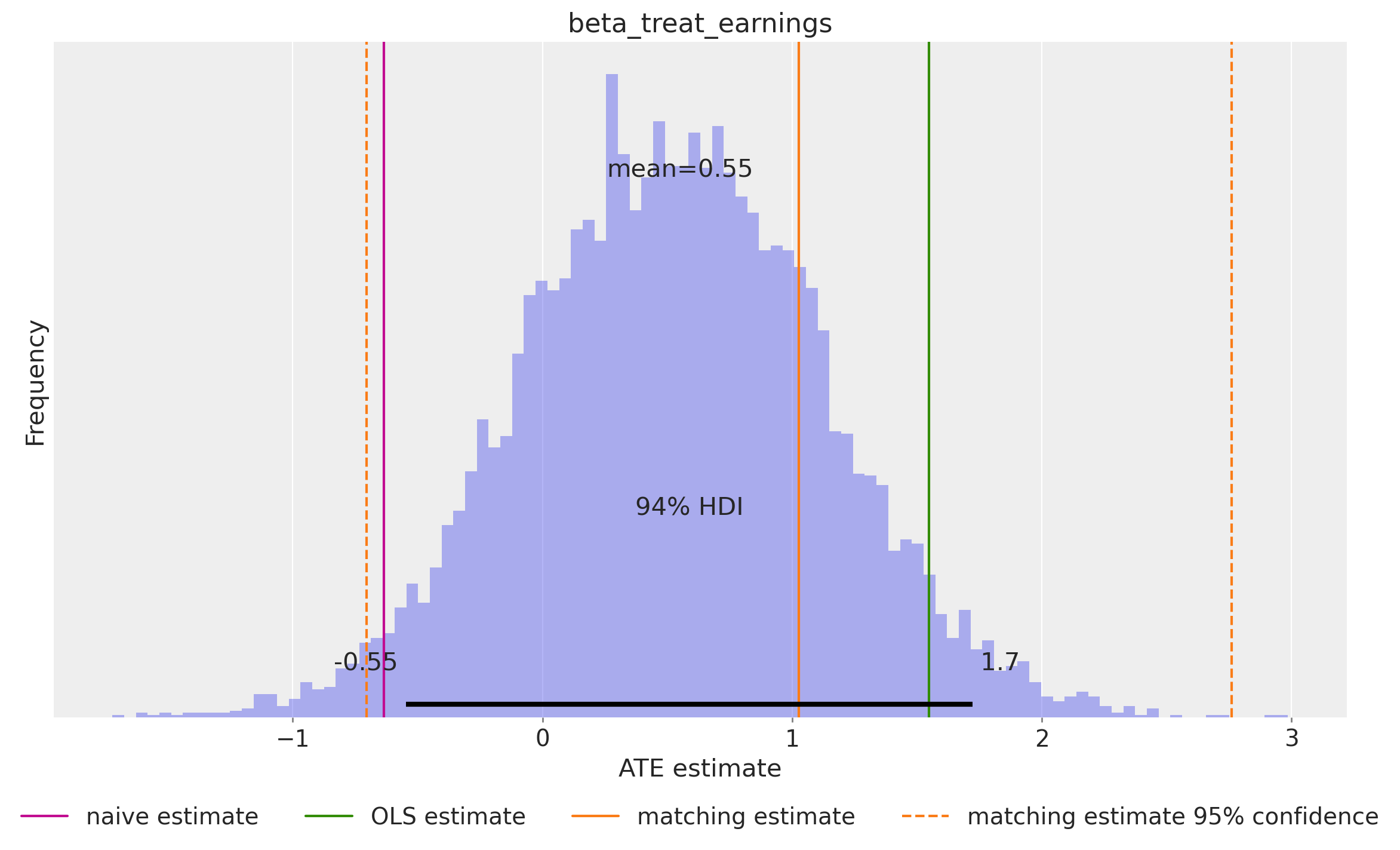
Confounders: An Example
The Lalonde Dataset: Job training program (National Supported Work, 1970s)
Question: Does job training increase earnings?
- Treatment: Participation in a job training program
- Outcome: Earnings in 1978 (
re78) - Covariates: Education, age, prior earnings (
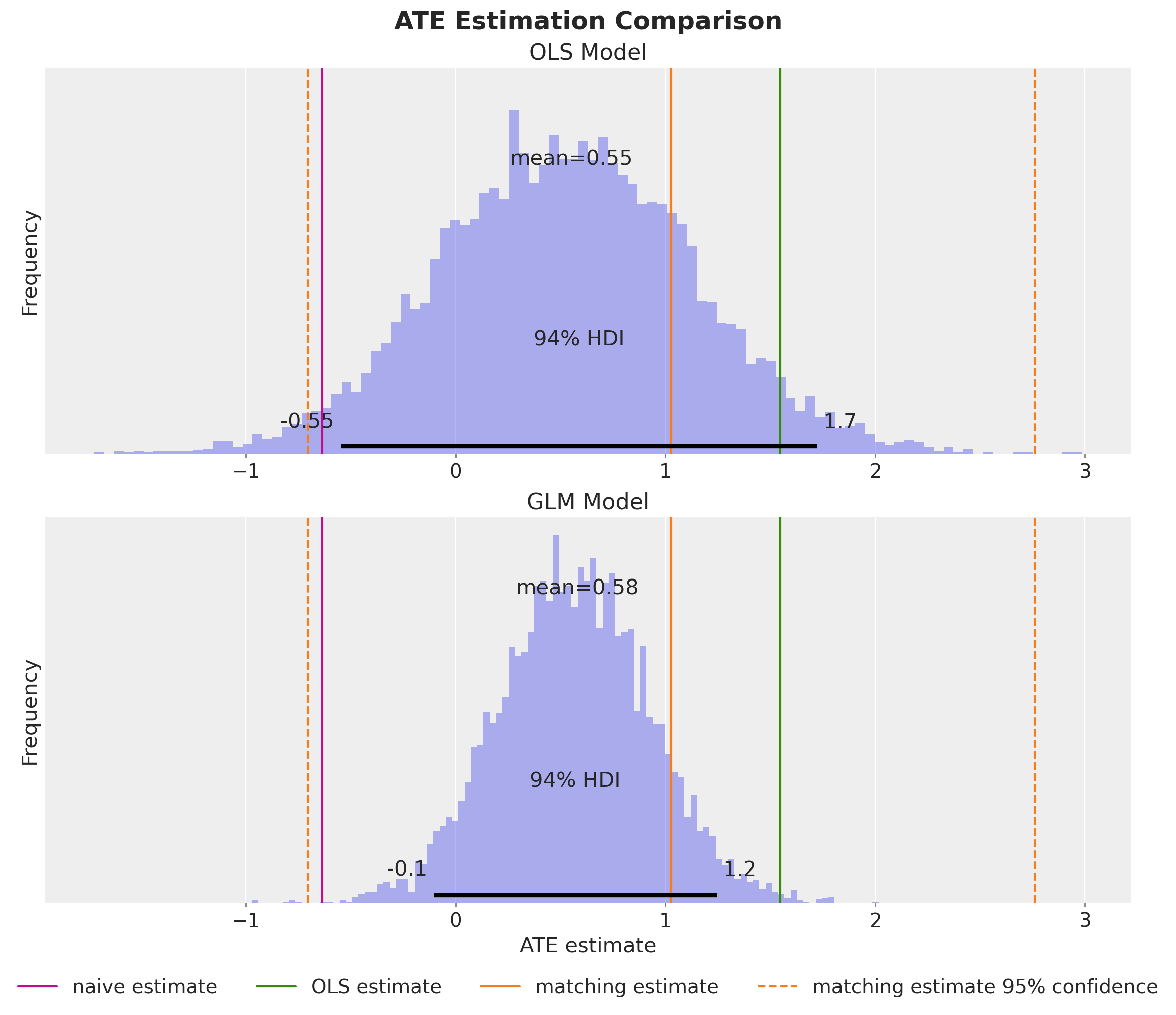
re75), race/ethnicity, marital status, degree - Naive comparison (difference in means): treated earned $635 less than untreated
- But treatment was not randomly assigned…
- Confounders create a spurious association!

The Causal DAG

Backdoor criterion: block all backdoor paths from treatment to outcome to identify the causal effect.
PyMC Model: Generative Process

Conditioning on Observed Data

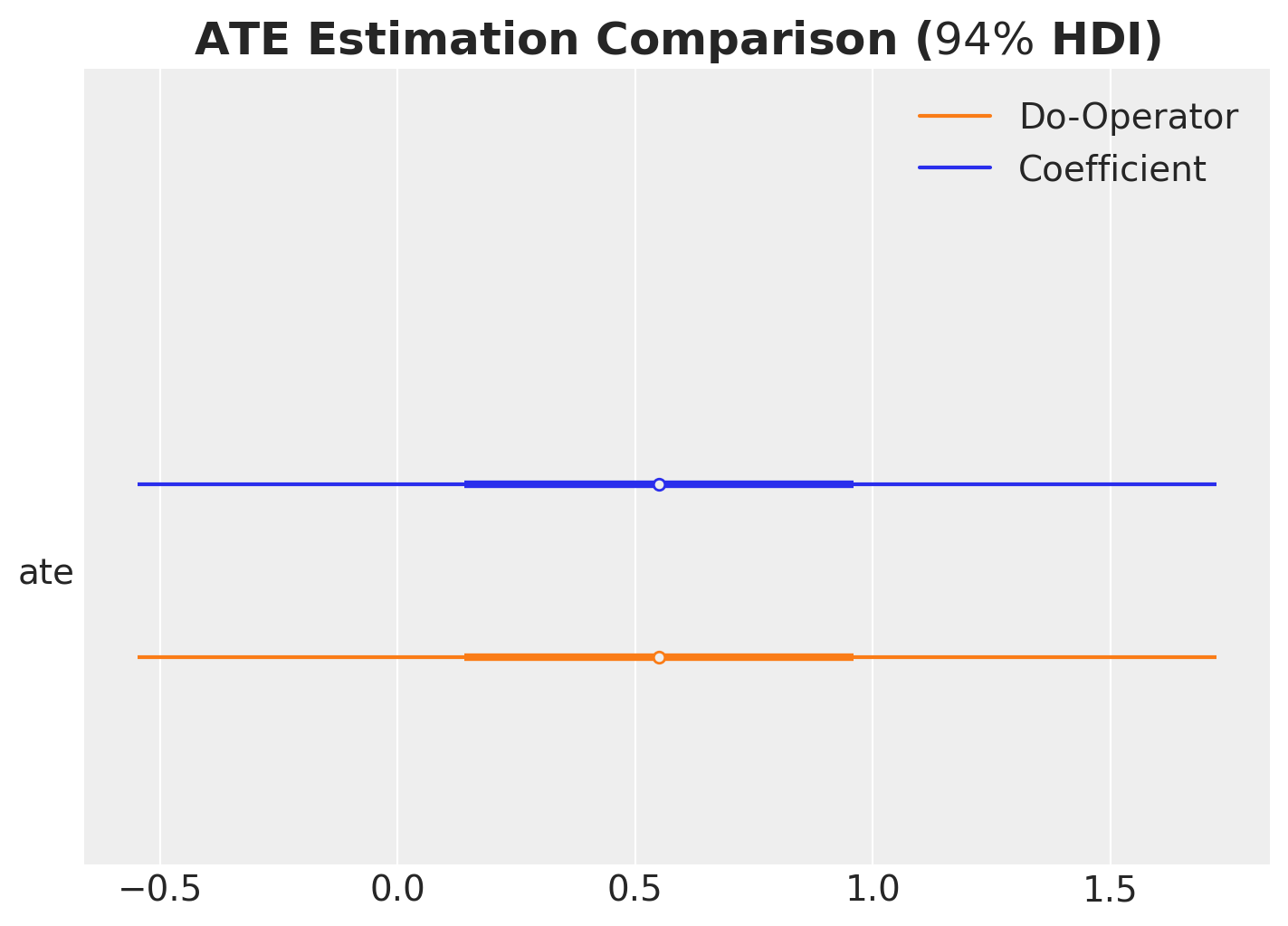
ATE from the Regression Coefficient
Do-Operator Resulting Model Graph

Individual Counterfactual Predictions
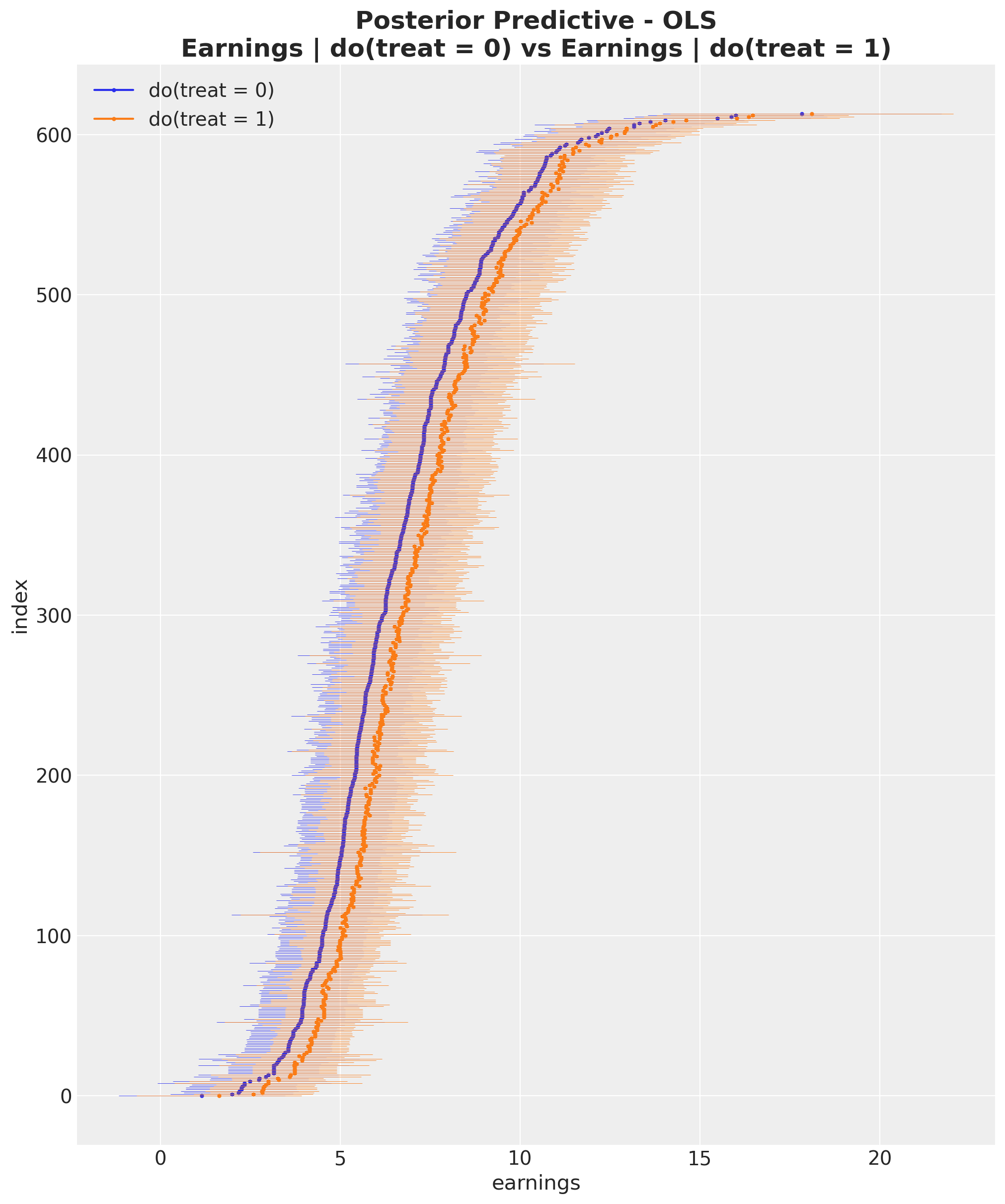
Computing the ATE using the do operator yields the same result as the regression coefficient approach.
A more meaningful likelihood
Gamma Generalized Linear Model
- Earnings are non-negative and right-skewed — Normal puts mass on impossible values.
- One-line model change:
pm.Normal(...)\(\to\)pm.Gamma(...)with a log link. - ATE on the original scale comes for free via the
do-operator.
Why the do-operator now matters: with a non-linear link, the regression coefficient is not the ATE. The do-operator handles non-linearity, individual counterfactuals, and joint interventions on multiple variables.
Fixed & Random Effects
Group-Level Confounding

Problem: Synthetic dataset where the true causal effect of \(X\) on \(Y\) is zero. We have group-level confounding through group-level effect \(U_G\).
Taken from Richard McElreath’s Statistical Rethinking (2026 Lectures).
Results: The Mundlak Latent Model
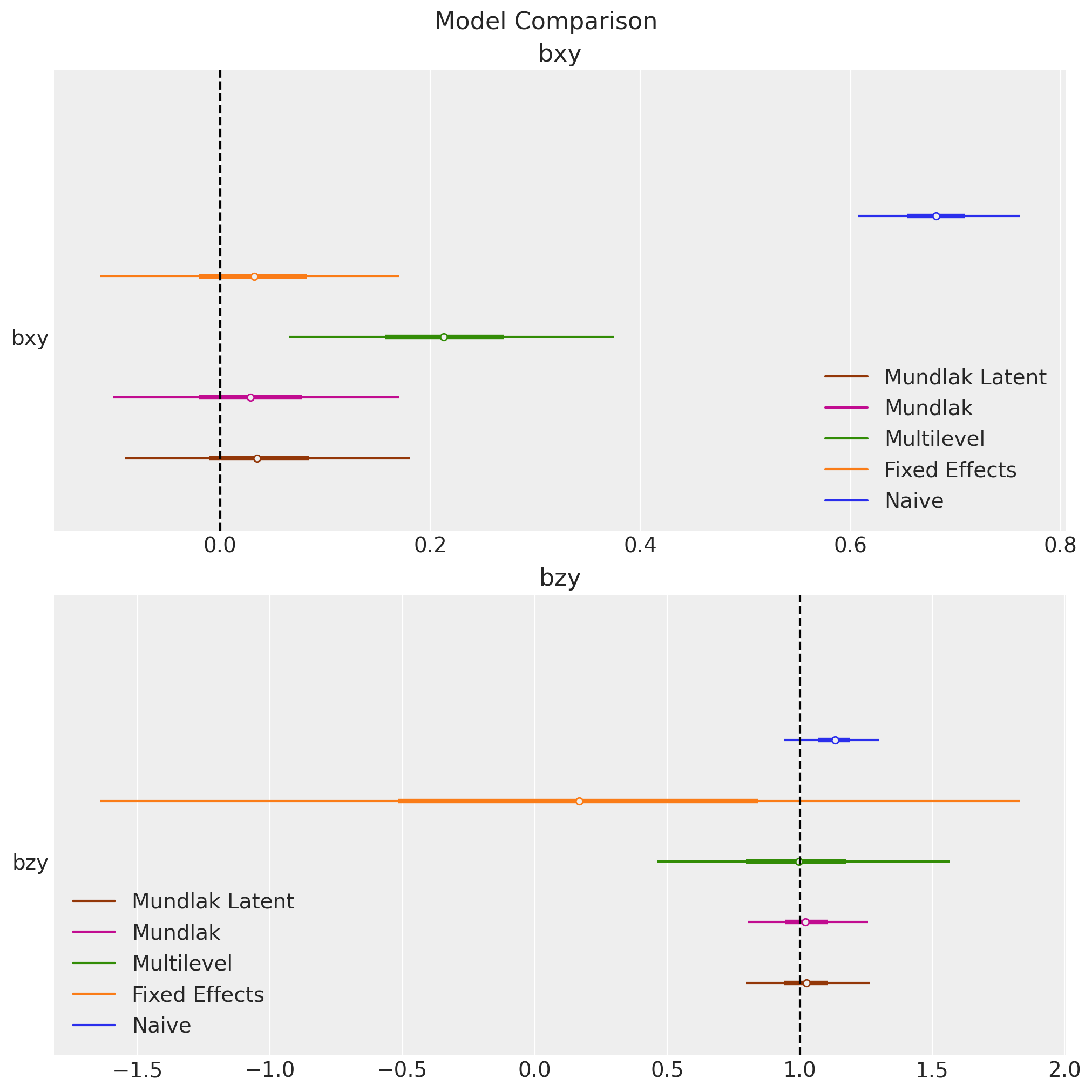
- Fixed effects
y ~ 0 + x + z + C(g)
- Multilevel
y ~ x + z + (1 | g)
- Mundlak
y ~ x + z + (1 | g) + x_bar
- Mundlak Latent
\[\begin{align*} \color{red}{u_{[g]}} & \sim \text{Normal}(\mu_u, \sigma_u) \\ x &= \alpha_x + \beta_{ux}{\color{red}{u_{[g]}}} + \varepsilon_x \\ y &= \alpha_{y, [g]} + \beta_{xy}x + \beta_{zy}z + \beta_{yg}{\color{red}{u_{[g]}}} + \varepsilon_y \end{align*}\]
:::
Latent Variable Modeling
Unobserved Confounders

- Online game dataset:
Does side-quest engagement increase in-game purchases? - Unobserved confounder \(Z\) (player motivation) affects both treatment and outcome.
- Standard backdoor adjustment is not possible.
- A solution: CEVAE framework (Louizos et al., NeurIPS 2017): learn a latent representation of \(Z\).
Taken from Robert O. Ness’s book: Causal AI.
CEVAE Architecture
Model = Decoder (generative process): Follows the causal ordering:
- \(Z\) (player motivation) \(\sim \text{Normal}(0, 1)\)
- Engagement (treatment) \(\sim \text{Bernoulli}(f_\theta(\text{guild membership}, Z))\)
- Purchases (outcome) \(\sim \text{Normal}(g_\theta(\text{won items}, \text{guild membership}, Z))\)
Guide = Encoder (recognition network): Flax (NNX) neural network that maps observed data \((\text{guild membership}, \text{engagement}, \text{purchases})\) to the approximate posterior \(q_\phi(Z \mid \cdot) = \text{Normal}(\mu_\phi, \sigma_\phi)\)
Inference: SVI maximizes the ELBO, jointly training the decoder parameters \(\theta\) and encoder parameters \(\phi\) (NumPyro)
Simulation Study
Here is a simpler parameter recovery study for the CEVAE: CATE Estimation with Causal Effect Variational Autoencoders
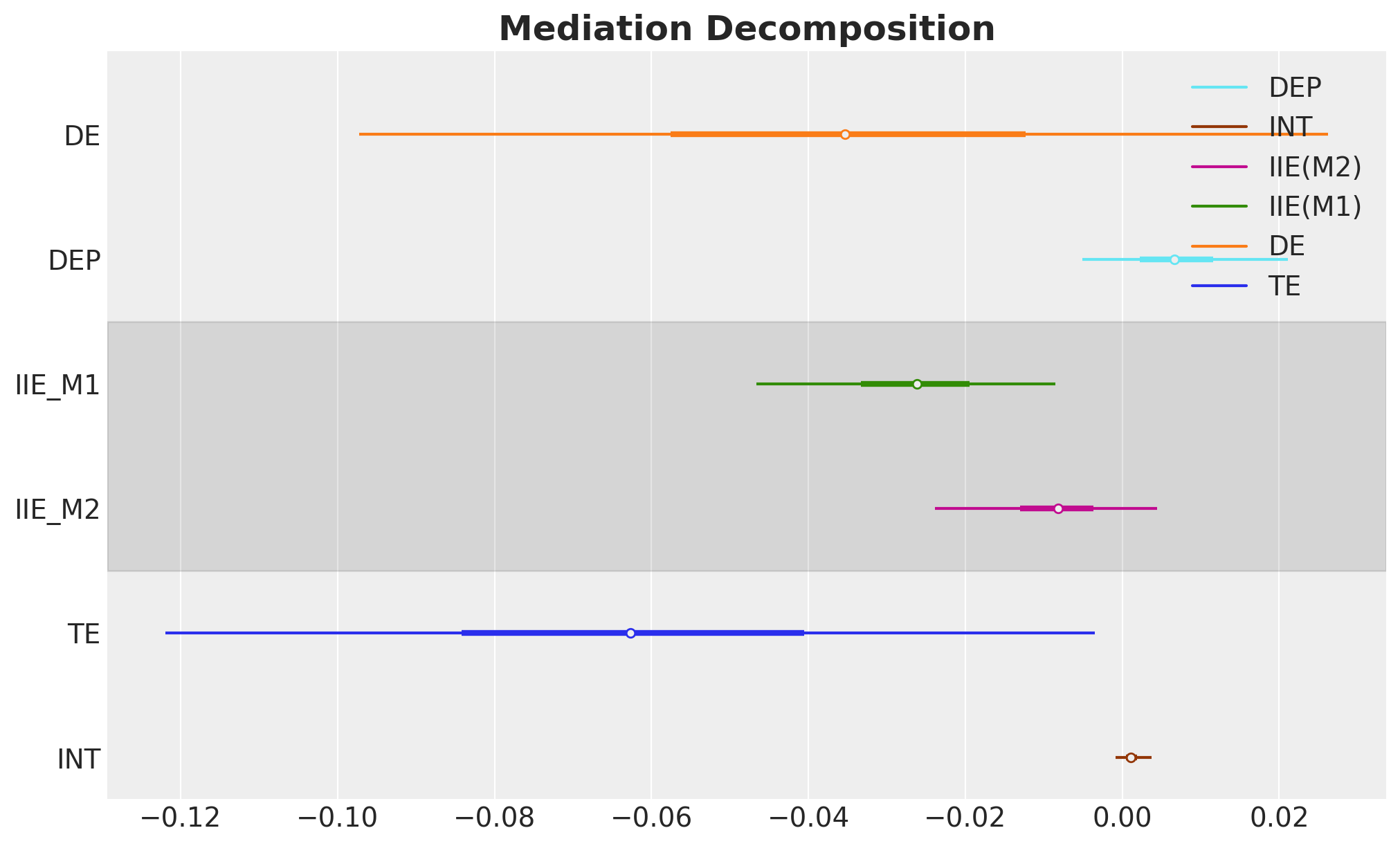
Mediation Analysis: (In)Direct Effects
Question: How does family intervention reduce substance use disorder? Decompose total effect into direct and indirect pathways.

- Synthetic dataset (\(N = 410\)) studying family intervention effects during adolescence.
- Covariates:
gender(binary),conflict(ordinal family conflict level). - Treatment:
fam_int(family intervention program, binary). - Two mediators:
dev_peer(deviant peer engagement),sub_exp(drug experimentation). - Outcome:
sub_disorder(substance use disorder diagnosis, binary).
Mediation Decomposition
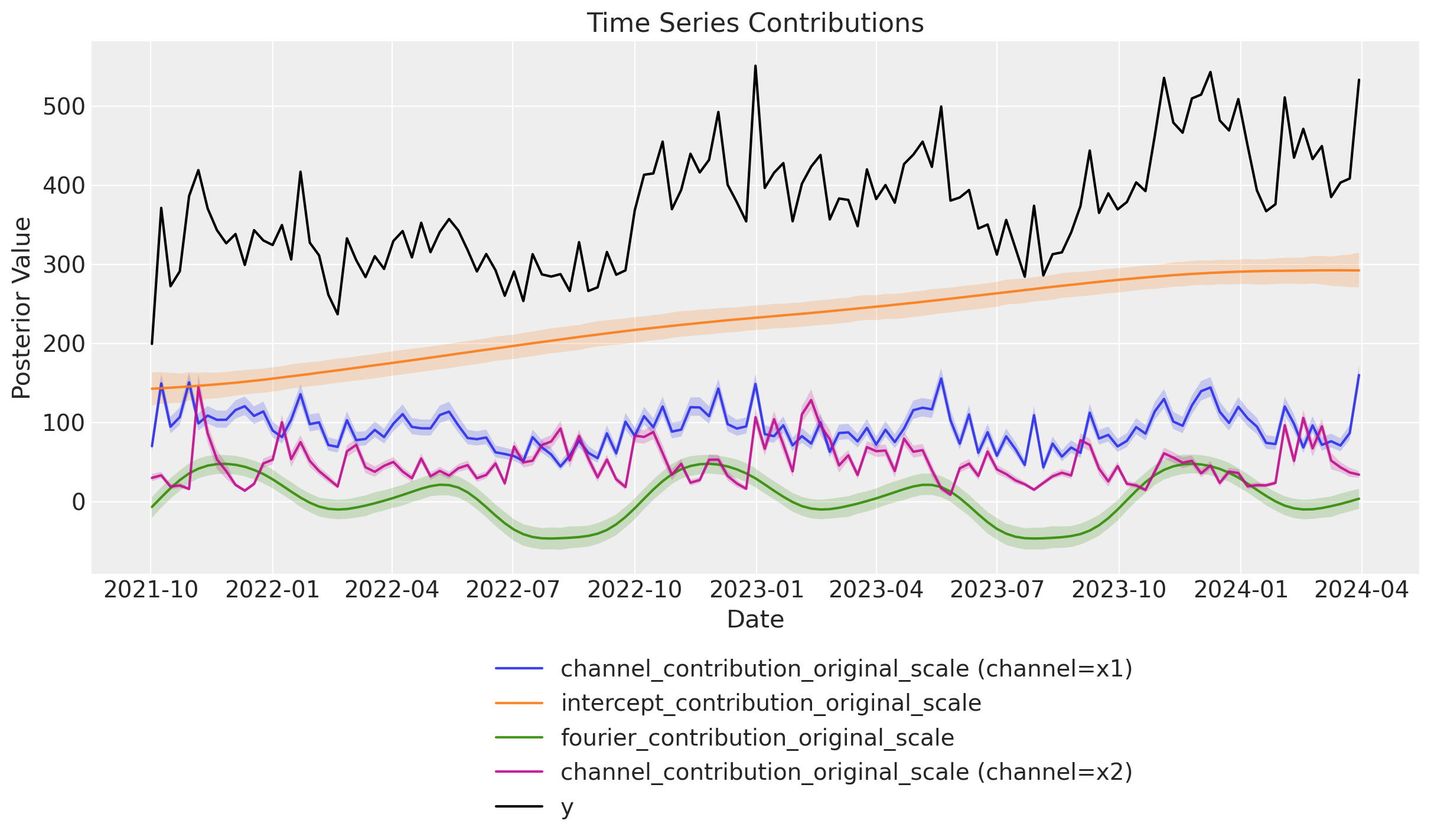
Application: Marketing Mix Modeling
Marketing Mix Modeling (MMM) is by nature a causal inference problem.
Question: How to optimally allocate the budget across channels to maximize the revenue in the next period?
We need to estimate marketing efficiency per channel (ROAS) to then optimize the budget allocation.
PyMC-Labs Ecosystem



Thank You!
juan.orduz@pymc-labs.com
